前言
在今天,训练一个高性能的大语言模型(LLM)究竟需要什么?
已有的研究论文让这一切看起来很简单:战略性的架构选择、精心策划的数据集以及充足的算力。得到的结果光鲜亮丽,消融实验结构清晰。事后看来,每一个决策都显而易见。但这些报告只展示了成功的经验,它们没有捕捉到凌晨两点调试数据加载器(dataloader)的漫长时刻、损失函数(loss)的异常峰值,或是那个悄悄破坏训练的细微张量并行(tensor parallelism)Bug(详见后文!)。现实往往更加杂乱、更加繁琐,大量的决策都没能写进最终的论文
跟随我们一起揭开 SmolLM3 训练的幕后故事。这是一个用了 11T tokens 训练的 3B 多语言推理模型。这不仅仅是一篇普通的博客文章,更像是在解开由决策、发现和死胡同交织而成的乱麻,这些经历为“如何构建世界级语言模型”提供了深刻的洞察。
这也是我们模型训练长篇系列的终章:我们已经探讨了大规模构建数据集(FineWeb)、编排数千个 GPU 协同工作(Ultra Scale Playbook),以及在流程的每一步选择最佳评估方案(Evaluation Guidebook)。现在,我们将这一切揉合在一起,构建一个强大的 AI 模型。我们将带你走过完整的旅程——不仅是最终成功的秘诀,还有那些塑造了每一个决策的失败经历、基础设施故障和调试过程。
这个故事读起来像一部戏剧:你会看到极具前景的小规模消融实验有时无法推广到大规模训练;看到我们为什么在训练 1T Token 后选择重启;看到我们如何在保持强大英语性能的同时,平衡多语言、数学和代码这些相互竞争的目标;以及最后,我们如何后期训练(post-train)一个混合推理模型。
我们也尽量避免枯燥地罗列工作内容,而是倾向于将我们的冒险经历组织成一个故事。你可以把这看作是一份指南,旨在帮助任何试图从“我们拥有优秀的数据集和 GPUs”过渡到“我们构建了一个非常强大的模型”的人。我们希望这种开放性能够缩小研究与生产之间的差距,并让你下一次的训练运行少一些混乱。
如何阅读这篇博客
你不需要从头到尾阅读这篇博客,而且事实上它现在太长了,很难一次性读完。博客被划分为几个不同的部分,可以跳着看,也可以单独阅读:
- 训练指南(Training compass): 首先必须要讨论的是你是否应该预训练自己的模型。为避免盲目开始耗尽你的VC资金,我们会带你思考一些基本问题,并教你如何系统地思考决策过程。这是一个偏向战略的章节,如果你想直接看技术内容,可以快速跳过这一部分。
- 预训练(Pretraining): 紧随训练指南之后的部分涵盖了构建稳定预训练方案所需的一切知识:如何运行消融实验、选择评估指标、混合数据源、选择架构、调整超参数,以及最终如何熬过漫长的训练马拉松。即使你不打算从头开始预训练,而是对持续预训练(continued pretraining,又称 mid-training)感兴趣,这一部分同样适用。
- 后训练(Post-training): 在这部分内容中,你将学习如何最大限度地发挥预训练模型的性能。我们将介绍从 SFT、DPO 到 GRPO 的全套后训练流程,以及模型合并(model merging)的“黑魔法”与炼金术。让这些算法发挥作用的大部分知识都源于痛苦的教训,我们将分享这些经验,希望能让你少走弯路。
- 基础设施(Infrastructure): 如果说预训练是蛋糕,后训练是奶油和顶部的樱桃,那么基础设施就是那台工业级的烤箱。没有它,一切都无从谈起;如果它坏了,你愉快的周末烘焙就会变成火灾隐患。关于理解、分析和调试 GPU 集群的知识散布在互联网的各种库、文档和论坛中。本节将详细讲解 GPU 布局、CPU/GPU/节点/存储之间的通信模式,以及如何识别并克服瓶颈。
那么,我们该从哪里开始呢?选择你觉得最激动人心的部分,让我们出发吧!
训练指南:why → what → how
机器学习领域对“优化”有着近乎执着的关系。我们沉迷于损失曲线、模型结构以及训练吞吐量——毕竟,机器学习的根本目标正是在于优化模型的损失函数。但在深入这些技术细节之前,更根本的一个问题往往被忽视了: 我们真的需要训练这个模型吗?
如下方的热力图所示,开源 AI 生态系统几乎每天都在发布世界级的模型:Qwen、Gemma、DeepSeek、Kimi、Llama 🪦、Olmo,这个名单每个月都在变长。这些不仅仅是研究原型或玩具示例:它们是生产级的模型,涵盖了从多语言理解到代码生成和推理的惊人广度。其中大多数都带有宽松的许可证,并有活跃的社区随时准备帮助你使用它们。
这就引出了一个令人不安的事实:也许你并不需要训练自己的模型。
这作为一份“LLM 训练指南”的开头似乎有些奇怪。但许多失败的训练项目并非败在糟糕的超参数或 Bug 频出的代码上,而是败在有人决定训练一个他们根本不需要的模型。因此,在你致力于训练并钻研how如何执行之前,你需要回答两个问题:why你为什么要训练这个模型?以及what你要训练什么样的模型?如果没有明确的答案,你将浪费数月的算力和工程时间去构建一个世界上已经存在的东西,甚至更糟——一个没人需要的东西。
让我们从“why”开始,因为如果不理解训练模型的目的,你就无法在后续的所有事情上做出连贯的决策。
本节与博客的其余部分不同:它较少涉及实验和技术细节, 更多关于战略规划。我们将引导你决定是否需要从头开始训练,以及要构建什么样的模型。 如果你已经深入思考过“why”和“what”, 可以随意跳到 伟大的模型都始于微小的消融实验 章节进行技术深挖。 但如果你还心存疑虑,在这里投入时间将为你以后节省大量的精力。
why:那个没人想回答的问题
让我们坦率地谈谈实际发生的情况。某人(如果运气好的话)获得了 GPU 集群的使用权,也许是通过研究资助,也许是通过公司的闲置容量,其思考过程大致如下:“我们有 100 张 H100,可以用三个月。让我们训练一个模型吧!”模型大小是随意选定的,数据集是从现有的任何资料中凑齐的。训练开始了。六个月后,在耗尽了算力预算和团队士气之后,得到的模型却被束之高阁,因为从来没有人问过why。
以下是一些你不应该训练模型的理由:
“我们训练了自己的模型”这种诱惑是巨大的,但在投入大量时间和资源之前,问一句“你为什么需要训练这个模型?”是有意义的。
下面的流程图引导了在启动大型预训练项目之前应该经历的思考过程。从技术角度来看,你基本上应该首先确认是否已经存在一个可以通过提示词(prompt)或微调(fine-tune)来完成工作的现有模型。
自定义预训练通常在以下三个领域具有意义:你想进行前沿研究、你有非常具体的生产用例需求,或者你想填补开源模型生态系统的空白。让我们快速浏览一下:
研究:你想了解什么?
在 LLM 领域有很多研究可以做。LLM 研究项目的共同点是,你通常从一个清晰定义的问题开始:
- 我们能否将这种新优化器的训练规模扩展到 10B+ 模型?来自 Muon is Scalable for LLM Training
- 仅靠强化学习(不带 SFT)能否产生推理能力?来自 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 我们能否仅在合成教科书数据上训练出优秀的小模型?来自 Textbooks Are All You Need
- 我们能否仅通过训练公开许可的数据来达到具有竞争力的性能?来自 The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
让假设尽可能具体,并思考必要的实验规模,可以增加成功的机会。
产出:为什么不能用现有的模型?
公司无法在其实际用例中使用现成模型的原因主要有三个。其中两个是技术性的,另一个是由于治理(governance)原因。
训练自己模型的第一个原因是领域专业性(domain specificity): 当你的数据或任务涉及现有模型无法很好处理的高度专业化的词汇或结构时。例如:
-
具有独特词汇量和长程依赖关系的 DNA 模型。
-
需要深入熟悉领域特定术语和逻辑的法律或金融模型。
第二个相关原因是部署限制:当你需要一个根据你的硬件、延迟或隐私要求量身定制的模型时。例如,运行在无人机或使用 FPGA 等定制硬件的本地系统上的 LLM。
这里有一个简单的测试:花几天时间基于 Qwen3, Gemma3 或其他当前的 SOTA 模型进行构建。你能通过提示词、工具调用(tool-use)或后训练达到你的性能目标吗?如果不能,那可能就是时候训练你自己的模型了。
即使满足你要求所需的后训练预算巨大,它可能仍然比从头开始便宜。对模型进行 1T tokens 的微调仍然比从头开始训练 10T+ tokens 更经济。
构建自有内部语言模型的第三个原因是安全与治理(safety and governance): 因为你处于受监管的行业或高风险应用中,你需要对训练数据、模型行为和更新周期拥有完全的控制权。你需要确切地知道模型中包含了什么,并能够向监管机构证明这一点。在某些情况下,除了构建自己的模型,你可能别无选择。
这些是公司训练内部模型的主要原因,那么那些发布开源模型的公司或组织呢?
战略性开源:你是否看到了可以填补的空白?
经验丰富的 AI 实验室发布新开源模型的最常见原因之一是:他们在开源生态系统中发现了一个特定的空白或新的 AI 用例。
这种模式通常如下:你注意到一个未被充分探索的领域,也许还没有具备超长上下文的强大端侧模型,或者虽然存在多语言模型但在低资源语言上表现很弱,又或者领域正朝着 Genie3 等交互式世界模型发展,而目前还没有优秀的开源权重模型。
你有理由相信自己可以做得更好;也许你策划了更好的训练数据,开发了更好的训练方案,或者有算力在别人无法做到的地方进行过度训练(overtrain)。你的目标是具体的:不是“有史以来最好的模型”,而是“最适合端侧使用的 3B 模型”或“第一个具备 1M 上下文的小模型”。
这是一个真实的目标,如果成功会创造价值:开发者采用你的模型,它成为他人的基础设施,或者它建立了技术公信力。但成功需要经验。你需要知道什么是实际可行的,以及如何在竞争激烈的空间中可靠地执行。为了让这一点更具体,让我们看看 Hugging Face 是如何思考这个问题的。
Hugging Face 的旅程
那么,为什么 Hugging Face 要训练开源模型呢?答案很简单:我们构建对开源生态系统有用的东西,并填补那些很少人会去填补的空白。
这包括数据集、工具和训练模型。我们启动的每一个 LLM 训练项目都始于发现一个空白,并相信我们可以做出有意义的贡献。
我们在 GPT-3 (Brown et al., 2020) 发布后启动了第一个 LLM 项目。当时感觉似乎没有人在构建开源替代方案,我们担心这些知识最终会被锁在少数几个工业实验室里。因此,我们启动了 BigScience workshop 来训练 GPT-3 的开源版本。最终诞生的模型是 Bloom,它是由数十名贡献者历时一年构建训练栈、分词器(tokenizer)和预训练语料库,并预训练出一个 175B 模型。
Bloom 的继任者是 2022 年的 StarCoder (Li et al., 2023)。OpenAI 为 GitHub Copilot 开发了 Codex (Chen et al., 2021),但它是闭源的。构建一个开源替代方案显然会为生态系统提供价值。因此,我们与 ServiceNow 合作,在 BigCode 的框架下构建了 The Stack 数据集,并训练了 StarCoder 15B 来复现 Codex。StarCoder2 (Lozhkov et al., 2024) 源于我们意识到可以训练更长时间,并认识到训练时间更长的较小模型可能比一个大模型更有价值。我们训练了一个系列(3B/7B/15B),使用了数万亿个 Token,远超当时任何人对开源代码模型所做的工作。
SmolLM 系列 遵循了类似的模式。我们注意到当时非常缺乏强大的小模型,而我们刚刚构建了 FineWeb-Edu (Penedo et al., 2024),这是一个强大的预训练数据集。SmolLM (135M/360M/1.7B) 是我们的第一个版本。SmolLM2 (Allal et al., 2025) 专注于更好的数据和更长的训练时间,在多个方面达到了 SOTA(最先进)性能。SmolLM3 扩展到了 3B,同时增加了混合推理、多语言和长上下文,这些都是社区在 2025 年所看重的特性。
这种模式延伸到了预训练之外:我们训练了 Zephyr (Tunstall et al., 2023) 以展示 DPO 在大规模下的有效性;启动了 Open-R1 以复现 DeepSeek R1 的蒸馏流水线,并发布了用于竞赛编程的 OlympicCoder,在国际信息学奥林匹克竞赛(IOI)中表现达到了 SOTA。我们还探索了其他模态,包括用于视觉的 SmolVLM (Marafioti et al., 2025) 和用于机器人的 SmolVLA (Shukor et al., 2025)。
希望本节内容已经让你确信,深入思考为什么要训练一个模型是有价值的。
在博客接下来的部分中,我们将假设你已经做好了这种“灵魂拷问”,并拥有正当的训练理由。
what:将目标转化为决策
现在你知道了为什么要训练,那么该训练什么呢?所谓“what”,我们指的是:模型类型(稠密模型、MoE 混合专家模型、混合架构或某种新架构)、模型大小、架构细节以及数据混合比例。一旦确定了“why”,你就可以推导出“what”,例如:
- 端侧快速模型 → 小型高效模型
- 多语言模型 → 大容量分词器词表
- 超长上下文 → 混合架构
除了由用例驱动的决策外,还有一些选择是为了优化训练本身,使其更稳定、采样效率更高或速度更快。这些决策并不总是那么明确,但你可以将决策过程大致分为两个阶段:
规划: 在运行实验之前,将你的用例映射到你需要决定的组件上。你的部署环境决定了模型大小的约束。你的时间线决定了你可以承担哪些架构风险。你的目标能力决定了数据集的需求。这个阶段的核心是将你“why”中的每个约束条件连接到“what”中的具体规格。
验证: 一旦有了起点和潜在修改列表,就要进行系统性测试。由于测试成本高昂,请专注于那些能够显著提高你的用例性能或优化训练的更改。这就是消融实验的用武之地,我们将在 消融实验章节 中详细介绍。
在无关紧要的选择上进行完美的消融实验,与在重要的选择上进行马虎的消融实验一样浪费算力。
在接下来的章节中,你将了解到定义模型的所有选项,以及如何通过系统性实验缩小选择范围。在深入讨论之前,我们想分享一些关于如何组建团队和项目的经验,这些经验源于我们自己的模型训练,以及对其他构建出色 LLM 的优秀团队的观察。
超能力:速度与数据
条条大路通罗马,但我们发现,让成功的 LLM 训练团队始终脱颖而出的是迭代速度。训练 LLM 实际上是一种“在训练中学习”的学科,你训练得越频繁,你的团队就会变得越优秀。 因此,在每年训练一个模型的团队和每季度训练一个模型的团队之间,后者进步的速度要快得多。你可以看看 Qwen 和 DeepSeek 的团队。他们现在已是家喻户晓,在以快速节奏持续发布新模型方面有着悠久的记录。
除了迭代速度,到目前为止,LLM 训练中影响最大的方面是数据策划(data curation)。人们往往倾向于钻研架构选择以改进模型,但在 LLM 训练中表现出色的团队,通常是那些比任何人都更痴迷于高质量数据的团队。
另一个与迭代速度相关的方面是团队规模:对于主要的预训练任务,你只需要少数几个拥有足够算力的人员即可。训练像今天 Llama 3 这样的模型,你可能只需要 2-3 个人。只有当你开始涉足更多元化的训练和下游任务(多模态、多语言、后训练等)时,你才会慢慢需要增加更多人手,以便在每个领域都表现卓越。
因此,从一个规模虽小但装备精良的团队开始,每 2-3 个月构建一个新模型,在很短的时间内你就能攀上顶峰。现在,本博客的其余部分将专注于这支团队的技术日常!
伟大的模型都始于微小的消融实验
在开始训练 LLM 之前,我们需要做出许多决定,这些决定将塑造模型的性能和训练效率。哪种架构最适合我们的用例?该使用哪种优化器和学习率调度?又该如何混合不同的数据源?
如何做出这些决定是一个经常被问到的问题。人们有时期望这些决定是通过深思熟虑得出的。虽然战略性思考至关重要——正如我们在 上一节 中讨论如何识别值得测试的架构更改时所提到的——但仅靠推理是不够的。在 LLM 领域,事情并不总是符合直觉,关于“什么应该起作用”的假设在实践中有时并不能奏效。
例如,使用看起来“质量最高的数据”并不总能产生更强大的模型。以 arXiv 为例,它是人类科学知识的巨大宝库。直觉上,在如此丰富的 STEM 数据上进行训练应该能产生更优越的模型,对吧?但在实践中并非如此,尤其是对于较小的模型,这甚至可能损害性能 (Shao et al., 2024)。为什么呢?原因在于,虽然 arXiv 论文充满了各种知识,但它们高度专业化,并且是以一种狭隘的学术风格编写的,这与能让模型学习效果最好的多样化、通用的文本截然不同。
那么,如果苦思冥想没有帮助,我们该如何知道什么有效呢?当然是像优秀的经验主义者一样运行大量实验!机器学习不是纯数学,而非常像一门实验科学。
由于这些实验将引导我们做出许多关键决策,因此设置好这些实验非常重要。我们主要希望它们具备两个属性:
- 速度: 要运行得尽可能快,以便我们能够频繁迭代。运行的消融实验越多,能测试的假设就越多。
- 可靠性: 实验应该有很强的辨别力。如果我们关注的指标无法在早期就显著区分不同配置,那么我们的消融实验可能收获甚微(而且如果指标存在较大的噪声,我们可能陷入不停追逐噪声的困境!)。更多细节可以查看 FineTaks 博客文章。
在设置消融实验之前,需要对架构类型和模型大小做出一些基础选择。这些决策(在我们的“指南”指引下)会影响训练框架的选择、如何分配算力以及从哪个基准(baseline)开始。
对于 SmolLM3,因为我们的目标是小型端侧模型,所以选择了 3B 参数的稠密 Llama 式架构。但正如你在 设计模型架构章节 中将看到的,MoE 或混合架构或许会更适合你的用例,不同的模型大小也伴随着不同的权衡。稍后我们将深入探讨这些选择。现在,让我们从第一步开始:选择你的 baseline。
选择 baseline
每个成功的模型都建立在一个经过充分验证的基准模型上,并根据自身需求进行修改。 Qwen 从 Llama 架构开始训练他们的第一个模型系列 (Bai et al., 2023) 。Meta 从Llama 2 开始训练 Llama 3。Kimi K2 从 DeepSeek-V3 的 MoE 架构开始。这种方法适用于架构,也适用于训练超参数和优化器。
因为优秀的架构和训练设置设计需要跨组织多年的迭代。标准的 Transformer 和 Adam 等优化器通过成千上万次实验得到了完善。人们发现了它的失效,调试了不稳定性,并优化了实现方式。从经过验证的基础开始意味着继承了所有积累的知识。从零开始则意味着你需要自己重新发现每一个问题。
以下是优秀参考架构应具备的特点:
- 符合你的需求:与你的部署目标和用例相匹配。
- 经过大规模验证:在相似或更大规模下完成过数万亿 tokens 的运行。
- 文档齐全:已在开源模型中证明有效的已知超参数。
- 框架支持:理想情况下,它应该在你考虑的训练框架以及计划使用的推理框架中都得到支持。
下面是一份不完全的针对 2025 年各种架构和模型大小的 baseline 选项列表:
| 架构类型 | 模型系列 | 大小 |
|---|---|---|
| Dense | Llama 3.1 | 8B, 70B |
| Dense | Llama 3.2 | 1B, 3B |
| Dense | Qwen3 | 0.6B, 1.7B, 4B, 14B, 32B |
| Dense | Gemma3 | 12B, 27B |
| Dense | SmolLM2, SmolLM3 | 135M, 360M, 1.7B, 3B |
| MoE | Qwen3 MoE | 30B-A3B, 235B-A122B |
| MoE | GPT-OSS | 21B-A3B, 117B-A5B |
| MoE | Kimi Moonlight | 16B-A3B |
| MoE | Kimi-k2 | 1T-A32B |
| MoE | DeepSeek V3 | 671B-A37B |
| Hybrid | Zamba2 | 1.2B, 2.7B, 7B |
| Hybrid | Falcon-H1 | 0.5B, 1.5B, 3B, 7B, 34B |
| MoE + Hybrid | Qwen3-Next | 80B-A3B |
| MoE + Hybrid | MiniMax-01 | 456B-A46B |
根据你的架构类型选择一个参数量接近你预想目标的 baseline。也不用过度纠结,因为你开始选择的架构并非一成不变。在下一节中,我们将看到如何从 baseline 演进出最适合你的最终架构。
改进 baseline:不要冒险
现在你已经有了一个行之有效且符合用例的 baseline。你可以就此止步,用你的混合数据集训练(假设数据质量还不错),也能得到一个不错的模型。这正是许多成功项目的做法。但 baseline 并非针对你的特定场景而优化,它是根据构建者的用例和部署目标而设计的。因此,进行一些修改以更好地对齐你的目标是更有价值的。然而,每一次架构更改都带有风险:它可能提升性能,也可能导致性能暴跌,或者在白白浪费消融实验算力的同时毫无作为。
让你保持在正确道路上的准则是 不要冒险(derisking):不要改任何内容,除非你的测试证明它确实有用。
当测试表明某项更改要么提升了某些性能,要么在不损害性能的情况下提供了实质性好处 (如更快的推理、更低的内存占用、更好的稳定性),且性能损失没有超出你可接受范围时,才算没有冒险(derisking)。
最棘手的地方在于,baseline 和训练设置中有太多可以修改的组件:注意力机制、位置编码、激活函数、优化器、训练超参数、归一化方案、模型布局等等。每一个都意味着一个潜在的实验,而且这些组件往往以非线性方式相互作用。你既没有时间也没有算力去测试所有的东西或探索每一种组件之间的影响。
首先针对当前的 baseline 测试那些看起来最有希望的更改。当某项更改奏效时,将其集成以创建一个新的 baseline,然后再针对新的 baseline 测试下一项更改。如果算力预算允许,你可以单独测试各项更改并用“留一法”(leave-one-out)分析。
不要想着对每一个超参数进行详尽网格搜索,或测试每一个新出的架构变体。
如果你不知道哪些实验值得做,那么知道怎么运行实验也无济于事。 在测试任何修改之前,问自己两个问题:
- 这对特定用例有帮助吗?
- 这能优化训练吗?
如果某项修改无法明确回答这两个问题,请放弃它。
现在你已经知道如何通过战略规划识别有潜力的更改,是时候进入 经验验证 阶段了。在接下来的章节中,我们将向你展示在实践中如何真正测试这些更改。我们将介绍如何建立可靠的实验、解读结果以及避免常见坑点。在随后的章节中,我们将通过具体案例,带你测试流行的架构、数据、基础设施和训练决策。
让我们建立一个简单的、可用于实验的消融实验设置。第一步,决定选择哪个训练框架。
选择训练框架
我们需要做的第一个决定是使用哪个框架来训练模型,进而运行我们所有的消融实验。这个选择需要平衡三个关键考虑因素:
- 框架必须支持我们的目标架构,或者能让我们轻松扩展。
- 要稳定且具备生产能力,不容易在训练中途莫名其妙地崩溃。
- 能提供强大的吞吐量,以便我们能够快速迭代并充分利用算力。
在实践中,这些要求可能会相互冲突,需要权衡。让我们来看看现有的选项。
| 框架 | 特性 | 经受过实战检验 | 经过优化 | 代码行数 (核心 / 总计) | 扩展性与调试 |
|---|---|---|---|---|---|
| Megatron-LM | ✅ 极其丰富 | ✅ Kimi-K2, Nemotron | ✅ 3D 并行化的先驱 | 93k / 269k | ⚠️ 对初学者较难 |
| DeepSpeed | ✅ 极其丰富 | ✅ BLOOM, GLM | ✅ ZeRO 与 3D 并行化的先驱 | 94k / 194k | ⚠️ 对初学者较难 |
| TorchTitan | ⚡ 特性不断增加 | ⚠️ 较新,但由 PyTorch 团队测试 | ⚡ 针对稠密模型优化,MoE 改进正在进行中 | 7k / 9k | ⚡ 中等:需要并行化知识 |
| Nanotron | 🎯 极简,为 HF 预训练量身定制 | ✅ 是 (StarCoder, SmolLM) | ✅ 经过深度优化 (UltraScale Playbook) | 15k / 66k | ⚡ 中等:需要并行化知识 |
上表总结了流行框架之间的关键权衡。前三个框架的代码行数引用自 TorchTitan 技术报告 (Liang et al., 2025)。让我们更详细地讨论一下:
Nvidia 的 Megatron-LM 已存在多年且久经沙场。它为 Kimi K2 (Team et al., 2025) 等模型提供动力,拥有稳定的吞吐量和我们想要的大多数特性。但成熟也伴随着复杂性:当你刚开始接触时,代码库可能很难定位和修改。
DeepSpeed 属于类似类别。它是 ZeRO 优化的先驱,曾助力 BLOOM 和 GLM 等模型。与 Megatron-LM 一样,它经过了广泛的实战检验和优化,但也面临同样的复杂性挑战。庞大的代码库(总计 19.4 万行)对于新手来说可能令人生畏,特别是在实现自定义特性或调试意外行为时。
另一方面,PyTorch 最近推出的 TorchTitan 库要轻量得多,得益于其精简且模块化的代码库,它更容易定位代码。它具备预训练所需的核心特性,非常适合快速实验。然而,由于它比较新,还没有经过太多的实战检验,且随着活跃开发,可能仍然存在一些不稳定性。
我们走了一条不同的路,从头开始构建了自己的框架 nanotron。这赋予了我们完全的灵活性和对大规模预训练的深刻理解;这些见解后来演变成了 Ultra Scale Playbook。自从我们开源了这个库,我们也从社区获得了宝贵的反馈,尽管在大多数情况下我们必须先自己对特性进行实战测试。该框架现在支持训练所需的所有生产特性,但我们仍在完善 MoE 支持等领域。
从零开始构建是有意义的,但它需要团队在专业知识上投入巨大,并花费大量时间来调试问题和添加缺失特性。一个强有力的替代方案是 fork 一个现有框架并根据你的需求进行增强。例如,Thinking Machines Lab 将他们的内部预训练库构建为 TorchTitan 的 fork(来源)。
最终,你的选择取决于团队的专业知识、目标特性,以及相对于直接使用最成熟产品来讲,你愿意在框架开发上投入多少时间。
如果多个框架都能满足你的需求,请在你的特定硬件上对比它们的吞吐量。对于快速实验和快速运行,更简洁的代码库通常更胜一筹。
消融实验配置
选定框架后,我们现在需要设计消融实验配置。我们需要既能快速迭代,又具有足够规模、能提供有效信号并迁移到最终模型的实验。让我们看看如何配置。
配置消融实验框架
消融实验的目标是进行小规模实验,并获得我们能够自信地外推到最终生产运行的结果。
主要有两种方法。我们可以采用目标模型的大小,但使用较少的 tokens 进行训练。在 SmolLM3 的消融实验中,我们用 100B tokens 训练了完整的 3B 模型,而不是最终的 11T tokens。如果目标模型太大,也可以训练一个小型的代理模型(proxy model)进行消融。例如,当 Kimi 在开发拥有 1T 参数、32B 激活参数的 Kimi K2 模型时,在消融实验中使用完整规模会非常昂贵,因此他们在 3B MoE(0.5B 激活参数)上运行了一些消融实验 (Team et al., 2025)。
关键问题是这些小规模发现是否真的能外推。根据我们的经验,如果某项改动在小规模下就损害了性能,那基本就可以很自信的放弃它了。但如果某项改动在小规模下奏效,你仍需确保已经训练了足够数量的 tokens,才能以高概率断定这些发现会外推到更大规模。训练时间越长、消融模型与最终模型越接近,效果就越好。
在本博客中,我们将使用 baseline Vanilla Transformer 进行所有消融。我们的主要设置是 1B Transformer,遵循 Llama3.2 1B 架构,并在 45B tokens 上进行训练。使用 8 张 H100 显卡的单节点运行此 nanotron 配置 大约需要 1.5 天(每张 GPU 每秒处理 4.2 万 tokens)。在 SmolLM3 训练期间,我们在 3B 模型上运行了这些消融实验,训练了 100B tokens(配置见此处)。我们将在每章末尾分享这些结果(你会发现结论是一致的)。
我们的 1B baseline 配置以 YAML 格式记录了所有必须的训练细节。以下是关键部分:
## 数据集与混合权重
data_stages:
- data:
dataset:
dataset_folder:
- fineweb-edu
- stack-edu-python
- finemath-3plus
dataset_weights:
- 0.7
- 0.2
- 0.1
## 模型架构:Llama3.2 1B 配置
model:
model_config:
hidden_size: 2048
num_hidden_layers: 16
num_attention_heads: 32
num_key_value_heads: 8
intermediate_size: 8192
max_position_embeddings: 4096
rope_theta: 50000.0
tie_word_embeddings: true
## Training hyperparameters, AdamW with cosine schedule
optimizer:
clip_grad: 1.0
learning_rate_scheduler:
learning_rate: 0.0005
lr_decay_starting_step: 2000
lr_decay_steps: 18000
lr_decay_style: cosine
lr_warmup_steps: 2000
lr_warmup_style: linear
min_decay_lr: 5.0e-05
optimizer_factory:
adam_beta1: 0.9
adam_beta2: 0.95
adam_eps: 1.0e-08
name: adamW
## Parallelism, 1 node
parallelism:
dp: 8 # Data parallel across 8 GPUs
tp: 1 # No tensor or pipeline parallelism needed at 1B scale
pp: 1
## Tokenizer
tokenizer:
tokenizer_max_length: 4096
tokenizer_name_or_path: HuggingFaceTB/SmolLM3-3B
## Batch size, sequence length and total training for 30B tokens
tokens:
batch_accumulation_per_replica: 16
micro_batch_size: 3 # GBS (global batch size)=dp * batch_acc* MBS * sequence=1.5M tokens
sequence_length: 4096
train_steps: 20000 # GBS * 20000 = 30B
...(truncated)
对于我们的消融实验,我们将根据测试内容修改不同的部分,同时保持其他所有内容不变:model 部分用于架构选择,optimizer 部分用于优化器和训练超参数,data_stages 部分用于数据整理。
在每次消融实验中只改变一个变量,同时保持其他所有内容不变。 如果你改变了多项内容且性能有所提升,你将无法确定是哪项改动 起到了作用。应单独测试各项修改,然后将成功的修改组合起来并重新评估。
在运行消融实验时,某些架构更改可能会显著改变参数数量。例如,从绑定嵌入(tied embeddings)切换到非绑定嵌入会使嵌入参数翻倍,而从 MHA 切换到 GQA 或 MQA 则会大幅减少注意力参数。为了确保公平比较,我们需要跟踪参数数量,并偶尔调整其他超参数(如隐藏层大小或层数),以使模型规模大致相同。以下是我们用于估算不同配置参数数量的一个简单函数:
from transformers import LlamaConfig, LlamaForCausalLM
def count_parameters(
tie_embeddings=True,
num_key_value_heads=4,
num_attention_heads=32,
hidden_size=2048,
num_hidden_layers=16,
intermediate_size=8192,
vocab_size=128256,
sequence_length=4096,
):
config = LlamaConfig(
hidden_size=hidden_size,
num_hidden_layers=num_hidden_layers,
num_attention_heads=num_attention_heads,
num_key_value_heads=num_key_value_heads,
intermediate_size=intermediate_size,
vocab_size=vocab_size,
max_position_embeddings=sequence_length,
tie_word_embeddings=tie_embeddings,
)
model = LlamaForCausalLM(config)
return f"{sum(p.numel() for p in model.parameters())/1e9:.2f}B"
我们还提供了一个交互式工具,用于可视化稠密 Transformer 的 LLM 参数分布。这在做出架构决策或配置消融实验时会派上用场。
洞察成效:评估
一旦我们启动了消融实验,我们如何知道哪些方案有效,哪些无效呢?
任何模型训练者的第一直觉可能是查看损失(loss),这确实重要。你希望看到的损失平稳下降,没有剧烈的波动或不稳定性。对于许多架构选择,损失与下游性能(微调阶段)高度相关,作为评估基准足够有效 (Y. Chen et al., 2025)。但仅仅依靠损失并不总是可靠的。以数据消融为例,你会发现训练维基百科比训练网页的损失更低(因为下一个 token 更容易预测),但这并不意味着你会得到一个更强大的模型。同样,如果我们更换了分词器,因为文本的切分方式不同,运行之间的损失就无法直接比较。某些改动还可能专门影响特定能力(如推理和数学),而这些影响可能会被平均损失所掩盖。更重要的是,即使在预训练损失收敛之后,模型在下游任务上的表现仍可以继续提升 (Liu et al., 2022)。
我们需要更细粒度的评估来把控全局并理解这些微妙的影响。一种自然的方法是使用下游评估(downstream evaluations),测试模型在知识、理解、推理以及任何我们关心的领域的表现。
对于消融实验,最好专注于那些能提供良好早期信号的任务,并避开高噪声的基准测试。在 FineTasks 和 FineWeb2 中,可靠的评估任务由四个关键原则定义:
- 单调性(Monotonicity): 随着训练时间的增加,基准测试的分数应持续提高。
- 低噪声(Low noise): 当我们使用相同设置但不同随机种子时,分数不应剧烈波动。
- 高于随机的表现(Above-random performance): 许多能力只会在训练的较后阶段才逐渐显现,因此,那些在很长一段训练过程中都只表现为随机水平的任务,并不适合用于消融实验。例如,采用多项选择格式的 MMLU 就属于这种情况,具体原因我们将在后文中解释。
- 排名一致性(Ranking consistency): 如果某种方法在早期阶段优于另一种方法,那么随着训练的继续,这种优劣顺序应保持稳定。
任务的质量还取决于任务的形式(我们如何向模型提问)和指标的选择(我们如何计算得分)。
三种常见的任务形式是:多项选择格式(MCF)、完形填空形式(CF)和自由生成(FG)。多项选择格式要求模型从提示中明确给出并带有 A/B/C/D 前缀的选项中选择一个(例如 MMLU)。在完形填空形式中,我们比较不同选项的似然度(likelihood)来判断哪个更合理,而无需在提示中提供选项。在 FG 中,我们观察针对给定提示的贪婪生成(greedy generation)的准确性。FG 需要模型具备大量的潜藏知识,对于完整训练前的短期预训练消融实验中的模型来说,这种任务通常难度过大,无法提供有用信号。因此,在运行小规模消融实验时,我们侧重于多项选择形式(MCF 或 CF)。
对于后训练(post-trained)模型,FG 成为主要的任务形式,因为 我们要评估的是模型能否真正生成有用的回答。 我们将在后训练章节中介绍针对这些模型的评估。
研究还表明,模型在训练初期难以掌握 MCF,只有在经过大量训练后才能学会这项技能,因此 CF 更适合作为早期信号 (Du et al., 2025; Gu et al., 2025; J. Li et al., 2025)。我们对小型消融实验使用 CF,并在主训练运行中整合 MCF,因为在模型越过特定阈值并获得足够高的信噪比后,MCF 能提供更好的中期训练信号。另外说明一下,为了在 CF 等序列似然评估中为模型的答案打分,我们将准确率计算为:在多少比例的问题中,正确答案的对数概率(按字符数归一化)最高。这种归一化可以防止模型偏向较短的答案。
我们的消融评估套件包括来自 FineWeb 消融实验的基准测试,但去掉了 SIQA,因为我们发现它噪声太大。我们添加了数学和代码基准测试,如 GSM8K 和 HumanEval,以及用于长文本消融的长文本基准 RULER。这些任务的集合跨越多种格式,测试了世界知识、推理和常识,如下表所示。为了在牺牲少量噪声的情况下加快评估速度,我们对每个基准仅评估 1,000 个问题(GSM8K、HumanEval 和 RULER 除外,它们在 3B SmolLM3 消融中完整使用,但在下文的 1B 实验中省略)。我们还如前所述,对所有多项选择基准使用完形填空(CF)评估。需要注意的是,对于多语言消融和实际训练,我们增加了更多基准来测试多语言能力,详情见后文。这些评估使用 LightEval 运行,下表总结了每个基准的关键特征:
| 基准 | 领域 | 任务类型 | 问题数量 | 测试内容 |
|---|---|---|---|---|
| MMLU | 知识 | 多项选择 | 14k | 跨 57 个学科的广泛学术知识 |
| ARC | 科学与推理 | 多项选择 | 7k | 小学水平的科学推理 |
| HellaSwag | 常识推理 | 多项选择 | 10k | 对日常情境的常识推理(叙事补全) |
| WinoGrande | 常识推理 | 二元选择 | 1.7k | 需要世界知识的代词消解 |
| CommonSenseQA | 常识推理 | 多项选择 | 1.1k | 对日常概念的常识推理 |
| OpenBookQA | 科学 | 多项选择 | 500 | 包含推理的基础科学事实 |
| PIQA | 物理常识 | 二元选择 | 1.8k | 关于日常物品的物理常识 |
| GSM8K | 数学 | 自由生成 | 1.3k | 小学数学应用题 |
| HumanEval | 代码 | 自由生成 | 164 | 根据 docstrings 合成 Python 函数 |
让我们从每个基准中看几个示例问题,以便直观了解这些评估到底在测什么:
浏览上面的示例,看看每个基准中的问题类型。注意 MMLU 和 ARC 如何通过多项选择测试事实知识,GSM8K 如何要求计算数学题的数值答案,以及 HumanEval 如何要求生成完整的 Python 代码。这种多样性确保了我们在整个消融实验中能够测试模型能力的不同维度。
消融实验使用哪种数据混合策略?
对于 架构消融实验,我们使用固定比例的高质量数据集混合进行训练,这些数据集能在各种任务中提供早期信号。我们使用了英语 (FineWeb-Edu)、数学 (FineMath) 和代码 (Stack-Edu-Python)。架构层面的发现能很好地推演到其他数据集和领域(包括多语言数据),因此我们可以保持简单的数据混合策略。
对于 数据消融实验,我们采取相反的方法:固定架构,并系统地改变数据混合策略,以理解不同的数据源如何影响模型性能。
一套稳健的消融实验设置,其价值远不止于构建一个优秀的模型。当我们的主训练运行不可避免地出现问题时(无论准备得多么充分,总会出问题),我们希望对之前做的每一个决策都有信心,并能迅速识别出哪些组件未经过妥善测试,从而可能导致了当前的问题。这种准备能节省调试时间,也为我们未来的心理健康提供了保障。
估算消融实验成本
消融实验虽然效果显著,但需要耗费 GPU 时间,了解这些实验的成本很有必要。下表显示了 SmolLM3 预训练的完整算力成本明细:主训练运行(计入了偶尔的停机时间)、训练前和训练期间的消融实验,以及由于意外的扩展问题导致的重启和部分调试所花费的算力(后文详述)。
| Phase | GPUs | Days | GPU-hours |
|---|---|---|---|
| 主预训练运行 | 384 | 30 | 276,480 |
| 消融实验(预训练阶段) | 192 | 15 | 69,120 |
| 消融实验(训练中期阶段) | 192 | 10 | 46,080 |
| 训练重置与调试 | 384/192 | 3/4 | 46,080 |
| 总成本 | - | - | 437,760 |
这些数字揭示了一个重要事实:消融和调试总共消耗了 161,280 GPU 小时,超过了我们主训练运行成本的一半(276,480 GPU 小时)。在 SmolLM3 的开发过程中,我们总共运行了 100 多次消融实验:预训练消融耗时 20 天,训练中期消融耗时 10 天,还有 7 天用于从意外的训练问题中恢复(该问题导致了重启和部分调试,后文详述)。
这突显了为什么消融成本必须纳入算力预算:计划训练成本 + 消融成本 + 应对意外情况的缓冲。如果你追求 SOTA 性能、尝试新的架构方案,或者还没有一套经过验证的方案,那么消融实验将成为一个主要的成本中心,而非次要的零星实验。
在进入下一节之前,让我们为每个进行实验的人建立一些基本准则。
参与准则
TL;DR: 保持偏执。
验证你的评估套件。 在训练任何模型之前,请确保你的评估套件能够复现你要对比的已发布模型的结果。如果任何基准测试具有生成性质(如 GSM8k),要格外小心,手动检查一些样本,确保提示格式正确,且后续处理提取了正确的信息。由于评估将指导你的每一个决策,这一步能否做对,对项目的成败至关重要!
测试每一项改动,无论多小。 不要低估那个看似无害的库升级,或者那个“只改了两行代码”的提交的影响。这些小改动可能引入微妙的 bug 或性能波动,从而污染你的实验结果。你需要一个在关键案例上拥有强大测试套件的库,以避免出现性能倒退(regression)。
一次只改变一个变量。 在实验之间保持其他条件完全一致。不同的更改有时会以意想不到的方式相互作用,所以我们首先要评估每个更改的单独贡献,再尝试将它们组合,观察整体影响。
用足够的 tokens 进行训练,并保证充分的评测。 正如前文所述,我们需要确保评测集有良好的覆盖范围,并且训练足够长时间,才能获得可靠的信号。如果在这里偷工减料,会导致结果噪声很大,决策也会因此变差。
遵循这些规则可能显得过于谨慎,但如果不这样做,你可能会花上数天时间调试那些奇怪的性能下降,最终却发现是由几天前一次无关的依赖更新导致的。黄金原则是:一旦你有了确定好了配置,没有经过更改的情况下不要做任何更改!
设计模型架构
实验框架已经搭建完成,现在是时候做出那些将定义我们模型的重大决策了。我们做出的每一个选择——从模型大小到注意力机制再到分词器——都会产生约束和机遇,影响模型的训练和使用。
回想一下训练指南:在做任何技术决策之前,我们需要明确 为什么 和 做什么。我们为什么要训练这个模型?它应该是什么样子?
这听起来很显而易见,但正如我们在训练指南中解释的那样,在这里深思熟虑会塑造我们的决策,避免我们在无穷无尽的实验空间中迷失方向。我们的目标是做一个英语领域的 SOTA 模型吗?长上下文是优先事项吗?还是我们在尝试验证一种新架构?在这些情况下,训练循环可能看起来相似,但我们运行的实验和接受的权衡取舍会有所不同。尽早回答这个问题有助于我们决定如何在数据和架构工作之间分配时间,以及在开始正式训练之前在每个方面应该做多少创新。
让我们以身作则,逐步讲解指导 SmolLM3 设计的目标。我们想要一个强大的端侧应用模型,具有出色的多语言性能、可靠的数学和编程能力,以及鲁棒的长上下文处理能力。正如我们之前提到的,这使我们选择了一个 3B 参数的稠密模型:足够大以拥有强大的能力,但又足够小可以在手机上流畅运行。考虑到边缘设备的内存限制和我们的项目时间线(大约 3 个月),我们选择了稠密 Transformer 而不是 MoE 或混合架构。
我们之前有一个在较小规模(1.7B 参数)上用于英语的 SmolLM2 工作方案,但扩展规模意味着需要重新验证一切,并应对新的挑战,如多语言支持和扩展上下文长度。这是一个明确的例子,说明既定目标如何决定了我们的方向。例如,在 SmolLM2 中,我们在预训练最后,扩展上下文长度时遇到了困难,所以对于 SmolLM3,我们从一开始就做出了架构选择——比如使用 NoPE 和文档内掩码(稍后会介绍)——以最大化成功的可能性,事实证明这是非常有效的。
一旦我们的目标明确,就可以开始做出将其变为现实的技术决策。在本章中,我们将逐步介绍我们对这些核心决策的系统化方法:架构、数据和超参数。把这看作是我们的战略规划阶段,把这些基础工作做好将帮我们避免在实际训练马拉松中犯下代价高昂的错误。
架构选择
如果你研究一下最近的模型,比如 Qwen3、Gemma3 或 DeepSeek v3,你会发现尽管它们各有不同,但都共享同一个基础——2017 年提出的 Transformer 架构 (Vaswani et al., 2023)。这些年来变化的不是基本结构,而是对其核心组件的改进。无论你是在构建稠密模型、混合专家模型还是混合架构,你都在使用这些相同的构建模块。
这些改进来自于各个团队为追求更好的性能而应对特定挑战:推理时的内存限制、大规模训练的不稳定性,或者处理更长上下文的需求。一些修改,比如从多头注意力(MHA)转向计算效率更高的注意力变体如分组查询注意力(GQA)(Ainslie et al., 2023),现在已经被广泛采用。其他的,比如不同的位置编码方案,仍在争论中。最终,今天的实验将凝结成明天的基准。
那么现代 LLM 今天实际上使用什么呢?让我们来看看领先模型的共同选择。遗憾的是,并非所有模型都公开其训练细节,但我们从 DeepSeek、OLMo、Kimi 和 SmolLM 等家族获得了足够的信息来了解当前的格局:
| Model | Architecture | Parameters | Training Tokens | Attention | Context Length (final) | Position Encoding | Precision | Init (std) | Optimizer | Max LR | LR Schedule | Warmup Steps | Batch Size |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepSeek LLM 7B | Dense | 7B | 2T | GQA | 4K | RoPE | BF16 | 0.006 | AdamW | 4.2×10⁻⁴ | Multi-Step | 2K | 9.4M |
| DeepSeek LLM 67B | Dense | 67B | 2T | GQA | 4K | RoPE | BF16 | 0.006 | AdamW | 3.2×10⁻⁴ | Multi-Step | 2K | 18.9M |
| DeepSeek V2 | MoE | 236B (21B active) | 8.1T | MLA | 128K | Partial RoPE | - | 0.006 | AdamW | 2.4×10⁻⁴ | Multi-Step | 2K | 9.4M→37.7M (warmup 225B) |
| DeepSeek V3 | MoE | 671B (37B active) | 14.8T | MLA | 129K | Partial RoPE | FP8 | 0.006 | AdamW | 2.2×10⁻⁴ | Multi-Step + Cosine | 2K | 12.6M→62.9M (warmup 469B) |
| MiniMax-01 | MoE + Hybrid | 456B (45.9 active) | 11.4T | Linear attention + GQA | 4M | Partial RoPE | - | Xavier init with deepnorm scaling | AdamW | 2×10⁻⁴ | Multi-Step | 500 | 16M→32M→64M→128M |
| Kimi K2 | MoE | 1T (32B active) | 15.5T | MLA | 128K | Partial RoPE | BF16 | likely 0.006 | MuonClip | 2×10⁻⁴ | WSD | 500 | 67M |
| OLMo 2 7B | Dense | 7B | 5T | MHA | 4K | RoPE | BF16 | 0.02 | AdamW | 3×10⁻⁴ | Cosine | 2K | 4.2M |
| SmolLM3 | Dense | 3B | 11T | GQA | 128K | NoPE | BF16 | 0.02 | AdamW | 2×10⁻⁴ | WSD | 2K | 2.3M |
如果你还不理解其中一些术语,比如 MLA、NoPE 或 WSD,不用担心。我们将在本节中逐一解释。现在,只需注意其多样性:不同的注意力机制(MHA、GQA、MLA),位置编码(RoPE、NoPE、partial RoPE),以及学习率调度(Cosine、Multi-Step、WSD)。
面对这一长串架构选择,要弄清楚从哪里开始确实让人有些不知所措。和大多数类似情况一样,我们将一步一步来,逐渐积累所有必要的知识。我们将首先关注最简单的基础架构(稠密模型),详细研究每个架构方面。之后,我们将深入探讨 MoE 和混合模型,并讨论何时使用它们是一个好的选择。最后我们将探索分词器,这是一个经常被忽视和低估的组件。我们应该使用现有的分词器还是训练自己的?我们如何评估我们的分词器是否足够好?
在本章的其余部分,我们通过使用上一章描述的设置进行消融实验来验证大多数架构选择:我们的 1B 基线模型(遵循 Llama3.2 1B 架构),在来自 FineWeb-Edu、FineMath 和 Python-Edu 混合的 45B tokens 上进行训练。对于每个实验,我们展示训练损失曲线和下游评估分数,以评估每个修改的影响。你可以在 HuggingFaceTB/training-guide-nanotron-configs 找到所有运行的配置。
现在让我们从每个 LLM 的核心开始:注意力机制。
注意力机制
Transformer 架构研究中最活跃的领域之一就是注意力机制。虽然前馈层在预训练期间占主导计算量,但注意力在推理时成为主要瓶颈(尤其是在长上下文场景下),它会拉高计算成本,而 KV 缓存会快速消耗 GPU 内存,降低吞吐量。让我们快速浏览一下主要的注意力机制,以及它们如何在容量和速度之间进行权衡。
我的注意力需要多少头?
多头注意力(Multi-head attention,MHA) 是与原始 Transformer 一起引入的标准注意力 (Vaswani et al., 2023)。主要思想是你有 N 个注意力头,每个头独立执行相同的检索任务:将隐藏状态转换为查询(queries)、键(keys)和值(values),然后使用当前查询通过匹配键来检索最相关的 token,最后转发与匹配 token 关联的值。在推理时,我们不需要为过去的 token 重新计算 KV 值,而是可以重用它们。存储过去 KV 值的内存称为 KV-Cache。随着上下文窗口的增长,这个缓存很快就会成为推理瓶颈并消耗大量 GPU 内存。以下是一个简单的计算,用于估算使用 MHA 和序列长度为 8192 的 Llama 3 架构的 KV 缓存内存 :
第一个 2 是因为需要同时存储键缓存和值缓存。正如你所见,缓存随序列长度线性增加,但上下文窗口呈指数级增长,现在已达到数百万 tokens。因此,提高缓存的效率将使推理时的上下文扩展变得更加容易。
一个自然的问题是:我们真的需要为每个头都生成新的 KV 值吗?可能不需要,多查询注意力(Multi-Query Attention,MQA)(Shazeer, 2019) 和分组查询注意力(Grouped Query Attention,GQA)(Ainslie et al., 2023) 都解决了这个问题。最简单的情况是在所有头之间共享 KV 值,从而将 KV 缓存的大小除以 ,例如对于 Llama 3 70B 来说这是 64 倍的减少!这就是 MQA 的思想,被用在一些模型中如 StarCoder,作为 MHA 的替代方案。然而,我们可能会放弃比预期更多的注意力容量,所以可以考虑折中方案,在头的组之间共享 KV 值,例如 4 个头共享相同的 KV 值。这就是 GQA 的方法,在 MQA 和 MHA 之间取得了平衡。
最近,DeepSeek-v2(也用于 v3)引入了 多潜变量注意力(Multi-Latent Attention,MLA) (DeepSeek-AI et al., 2024),它使用不同的策略来压缩缓存:不是减少 KV 值的数量,而是减小它们的大小,只存储一个潜变量,在运行时解压缩成 KV 值。通过这种方法,他们成功地将缓存减少到相当于 2.25 组的 GQA,同时性能比 MHA 更强!为了使这与 RoPE 兼容,需要一个额外的小潜变量向量的小调整。在 DeepSeek-v2 中,他们选择 作为主潜变量, 用于 RoPE 部分,所以总共是 ,同时用于 K 和 V,因此去掉了前面的因子 2。
你可以在下图中看到每种注意力机制的可视化解释:
下表比较了我们刚才在本节讨论的注意力机制。为简单起见,我们比较每个 token 使用的参数大小,如果你想计算总内存,只需乘以每个参数的字节数(通常为 2)和序列长度:
| Attention Mechanism | KV-Cache parameters per token |
|---|---|
| MHA | |
| MQA | |
| GQA | |
| MLA |
现在让我们看看这些注意力机制在实际实验中表现如何!
消融实验 - GQA 优于 MHA
在这里我们比较不同的注意力机制。我们的baseline模型使用 32 个头和 8 个 KV 头,对应于比率为 32/8=4 的 GQA。如果我们使用 MHA,或者使用更少的 KV 头和更高的 GQA 比率,性能会如何变化?
改变 KV 头的数量会影响参数数量,特别是在 MHA 的情况下。为了保持一致性,我们调整了 MHA 运行的层数,否则会有超过 100M 的参数差异;对于其余的,我们保持默认的 16 层。
| Attention Type | Query Heads | KV Heads | Layers | Parameter Count | Notes |
|---|---|---|---|---|---|
| MQA | 32 | 1 | 16 | 1.21B | |
| GQA (ratio 16) | 32 | 2 | 16 | 1.21B | |
| GQA (ratio 8) | 32 | 4 | 16 | 1.22B | Our baseline |
| GQA (ratio 4) | 32 | 8 | 16 | 1.24B | |
| GQA (ratio 2) | 32 | 16 | 15 | 1.22B | Reduced layers |
| MHA | 32 | 32 | 14 | 1.20B | Reduced layers |
| GQA (ratio 2) | 32 | 16 | 16 | 1.27B | Too large - not ablated |
| MHA | 32 | 32 | 16 | 1.34B | Too large - not ablated |
所以我们比较了 MHA、MQA 和 4 种 GQA 设置(比率 2、4、8、16)。你可以在这里找到 nanotron 配置。
观察消融结果,我们发现 MQA 和 16 组的 GQA(分别只留下 1 和 2 个 KV 头)明显不如 MHA。另一方面,2、4 和 8 组的 GQA 配置与 MHA 性能大致相当。
结果在损失曲线和下游评估中都是一致的。我们在 HellaSwag、MMLU 和 ARC 等基准测试中清楚地观察到这一点,而 OpenBookQA 和 WinoGrande 等基准测试则显示出一些噪声。
基于这些消融实验,GQA 是 MHA 的可靠替代方案。它在保持性能的同时,在推理时更加高效。一些最近的模型已经采用了 MLA 以实现更大的 KV 缓存压缩,尽管它尚未被广泛采用。我们没有对 MLA 进行消融实验,因为在进行消融实验时它还没有在 nanotron 中实现。对于 SmolLM3,我们使用了 4 组的 GQA。
除了注意力架构本身,我们在训练期间使用的注意力模式也很重要。让我们来看看注意力掩码。
文档掩码
我们如何在训练序列中应用注意力会影响计算效率和模型性能。这就引出了 文档掩码 以及我们如何在数据加载器中组织训练样本这个更广泛的问题。
在预训练期间,我们使用固定的序列长度进行训练,但我们的文档长度是不一样的。一篇研究论文可能有 10k tokens,而一个短代码片段可能只有几百 tokens。我们如何将不同长度的文档放入固定长度的训练序列中?直接对较短的文档进行 padding(填充)以达到目标长度,会浪费计算资源,因为这些填充 token 没有实际意义。为此,我们使用 打包(packing) 方法:先将文档打乱并用 EOS(序列结束)token 连接起来,然后将得到的长序列按固定长度切分,得到与训练序列长度匹配的块。
实践中看起来像这样:
File 1: "Recipe for granola bars..." (400 tokens) <EOS>
File 2: "def hello_world()..." (300 tokens) <EOS>
File 3: "Climate change impacts..." (1000 tokens) <EOS>
File 4: "import numpy as np..." (3000 tokens) <EOS>
...
After concatenation and chunking into 4k sequences:
Sequence 1: [File 1] + [File 2] + [File 3] + [partial File 4]
Sequence 2: [rest of File 4] + [File 5] + [File 6] + ...
如果一个训练序列足够长可以填满我们的 4k 上下文,它可能包含一个完整的文件,但在大多数情况下文件很短,所以序列包含多个随机文件的连接。
在标准的因果掩码下,token 可以关注打包序列中所有先前的 token。以上例子里,文件 4 的那段 Python 函数中的一个 token,可以关注到燕麦棒配方、气候变化文章,以及其他碰巧被拼在一起的内容。我们快速看一下典型的 4k 预训练上下文会包含什么。对上下文长度做个快速分析可知,CommonCrawl 和 GitHub 中相当大比例(约 80-90%)的文件都短于 2k token。
下图展示了本文所用较新数据集的 token 分布:
FineWeb-Edu、DCLM、FineMath 和 Python-Edu 中超过 80% 的文档少于 2k token。这意味着在 2k 或 4k 的训练序列、标准因果掩码下,绝大多数 token 的计算会花在关注被拼在一起但彼此无关的文档上。
虽然多数基于网页的数据集由短文档构成,但基于 PDF 的数据集包含更长的内容。FinePDFs 文档平均长度是网页文本的 2 倍,和 FineWeb-Edu、DCLM 混合后还能提升性能。
除了计算低效之外,@zhao2024 发现这种做法会引入无关内容噪声,从而降低性能。他们建议使用 intra-document masking,即修改注意力掩码,让 token 只能关注同一文档内的前序 token。下面的可视化展示了这一差异:
SkyLadder 的 Zhu et al. (2025) 也发现文档内掩码带来类似收益,但给出了不同解释。他们发现较短的上下文长度更利于训练,而文档内掩码有效降低了平均上下文长度。
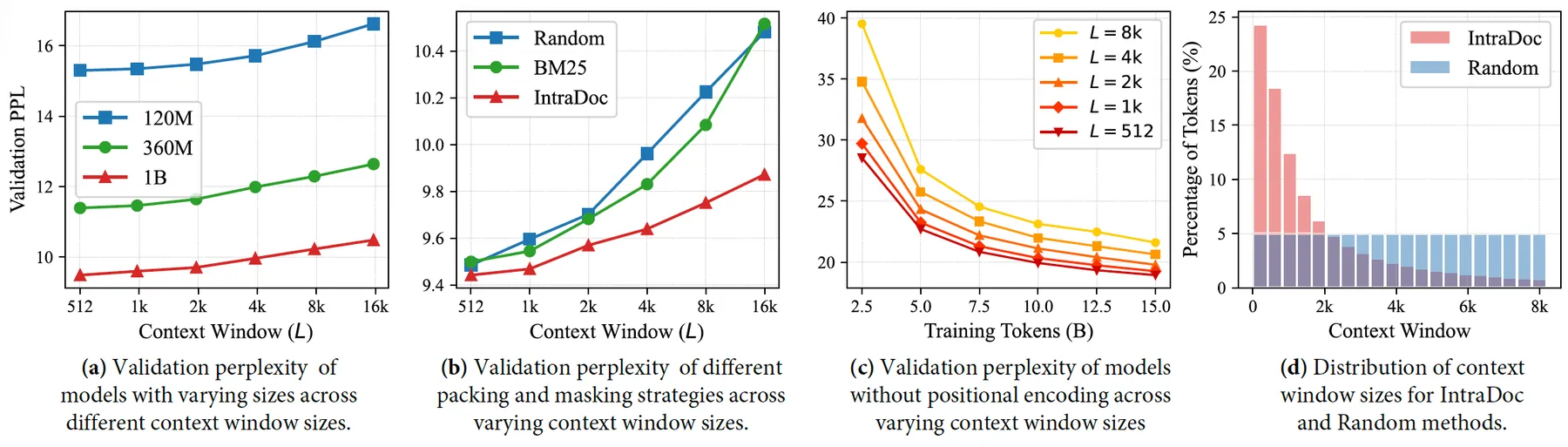
Llama3 (Grattafiori et al., 2024) 也采用了文档内掩码训练。他们发现对短上下文预训练影响有限,但在长上下文扩展上收益显著,因为此时注意力开销更突出。此外,ProLong 论文 (Gao et al., 2025) 表明,在持续预训练中用文档掩码扩展 Llama3 8B 的上下文,对长上下文和短上下文基准都有提升。
我们决定在 1B 基线模型上做消融,测试文档掩码是否影响短上下文性能。配置在这里。结果显示,与标准因果掩码相比,损失曲线和下游评估分数几乎一致,如下图所示。
要在 nanotron 中启用文档掩码,只需在模型配置里把这个标志设为 true:
model_config:
_attn_implementation: flash_attention_2
_fused_rms_norm: true
_fused_rotary_emb: true
- _use_doc_masking: false
+ _use_doc_masking: true
与 Llama3 类似,我们在短上下文任务上没有观察到明显影响,只有 PIQA 有小幅提升。但在扩展到长序列以加速训练时,文档掩码就变得至关重要。这对我们的长上下文扩展尤其关键,我们会把上下文从 4k 扩展到 64k token(详见训练马拉松一章)。因此,我们在 SmolLM3 的完整训练过程中都采用了它。
本节我们讲了注意力如何处理序列。接下来看看 Transformer 里的另一个重要参数块:嵌入层。
嵌入层共享
如果你查看我们的基线消融模型配置,会发现与标准 Transformer 不同的一点是开启了 embedding sharing,由 tie_word_embeddings 这个标志控制。
LLM 有两类嵌入组件:输入嵌入,作为 token 到向量的转换表(大小为 vocab_size × hidden_dim),以及输出嵌入,即最后一层线性层,把隐状态映射到词表 logits(hidden_dim × vocab_size)。在经典设置里,这两者是独立矩阵,嵌入参数总数为 2 × vocab_size × hidden_dim。因此在小模型里,嵌入会占据很大一部分参数量,词表越大越明显。这让 embedding sharing(在输出层复用输入嵌入)成为小模型的自然优化选择。
较大的模型通常不会用这项技术,因为嵌入层只占其参数预算的一小部分。例如,不共享时,嵌入层在 Llama3.2 8B 中只占 13%,在 Llama3.1 70B 中只占 3%,如下方饼图所示。
消融实验 - 共享嵌入的模型可匹配更大的不共享版本
接下来我们评估 embedding sharing 对消融模型的影响。我们参考了 MobileLLM 在 125M 规模上对该技术的全面消融实验,他们表明共享嵌入能减少 11.8% 参数量,同时几乎不损伤准确率。
由于取消共享会把参数量从 1.2B 增加到 1.46B,我们将训练另一种不共享但层数更少的模型,使其参数量与基线 1.2B 匹配。我们将比较两个 1.2B 模型:我们的基线(共享嵌入、16 层)对比不共享但层数更少的版本(12 层)以保持相同参数预算;同时再加入一个 1.46B 的参考模型,不共享嵌入且层数与基线相同(16 层)。nanotron 配置在这里。
损失和评估结果表明,尽管参数量少了 18%,我们的 1.2B 共享嵌入基线在除 WinoGrande 外的所有基准上,都能与 1.46B 的不共享版本表现相当。相反,1.2B 的不共享且层数减少的模型(12 vs 16)在两种配置下都更差,损失更高、下游评估分数更低。这说明在相同参数预算下,增加模型深度带来的收益大于取消嵌入共享。
基于这些结果,我们在 SmolLM3 3B 模型中保留了共享嵌入。
我们已经讨论了嵌入共享策略及其权衡。但仅有嵌入无法表达序列中 token 的顺序,这部分信息由位置编码提供。在下一节,我们将看看位置编码策略如何演进:从标准的 RoPE 到 NoPE(No Position Embedding)等新方法,它们能更好地建模长上下文。
位置编码 & 长上下文
当 Transformer 处理文本时,会面临一个根本性挑战:由于它们通过并行注意力机制同时处理整个序列,自身并没有“词语先后顺序”概念。这带来高效训练,但也造成问题。没有明确的位置信息时,“Adam beats Muon”和“Muon beats Adam”在模型眼里几乎一样。
解决方案是位置嵌入:用数学编码为每个 token 赋予序列中的唯一“地址”。但随着上下文越来越长——从早期 BERT 的 512 token 到今天的百万级 token 模型——位置编码的选择对性能和计算效率都愈发关键。
位置编码的演进
早期 Transformer 使用简单的 绝对位置嵌入(APE) (Vaswani et al., 2023),本质是一个学习到的查表,将每个位置(1、2、3…)映射到向量并加到 token 嵌入上。短序列下效果不错,但有一个重大限制:模型的最大输入长度被限制在训练时的最大长度,无法开箱即用地泛化到更长序列。
随后研究转向 相对位置编码,它关注的是 token 之间的距离而非绝对位置。这更符合直觉:两个词相差 3 个位置,比它们处在 (5,8) 还是 (105,108) 更重要。
ALiBi(Attention with Linear Biases)(Press et al., 2022) 通过 token 距离来调整注意力分数。两个 token 越远,注意力权重上就施加越大的线性惩罚。想看 ALiBi 的实现细节可参考这份资料。
但近几年大语言模型里占主导地位的,是旋转位置编码 RoPE(Rotary Position Embedding)(Su et al., 2023)。
RoPE:用旋转表示位置
RoPE 的核心洞见是:把位置信息编码为高维空间里的旋转角度。它不是把位置向量加到 token 嵌入上,而是按 token 的绝对位置,对 query 和 key 向量进行旋转。
直觉上,我们把嵌入向量的每一对维度视作二维平面上的圆坐标,然后按以下因素决定旋转角度:
- token 在序列中的位置
- 当前处理的是哪一对维度(不同维度对的旋转频率不同,是某个基准频率的指数)
import torch
def apply_rope_simplified(x, pos, dim=64, base=10000):
"""
Rotary Position Embedding (RoPE)
Idea:
- Each token has a position index p (0, 1, 2, ...).
- Each pair of vector dimensions has an index k (0 .. dim/2 - 1).
- RoPE rotates every pair [x[2k], x[2k+1]] by an angle θ_{p,k}.
Formula:
θ_{p,k} = p * base^(-k / (dim/2))
- Small k (early dimension pairs) → slow oscillations → capture long-range info.
- Large k (later dimension pairs) → fast oscillations → capture fine detail.
"""
rotated = []
for i in range(0, dim, 2):
k = i // 2 # index of this dimension pair
# Frequency term: higher k → faster oscillation
inv_freq = 1.0 / (base ** (k / (dim // 2)))
theta = pos * inv_freq # rotation angle for position p and pair k
cos_t = torch.cos(torch.tensor(theta, dtype=x.dtype, device=x.device))
sin_t = torch.sin(torch.tensor(theta, dtype=x.dtype, device=x.device))
x1, x2 = x[i], x[i+1]
# Apply 2D rotation
rotated.extend([x1 * cos_t - x2 * sin_t,
x1 * sin_t + x2 * cos_t])
return torch.stack(rotated)
## Q, K: [batch, heads, seq, d_head]
Q = torch.randn(1, 2, 4, 8)
K = torch.randn(1, 2, 4, 8)
## 👉 apply RoPE to Q and K *before* the dot product
Q_rope = torch.stack([apply_rope(Q[0,0,p], p) for p in range(Q.size(2))])
K_rope = torch.stack([apply_rope(K[0,0,p], p) for p in range(K.size(2))])
scores = (Q_rope @ K_rope.T) / math.sqrt(Q.size(-1))
attn_weights = torch.softmax(scores, dim=-1)
这段代码看起来有些复杂,我们用一个具体例子拆解一下。句子 “The quick brown fox” 中的 “fox” 为例。在我们的 1B 基线模型里,每个注意力头使用 64 维的 query/key 向量。RoPE 会把它分成 32 对:(x₁, x₂)、(x₃, x₄)、(x₅, x₆) 等。之所以成对处理,是因为旋转发生在二维平面上。为简化说明,我们只看第一对 (x₁, x₂)。单词 “fox” 在句子中位于第 3 个位置,因此 RoPE 会把这一对维度旋转:
rotation_angle = position × θ₀
= 3 × (1/10000^(0/32))
= 3 × 1.0
= 3.0 radians
= 172° degrees
我们的基准频率是 10000,但对第一对维度(k=0)来说指数为 0,所以基准频率不会影响计算(因为任何数的 0 次方都是 1)。下图展示了这一过程:
当两个 token 通过注意力交互时,“魔法”才开始发生。它们旋转后的表示之间的点积,会通过旋转角度的相位差直接编码相对距离(其中 m 和 n 是 token 位置)
dot_product(RoPE(x, m), RoPE(y, n)) = Σₖ [xₖ * yₖ * cos((m-n) * θₖ)]
注意力模式只取决于 (m-n),因此相距 5 个位置的 token,无论它们在序列中的绝对位置如何,都会有相同的角度关系。于是模型学到的是基于距离的模式,可在任意绝对位置生效,并能外推到更长序列。
如何设置 RoPE 频率?
实践中,大多数 LLM 预训练从较短的上下文长度(2K-4K token)起步,并使用 10K 或 50K 这类数万级的 RoPE 基准频率。一开始就用很长序列训练会非常昂贵,因为注意力的计算复杂度随序列长度呈二次增长,而且长上下文数据(>4K token)也不充足——在注意力一节的文档掩码部分我们已经看到这一点。研究还表明,这可能伤害短上下文性能 (Zhu et al., 2025)。模型通常先学习词语间的短程相关性,所以一开始用长序列并不会带来太多收益。常见做法是先用短序列完成大部分预训练,然后再持续预训练,或在最后几千亿 token 上使用更长序列。但随着序列长度增长,与 token 位置成正比的旋转角会不断变大,可能导致远距离 token 的注意力分数衰减过快 (Rozière et al., 2024; Xiong et al., 2023):
θ = position x 1 / (base^(k/(dim/2)))
解决方案是随着序列长度增加,提高基准频率以防止衰减,可通过 ABF 和 YaRN 等方法实现。
RoPE ABF(Adjusted Base Frequency) (Xiong et al., 2023b):通过提高 RoPE 公式中的基准频率来解决长上下文下的注意力衰减问题。该调整会减缓不同位置间的旋转角变化,从而避免远距离 token 的注意力分数过快衰减。ABF 可一次性提升频率,也可分阶段随着上下文增长逐步提升。它实现简单,并以更高粒度分布嵌入向量,使模型更容易区分远距离位置。但由于对所有维度做统一缩放,极长上下文下可能并非最优。
YaRN(Yet another RoPE extensioN) (Peng et al., 2023):通过坡度/缩放函数对不同 RoPE 维度的不均匀插值来调整频率。不同于 ABF 的统一调整,YaRN 为不同频率分量应用不同缩放因子,优化扩展上下文窗口。它还加入动态注意力缩放与 attention logits 的温度调整,有助于在极长上下文中保持性能。YaRN 支持高效的“短训长测”策略,用更少 token 与更少微调实现稳健外推。虽然复杂度更高,但在极长上下文上通常表现更好,缩放更平滑且能缓解灾难性的注意力损失。它也可以仅在推理阶段使用,无需微调。
这些频率调整方法能减缓注意力分数的衰减,并维持远距离 token 的贡献。例如,Qwen3 训练时在序列长度从 4k 扩展到 32k 的过程中,用 ABF 把频率从 10k 提升到 1M(随后再用 YaRN 扩展到 131k,实现 4 倍外推)。需要注意的是,目前并没有统一的最优取值,共识是:在上下文扩展阶段最好尝试不同 RoPE 值,找到最适合你设置和评测基准的方案。
如今多数主流模型都使用 RoPE:Llama、Qwen、Gemma 等。它在不同规模与架构(Dense、MoE、Hybrid)上都验证了稳健性。下面看看近来出现的一些 RoPE 变体。
混合位置编码方案
然而随着模型迈向更长上下文 (Meta AI, 2025; Yang et al., 2025),即便是 RoPE 也开始遇到性能挑战。长上下文扩展时单纯提高 RoPE 频率,在比“海底捞针”(NIAH)(Kamradt, 2023) 更难的长上下文基准(如 Ruler 和 HELMET (Hsieh et al., 2024; Yen et al., 2025))上存在局限。于是出现了新的技术来应对。
本节开头我们说过,Transformer 需要位置信息来理解 token 顺序,但近期研究挑战了这一假设:如果根本不需要显式位置编码呢?
NoPE(No Position Embedding) (Kazemnejad et al., 2023):在不使用任何显式位置编码的情况下训练 Transformer,让模型通过因果掩码和注意力模式隐式学习位置信息。作者显示,该方法在长度泛化上优于 ALiBi 和 RoPE。由于不依赖显式位置编码去外推训练长度之外,NoPE 自然能处理更长上下文。但在实践中,NoPE 在短上下文的推理与知识任务上往往弱于 RoPE(Yang et al.)。这表明,虽然显式位置编码可能会限制模型的外推能力,但对于处于训练上下文长度范围内的任务,它们提供了有益的归纳偏置(Inductive Biases)。
RNoPE 混合方案: 在这些权衡下,@rnope 提出将不同位置编码策略结合起来。他们提出的 RNoPE 在模型层间交替使用 RoPE 和 NoPE。RoPE 层提供显式位置信息并带来局部最近性偏置,而 NoPE 层提升远距离信息检索能力。该技术最近被 Llama4、Command A 和 SmolLM3 采用。
为简化表述,本文后续将 RNoPE 统一称为 “NoPE”。(讨论中也常有人用 “NoPE” 指代 RNoPE。)
消融实验 - NoPE 在短上下文上可与 RoPE 持平
我们来测试这种混合 NoPE 方案。将 RoPE 作为 1B 消融实验基线,与每隔 4 层去掉位置编码的 NoPE 变体做对比,再加上第三种配置:NoPE + 文档掩码,用来检验两种技术的交互效果。核心问题是:能否在保持强短上下文性能的同时获得长上下文能力?
损失与评估结果显示三种配置表现相近,说明 NoPE 能维持强短上下文能力,同时为更好的长上下文处理打下基础。基于这些结果,我们在 SmolLM3 中采用了 NoPE + 文档掩码的组合。
部分/分段 RoPE: 另一个互补思路是只在模型维度的子集上应用 RoPE。不同于 RNoPE 在层级上交替 RoPE 与 NoPE,Partial RoPE 在同一层内部进行混合。近期模型如 GLM‑4.5 (5 Team et al., 2025) 或 Minimax-01 (MiniMax et al., 2025) 采用了这一策略,但更早的模型如 gpt-j (Wang & Komatsuzaki, 2021) 也使用过。在所有使用 MLA(多头潜在注意力)的模型中你都能看到这一点,因为它是实现合理推理成本的必备项。
MLA 通过“投影吸收”实现高效推理:它不再存储每个 head 的 key ,而是缓存一个小的共享潜变量 ,并合并 head 的 query/key 映射,使每个分数计算更便宜。设 , ,定义 ,则:
因此你用 与小型缓存 做计算(不再存储每个 head 的 k)。RoPE 会破坏这一点,因为它在两次映射之间插入了与维度对相关的旋转:在全维 RoPE 下,
因此无法把 与 预先合并成固定的 。解决办法:Partial RoPE。将 head 维度拆分为 ,在大块维度上不做旋转(像之前一样吸收: ),只在小块维度上应用 RoPE。
限制长上下文的注意力范围
到目前为止,我们已经讨论了长上下文的位置信息处理方式:启用 RoPE、禁用 RoPE(NoPE)、在部分层上启用(RNoPE)或在部分隐藏维度上启用(Partial RoPE),以及调节频率(ABF、YaRN)。这些方法通过改变位置编码来处理超过训练长度的序列。但还有一个互补思路:不改位置编码,而是限制哪些 token 彼此关注。
为了理解其重要性,请考虑一个使用 8 个标记(token)序列进行预训练的模型。在推理时,我们希望处理 16 个标记(超过了训练长度)。对于模型的位置编码而言,位置 8-15 属于‘分布外’(out of distribution)数据。虽然 RoPE ABF(调整基频)等技术通过调整位置频率来解决这一问题,但‘注意力范围方法’(attention scope methods)采取了不同的策略:它们有针对性地限制标记之间相互关注的范围,在处理完整序列的同时,将注意力模式保持在模型熟悉的范围内。这不仅降低了计算成本,还减少了内存需求。下图对比了在预训练窗口为 8 的情况下,处理 16 个标记序列的五种策略:
分块注意力(Chunked Attention) 将序列划分为固定大小的块,token 只能在各自块内相互关注。例子中,16 个 token 被分成两个 8 token 的块(0-7 与 8-15),每个 token 只能看到同块内的其他 token。注意 8-15 的 token 完全无法回看先前的块。这会形成在块边界重置的独立注意力窗口。Llama 4 (Meta AI, 2025) 在 RoPE 层(四分之三的解码器层)中使用了 8192 个标记规模的分块注意力,而 NoPE 层则保持了全上下文访问。这种做法通过限制每一层的 KV Cache 大小来降低内存需求,但这也意味着标记无法关注到之前的分块,可能会对某些长上下文任务产生影响。”
滑动窗口注意力(SWA),由 Mistral 7B (Child et al., 2019; Jiang et al., 2023) 推广,基于“最近 token 更相关”的直觉。不同于硬切块边界,每个 token 只关注最近的 N 个 token。图中每个 token 最多回看 8 个位置,形成沿序列连续移动的滑动窗口。注意 token 15 可关注位置 8-15,而 token 10 可关注位置 3-10。窗口不断向前移动,保留全序列的局部上下文,不会像分块那样形成硬边界。Gemma 3 在交替层中结合 SWA 与全注意力,类似于混合位置编码方案中的混合策略。
双块注意力(DCA) (An et al., 2024) 是一种无需训练的方法,扩展了 分块注意力 并保持跨块信息流。在示例中使用块大小 s=4,把 16 个 token 分成 4 块(可视为对角线上的 4×4 方块)。DCA 结合三种机制:(1) 块内注意力:token 在本块内正常注意(对角线模式);(2) 块间注意力:query 采用位置索引 c−1=7 来关注之前的块,使相对位置上限为 7;(3) 连续块注意力:用局部窗口 w=3 保持相邻块之间的局部性。这样所有相对位置都落在训练分布(0 到 7)内,同时保持跨块的平滑过渡。DCA 让 Qwen2.5 等模型在推理时支持高达 100 万 token 的超长上下文,而无需在百万 token 序列上持续训练。
长上下文 Transformer 中会出现一个有趣现象:模型会给序列开头的 token 分配异常高的注意力分数,即使这些 token 在语义上并不重要。这种行为称为 attention sinks(Xiao et al.)。这些初始 token 充当注意力分布的稳定机制,成为注意力可汇聚的“汇点”。
实践启示是:当上下文超过缓存大小时,只保留最开始少量 token 的 KV 缓存,并配合最近 token 的滑动窗口,就能在很大程度上恢复性能。这个简单改动让模型在不微调的情况下处理更长序列且不明显掉性能。
现代实现以不同方式利用 attention sinks。原始研究建议在预训练时加入一个专用占位 token 作为显式 attention sink。更近的做法是,像 gpt-oss 这样的模型把 attention sink 实现为每个 head 可学习的 bias logits,直接附加到注意力分数上,而不是真正加入输入 token。这样无需改动分词输入即可获得同样的稳定效果。
有意思的是,gpt-oss 还在注意力层本身使用了 bias 单元,这在 GPT-2 之后很少见。虽然这些 bias 单元通常被认为对标准注意力操作是多余的(Dehghani et al. 的实证结果显示对测试损失影响极小),但它们可以承担实现 attention sink 的专门功能。关键点是:无论通过特殊 token、可学习 bias,还是每个 head 的 logits,attention sink 都能在长上下文场景中为注意力分布提供稳定“锚点”,让模型即便在上下文无限增长时也能保留对全序列的通用信息。
至此我们覆盖了注意力的核心组件:在内存与算力间平衡的不同 head 配置(MHA、GQA、MLA),帮助模型理解 token 顺序的位置编码策略(RoPE、NoPE 及其变体),以及让长上下文可行的注意力范围技术(滑动窗口、分块与 attention sinks)。我们也讨论了嵌入层的配置与初始化。这些架构选择定义了模型如何处理并表示序列。
但正确的架构只是胜利的一半。即使设计良好的模型,在规模化训练时也可能出现不稳定。下面我们看看帮助训练保持稳定的技术。
提升稳定性
现在来看看 LLM 预训练中最大的挑战之一:不稳定性。它常表现为 loss 峰值或训练 loss 的突然跳变,在大规模训练中尤其常见。
我们会在 Training Marathon 章节更深入地讨论不同类型的峰值以及如何处理(涉及浮点精度、优化器与学习率),但一些架构与训练技巧也能降低不稳定性,我们在这里先快速过一遍。以下是近期大规模训练(如 Olmo2 (OLMo et al., 2025) 与 Qwen3 (Yang, Li, et al., 2025))中常用的几种简单稳定化手段:Z-loss、对嵌入层移除权重衰减,以及 QK-norm。
Z-loss
Z-loss (Chowdhery et al., 2022) 是一种正则化方法,通过在损失函数中加入惩罚项,防止最终输出 logits 过大。该正则项鼓励 logits 的 softmax 分母保持在合理范围内,有助于训练过程的数值稳定性。
我们在 1B 模型上的消融结果显示,加入 Z-loss 不会影响训练 loss 或下游性能。对于 SmolLM3,我们最终没有采用它,因为实现上的 Z-loss 带来了一定训练开销,而在开始训练前我们还没来得及优化。
移除嵌入层的权重衰减
权重衰减通常作为正则化手段应用于所有参数,但 OLMo et al. (2025) 发现,将嵌入层排除在权重衰减之外可以提升训练稳定性。原因在于权重衰减会让嵌入向量的范数在训练中逐步减小,而层归一化的雅可比与输入范数成反比,这会导致早期层的梯度变大 (Takase et al., 2025)。
我们测试了三种配置:标准权重衰减的基线、嵌入层不施加权重衰减的变体,以及把我们最终采用的改动组合在一起的配置(嵌入层无权重衰减 + NoPE + 文档级遮盖),以确保这些技术之间没有负面相互作用。三者的 loss 曲线与评测结果几乎一致,因此我们在 SmolLM3 训练中采用了这三项改动。
QKnorm
QK-norm (Dehghani et al., 2023) 在计算注意力前对 query 与 key 向量施加层归一化。该方法可防止注意力 logits 过大,并在许多近期模型中用于提升稳定性。
不过,@rnope 发现 QK-norm 会削弱长上下文任务表现。他们的分析表明,QK-norm 会降低对相关 token(needle)的注意力权重,同时提高对无关上下文的注意力权重。他们认为这是因为归一化移除了 query-key 点积中的幅度信息,使注意力 logits 的量级更接近。基于这一原因,我们没有在 SmolLM3 中使用 QK-norm。另外,SmolLM3 作为 3B 参数的小模型,相比那些从 QK-norm 中获益更多的大模型,面临的训练不稳定风险也更低。
其他核心组件
在我们已经覆盖的组件之外,还有几个架构层面的选择值得补充说明。
参数初始化方面,现代模型通常采用截断正态初始化(mean=0,std=0.02 或 std=0.006),或使用如 muP (G. Yang & Hu, 2022) 这样的初始化方案,例如 Cohere 的 Command A (Cohere et al., 2025)。这也是一个值得做消融实验的方向。
激活函数方面,SwiGLU 已成为现代 LLM 的事实标准(例外是 Gemma2 使用 GeGLU,以及 NVIDIA 使用 relu^2 (Nvidia et al., 2024; NVIDIA et al., 2025)),取代了较早的 ReLU 或 GELU。
在更宏观的层面,架构布局也会影响模型行为。虽然总参数量在很大程度上决定了语言模型的容量,但这些参数在深度与宽度上的分配同样重要。@petty2024impactdepthcompositionalgeneralization 发现,在语言建模与组合性任务上,深度更深的模型会优于同规模的更宽模型,直到收益趋于饱和。这种“深而窄”的策略在 MobileLLM 的消融中对十亿级以下的 LLM 尤其有效 (Z. Liu et al., 2024),而更宽的模型往往由于更高的并行性而带来更快的推理速度。现代架构对这一权衡的取舍各不相同,详见这篇博客文章。
到这里,我们已经覆盖了密集 Transformer 架构中最值得优化的核心部分。不过近来还出现了更针对整体模型的架构改动,主要是 MoE 与混合模型。下面我们从 MoE 开始看看它们能带来什么。
走向稀疏:MoE
Mixture-of-Experts(MoE) 的直觉很简单:并不是每个 token 的预测都需要整套模型,就像大脑会根据任务激活不同区域(例如视觉或运动皮层)。对于 LLM,这意味着学会了代码语法的部分,在进行翻译任务时未必需要被调用。如果路由做得好,就能在推理时只运行模型的一部分,从而节省大量计算。
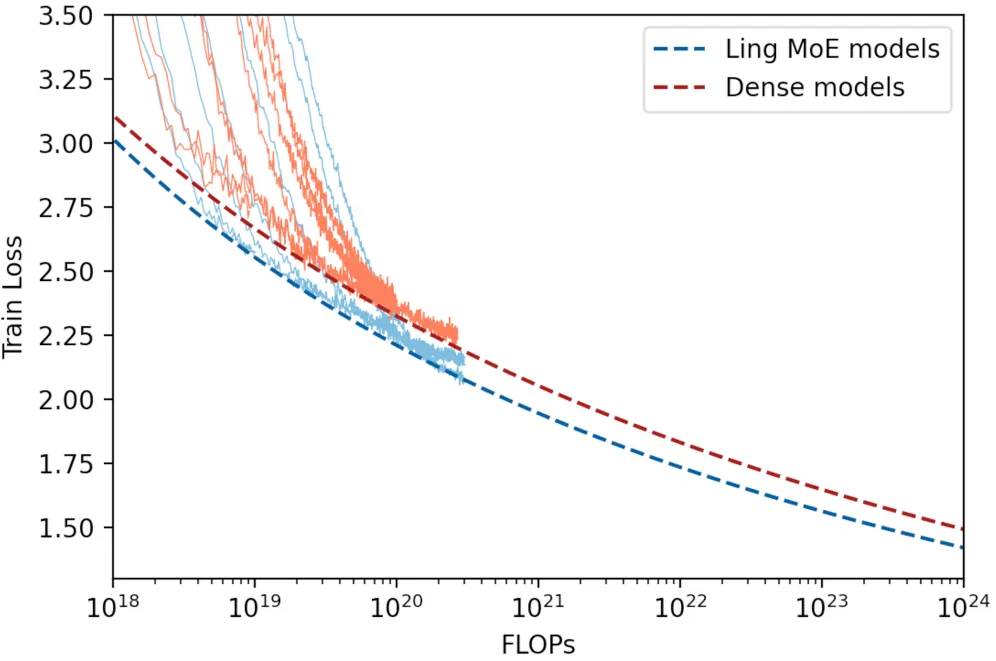
从技术角度看,MoE 的目标也很清晰:在不增加每个 token “激活参数”数量的前提下,提升总参数量。简单来说,总参数量决定模型的总体学习容量,而激活参数决定训练成本与推理速度。这也是为什么如今许多前沿系统(如 DeepSeek V3、K2,以及闭源模型 Gemini、Grok 等)都在使用 MoE 架构。下面这张来自 Ling 1.5 论文 (L. Team et al., 2025) 的图对比了 MoE 与稠密模型的缩放规律:
如果你第一次接触 MoE,不用担心,它的机制并不复杂。我们从标准的稠密架构开始,看看 MoE 需要做哪些改动(图来自 Sebastian Raschka):
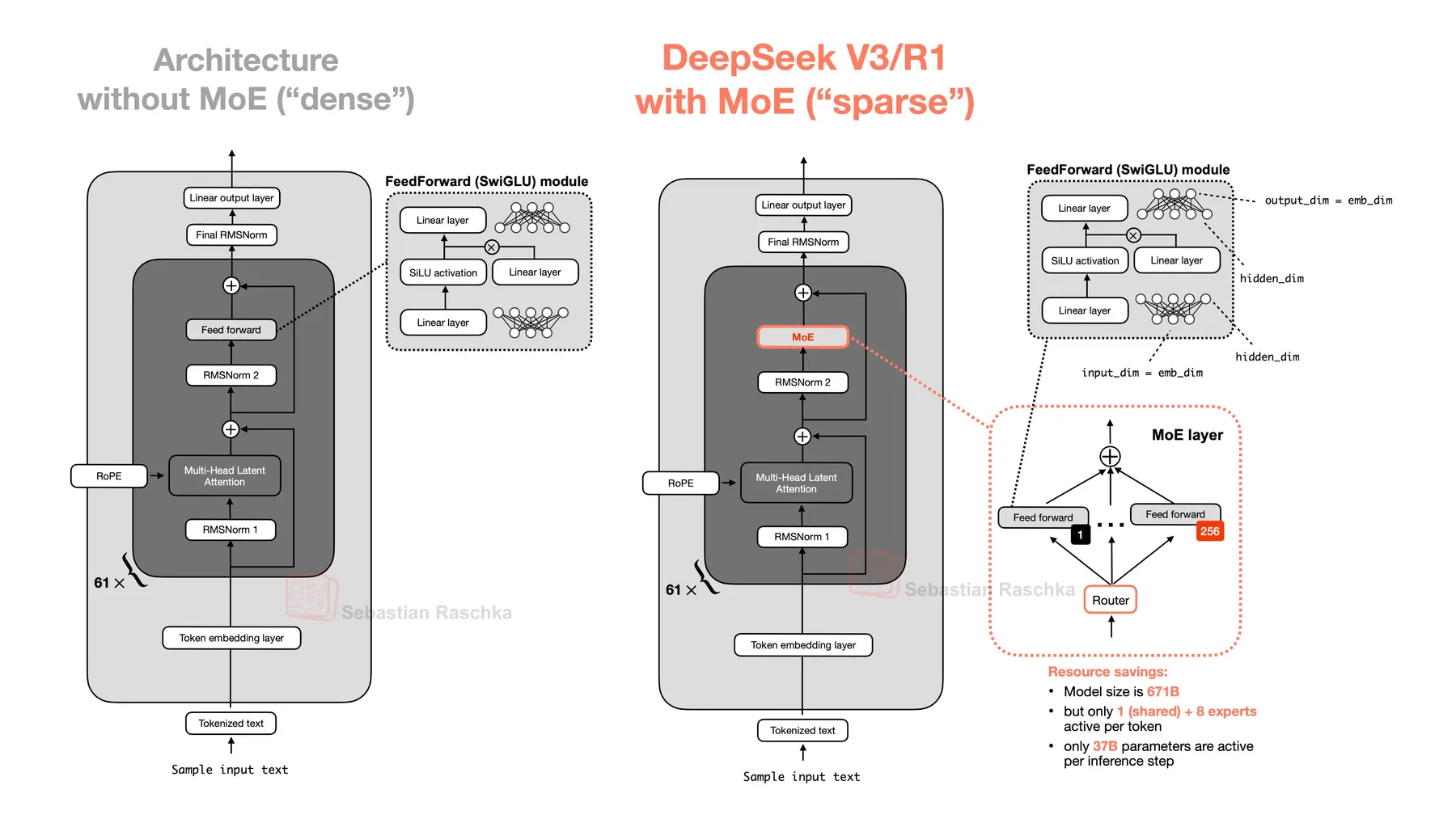
在 MoE 中,我们把单个 MLP 替换为多个 MLP(“专家”),并在它们之前加入一个可学习的路由器。对于每个 token,路由器只选择一小部分专家执行。这就是总参数与激活参数的区别来源:模型有很多专家,但任何一个 token 实际只会使用其中几个。
设计 MoE 层会引出几个核心问题:
- 专家形状与稀疏度:是使用大量小专家,还是少量大专家?每个 token 应激活多少专家、总共需要多少专家(即稀疏度或 “top-k”)?是否需要一些通用专家始终保持激活?
- 利用率与专门化:如何选择被路由的专家,让它们被充分使用(避免闲置容量)同时又能形成专门化?在实践中这就是负载均衡问题,对训练与推理效率影响很大。
这里我们聚焦一个目标:在固定算力预算下,如何选择 MoE 配置以最小化 loss?这与纯粹的系统效率(吞吐/延迟)是不同的问题,我们稍后会再讨论。以下内容主要基于蚂蚁集团的 MoE scaling laws 分析 (Tian et al., 2025)。
我们会使用他们提出的 Efficiency Leverage(EL) 概念。简单来说,EL 衡量的是:要达到某个 MoE 设计的 loss,稠密模型需要多少计算量(以 FLOPs 为单位)。EL 越高,说明该 MoE 配置在单位算力下带来的 loss 改善越多。
下面我们更细致地看看,如何通过设置 MoE 的稀疏度来提升效率杠杆。
稀疏度 / 激活比例
TL;DR: 稀疏度更高 → FLOPs 效率更好 → 极高稀疏度收益递减 → 最佳点取决于算力预算。
本节我们想回答哪个 MoE 设置最好。从极限来看,两端都不是理想方案:一端是始终激活所有专家,等同于稠密模型;另一端是激活参数极少(极端情况下只有一个参数被激活),显然连狭窄领域任务都难以胜任。因此我们需要寻找中间地带。在深入讨论之前,先定义两个量:激活比例 及其倒数 稀疏度 :
从算力角度看,成本只由激活参数决定。如果保持激活专家的数量(及大小)不变,同时增加专家总数,那么推理/训练 FLOPs 预算大致不变,但模型容量增加,因此只要训练足够久,模型整体会更好。
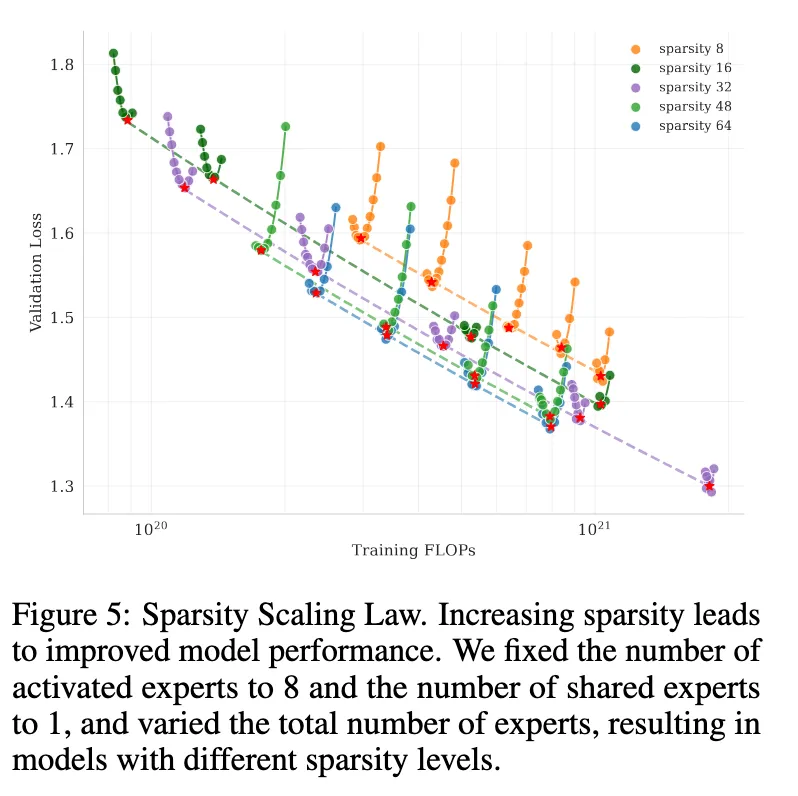
回顾近期 MoE 论文,有一些清晰的经验结论:在激活专家的数量与规模固定的情况下,增加专家总数(即降低激活比例/提高稀疏度)会带来更好的 loss,但当稀疏度很高时收益会递减。
两个例子:
- Kimi K2 图 (K. Team et al., 2025):展示了两种效应,稀疏度更高性能更好,但随着稀疏度增加收益逐渐变小。
- Ant Group 图 (Tian et al., 2025):与 K2 结论一致,并补充了一个结果:稀疏度更高的 MoE 受益于增加算力更明显。
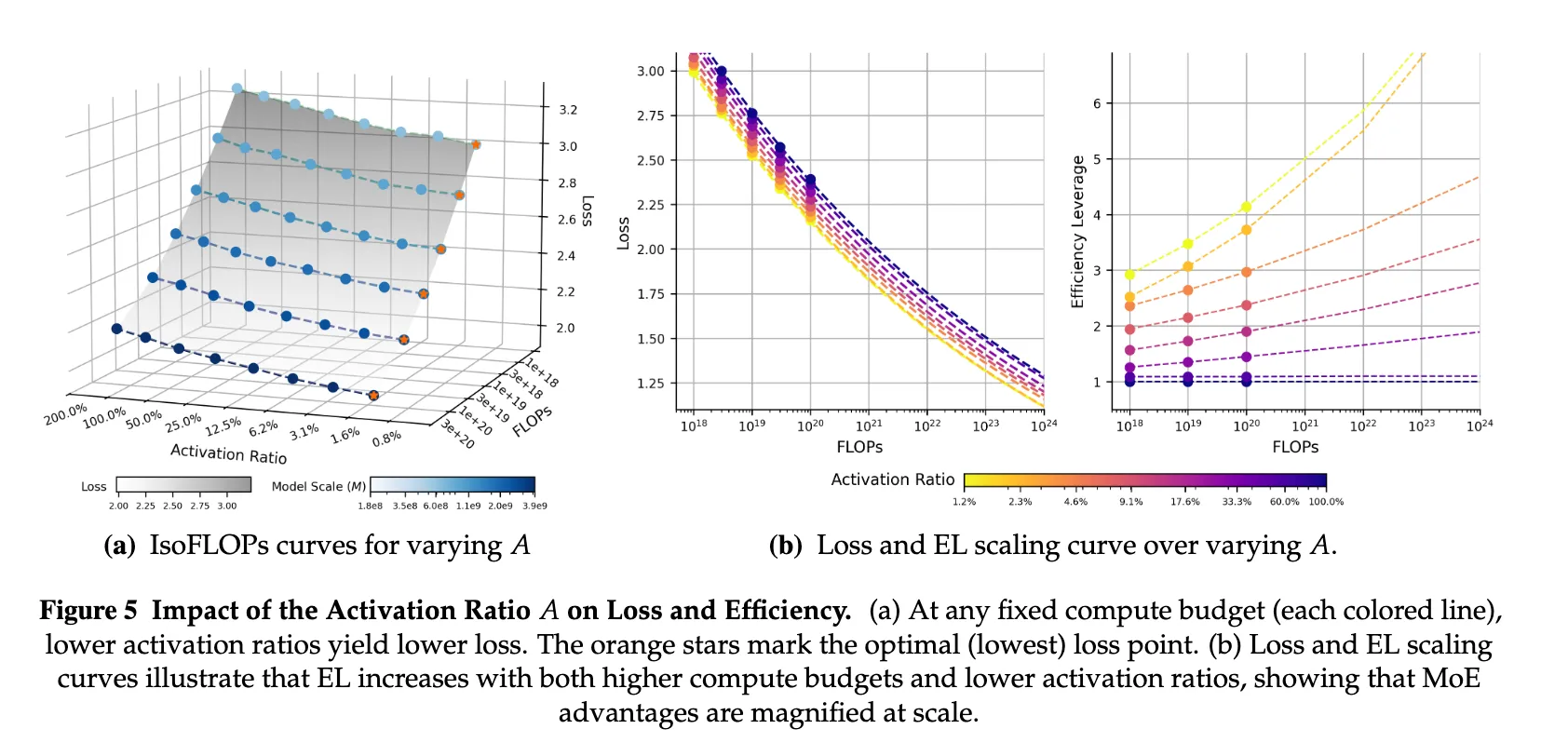
下面是一些 MoE 模型的稀疏度表:
| Model | Total experts | Activated per token (incl. shared) | Sparsity |
|---|---|---|---|
| Mixtral-8×7B | 8 | 2 | 4.0 |
| Grok-1 | 8 | 2 | 4.0 |
| Grok-2 | 8 | 2 | 4.0 |
| OLMoE-1B-7B-0924 | 64 | 8 | 8.0 |
| gpt-oss 20b | 32 | 4 | 8 |
| Step-3 | 48 routed + 1 shared = 49 | 3 routed + 1 shared = 4 | 12.25 |
| GLM-4.5-Air | 128 routed + 1 shared = 129 | 8 routed + 1 shared = 9 | 14.3 |
| Qwen3-30B-A3B | 128 | 8 | 16.0 |
| Qwen3-235B-A22B | 128 | 8 | 16.0 |
| GLM-4.5 | 160 routed + 1 shared = 161 | 8 routed + 1 shared = 9 | 17.8 |
| DeepSeek-V2 | 160 routed + 2 shared = 162 | 6 routed + 2 shared = 8 | 20.25 |
| DeepSeek-V3 | 256 routed + 1 shared = 257 | 8 routed + 1 shared = 9 | 28.6 |
| gpt-oss 120b | 128 | 4 | 32 |
| Kimi K2 | 384 routed + 1 shared = 385 | 8 routed + 1 shared = 9 | 42.8 |
| Qwen3-Next-80B-A3B-Instruct | 512 routed + 1 shared = 513 | 10 total active + 1 shared = 11 | 46.6 |
近期趋势很明确:MoE 模型越来越稀疏。但最佳稀疏度仍取决于硬件与端到端效率。例如,Step-3 追求峰值效率,刻意不把稀疏度拉满,以适配特定硬件与带宽约束;而 gpt-oss-20b 因为设备内存限制而保持较低稀疏度(未激活专家仍会占用部分内存)。
粒度(Granularity)
除了稀疏度之外,我们还需要决定每个专家应该有多大。这可以用蚂蚁集团提出的“粒度”指标来刻画。不同论文的术语与公式略有差异,这里我们采用与引用图一致的定义:
在参数总量固定时,更高的粒度意味着更多、但更小的专家。该指标是专家维度( )与模型维度( )之间的比值。
在稠密模型中,一个常见经验是将 MLP 维度设为 。当 时(如 @krajewski2024scalinglawsfinegrainedmixture),可以把粒度粗略理解为 需要多少个专家才能匹配稠密 MLP 的宽度( )。
这个解释只是粗略的启发式:现代 MoE 设计往往分配了远超单个稠密 MLP 的总容量,因此一一对应在实践中并不成立。蚂蚁团队选择 ,只是另一种归一化选择。为保持一致性,我们也采用这一约定。
下面仍给出一些 MoE 发布模型的粒度数值:
| Model | Year | |||
|---|---|---|---|---|
| Mixtral-8×7B | 4,096 | 14,336 | 0.571 | 2023 |
| gpt-oss-120b | 2880 | 2880 | 0.5 | 2025 |
| gpt-oss-20b | 2880 | 2880 | 0.5 | 2025 |
| Grok 2 | 8,192 | 16,384 | 1.0 | 2024 |
| StepFun Step-3 | 7,168 | 5,120 | 2.8 | 2025 |
| OLMoE-1B-7B | 2,048 | 1,024 | 4.0 | 2025 |
| Qwen3-30B-A3B | 2,048 | 768 | 5.3 | 2025 |
| Qwen3-235B-A22B | 4,096 | 1,536 | 5.3 | 2025 |
| GLM-4.5-Air | 4,096 | 1,408 | 5.8 | 2025 |
| DeepSeek V2 | 5,120 | 1,536 | 6.6 | 2024 |
| GLM-4.5 | 5,120 | 1,536 | 6.6 | 2025 |
| Kimi K2 | 7,168 | 2,048 | 7.0 | 2025 |
| DeepSeek V3 | 7168 | 2048 | 7.0 | 2024 |
| Qwen3-Next-80B-A3B | 2048 | 512 | 8.0 | 2025 |
下面看看粒度如何影响模型行为(来自 Ant Group 论文):
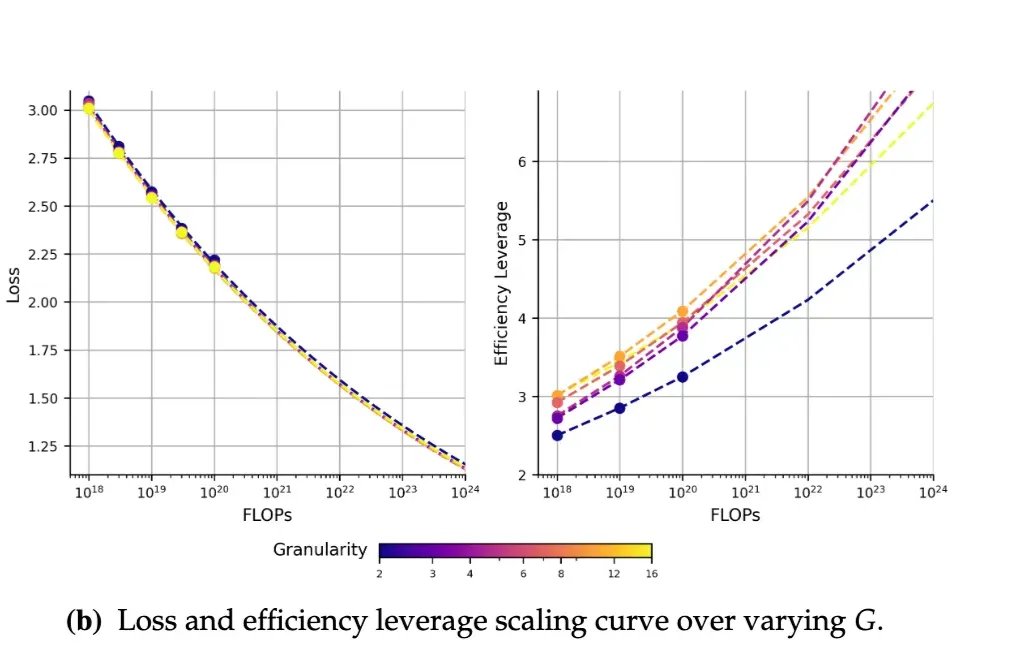
粒度看起来不是影响 EL 的主要驱动因素——它确实有帮助,尤其是高于 2 时,但并不是决定 loss 的主导变量。不过仍有一个甜点区间:粒度提高到一定程度后收益会趋于平缓。因此,粒度是一个有用的调节旋钮,近期发布模型也有趋向更高粒度的趋势,但不应单独优化它。
另一种广泛用于改进 MoE 的方法是“共享专家”。我们来看看它的作用。
共享专家
共享专家的做法是:把每个 token 都路由到一小组始终激活的专家。这些共享专家负责吸收数据中基础且重复的模式,使其他专家能更激进地专门化。实践中你不需要很多共享专家,模型设计者通常只用一个,最多两个。随着粒度增加(例如从 Qwen3 风格走向更接近 Qwen3-Next 的设定),共享专家往往更有用。从下面的图看,整体影响不算大,对 EL 的提升有限。一个简单且好用的经验法则是:只用一个共享专家,这与 DeepSeek V3、K2、Qwen3-Next 等模型的选择一致,通常能在不增加不必要复杂度的前提下最大化效率。图来自 Tian et al. (2025)。
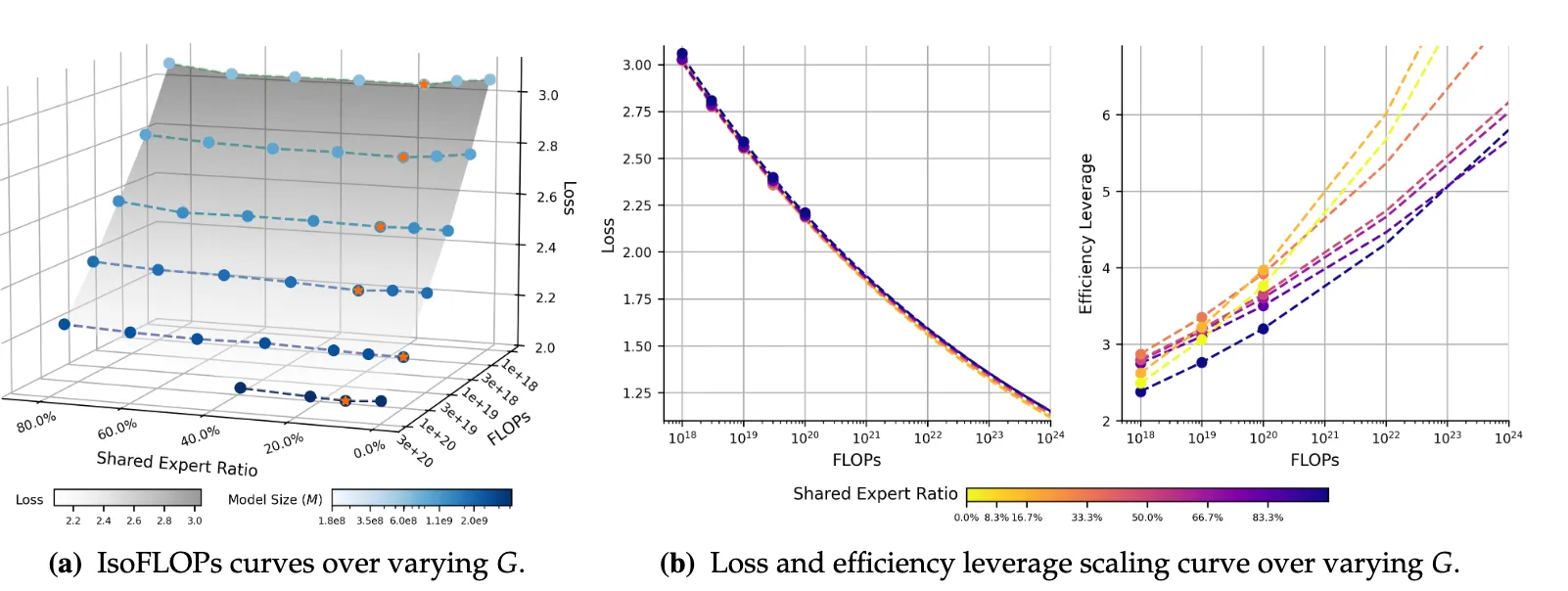
共享专家就是一类始终会被部分 token 路由到的专家。那么其他专家怎么办?我们如何学习将 token 路由到不同专家,同时避免只使用少数几个专家?接下来我们讨论负载均衡,它正是为了解决这个问题。
负载均衡
负载均衡是 MoE 的关键环节。如果做得不好,其他所有设计选择都会被削弱。举个简单例子:假设我们有 4 张 GPU,把 4 个专家均匀分配到这些 GPU 上。如果路由发生坍缩,所有 token 都被送到专家 1,那么只有 1/4 的 GPU 被利用,训练与推理效率极差。同时,由于并非所有专家都被激活,模型的有效学习容量也降低了。
为了解决这个问题,我们可以在路由器上加入额外的损失项。下面是标准的基于辅助损失的负载均衡(LBL):
这个公式只包含三个因素:系数 决定损失强度; 是流量占比,即经过专家 的 token 比例; 是概率质量,等于所有 token 经过该专家的概率之和。二者都很重要: 反映真实的均衡情况,而 是平滑可导的,便于梯度传播。若实现完美均衡,则 。但 需要谨慎调节:太小无法有效引导路由,太大则会让路由均匀性压过主语言模型的 loss。
也可以在没有显式损失项的情况下实现均衡。DeepSeek v3 (DeepSeek-AI et al., 2025) 在路由 softmax 的亲和度分数上加入一个简单的偏置项:如果某个专家过载,就把它的分数下调一点(常数 ),让它更不容易被选中;若某专家利用不足,则把分数上调 。这个简单的自适应规则也能实现负载均衡。
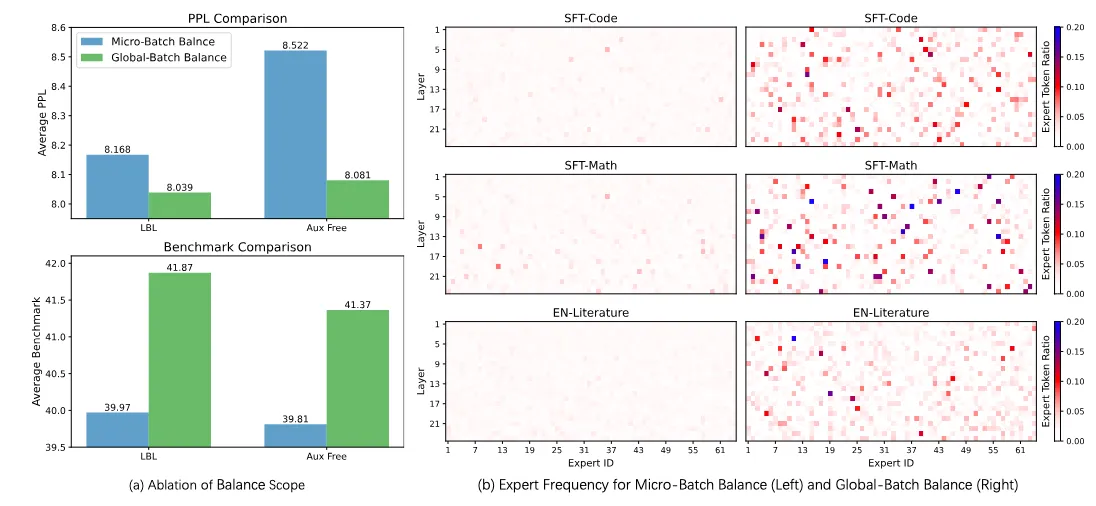
一个关键细节是路由统计的计算范围: 和 是按本地 batch(每个 worker 的 mini-batch)计算,还是全局计算(跨设备汇总)?Qwen 团队的分析 (Qiu et al., 2025) 表明,当本地 batch 的 token 多样性不足时,本地统计会损害专家专门化(它是路由健康状况的良好代理)以及整体模型性能。所谓专家专门化,是指某些专家在特定领域被更频繁地激活。换言之,如果本地 batch 过窄,它的路由统计会变得噪声大且偏置,从而无法形成良好均衡。这意味着在可行时应使用全局统计(或至少跨设备聚合)。值得注意的是,该论文发表时,包括 Megatron 在内的许多框架默认都使用本地统计。
下图来自 Qwen 论文,展示了 micro-batch 与 global batch 聚合的差异及其对性能与专门化的影响:
总体来说,围绕 MoE 的架构选择做消融并不容易,因为它与许多因素存在相互作用。例如,共享专家是否有用可能取决于模型的粒度。因此,值得花些时间设计好实验组合,才能真正得到你想要的洞见。
我们已经覆盖了 MoE 的基础要点,但仍有许多值得探索的方向。下面是一个不完全列表:
-
零计算专家、MoE 层重缩放与训练监控(LongCat-Flash 论文)。
-
正交损失负载均衡(如 ERNIE 4.5)。
-
训练中对负载均衡系数的调度。
-
MoE 与架构/优化的相互作用,例如:
- 优化器排名是否会因 MoE 改变。
- 如何将 MuP 应用于 MoE。
- 如何调整 MoE 的学习率(因为每个 batch 看到的 token 数量不同)。
-
开头稠密层的数量。
-
以及更多。
我们把更深入的“兔子洞”留给有兴趣的读者探索,接下来我们转向最后一个主要架构选择:混合模型!
专题讨论:混合模型
最近的一个趋势是,在标准的 dense 或 MoE 架构中加入状态空间模型(SSM)或线性注意力机制 (MiniMax et al., 2025; Zuo et al., 2025)。**这些新模型类别试图解决 Transformer 的一些基础弱点:如何高效处理超长上下文。它们介于循环模型与 Transformer 之间:循环模型能高效处理任意长度上下文并线性扩展,但可能难以充分利用上下文信息;而 Transformer 在长上下文下成本极高,却能很好地利用上下文模式。
一些研究 (Waleffe et al., 2024) 试图理解例如 Mamba 模型(SSM 的一种)的弱点,发现这类模型在许多基准上表现不错,但是像在 MMLU 上表现不佳,并推测差距来自缺乏 情景学习能力(in-context learning)。这也是它们与 dense 或 MoE 模块组合、取长补短的原因,因此称为混合模型。
这些线性注意力方法的核心思想是重排计算,使注意力不再是 O(n^2d) 的成本,避免在长上下文下变得不可承受。怎么做到的?先回忆推理时的注意力公式。生成 token t 的输出为:
现在去掉 softmax:
重排得到:
定义运行态:
并使用简单的更新:
因此可写为:
为什么重排很重要:左边形式 表示“对每个过去的 token j 计算点积 (标量),用它缩放 ,再把这 t 个向量相加”,在 t 次的工作量约为 。右边形式把它改写为 :你维护一个运行态矩阵 ,它已经汇总了所有过去的 。每来一个新 token,用一次外积 更新它,成本 ,然后输出只是一次矩阵-向量乘 (同样是 )。所以从头用左边形式生成 T 个 token 是 ,而维护 并用右边形式是 。直观上:左边是“每一步很多小的点积-缩放-相加”;右边是“一个预先汇总的矩阵乘查询”,用对维度的依赖换掉对序列长度的依赖。这里我们聚焦推理和递推形式,但在训练中也更高效,重排只需下面的等式:
所以可以看到它现在很像 RNN 的结构。这就解决问题了吗?几乎如此。在实践中,softmax 起到重要的稳定作用,朴素的线性形式如果没有归一化可能不稳定。这就引出了一个更实用的变体:Lightning Attention 或 Norm Attention!
Lightning and norm attention
这一家族出现在 Minimax01 (MiniMax et al., 2025) 以及更近期的 Ring-linear (L. Team, Han, et al., 2025) 中,建立在 Norm Attention 的思路之上 (Qin et al., 2022)。关键一步很简单:对输出做归一化。Lightning 变体强调实现上的高速与高效,并让公式略有不同。两者公式如下:
NormAttention:
LightningAttention:
根据 Minimax01 的实证结果,使用 Norm attention 的混合模型在大多数任务上与 softmax 表现相当。
有意思的是,在 Needle in a Haystack(NIAH)这类检索任务上,它能远超完整 softmax 注意力,这看起来有些反直觉,但可能说明 softmax 与线性层协同工作时存在某种增益!
令人惊讶的是,最近发布的 MiniMax M2 并未采用混合或线性注意力。根据他们的 预训练负责人所述,早期 MiniMax M1 在较小规模上用 Lightning Attention 做实验时,在当时流行的基准(MMLU、BBH、MATH)上看起来很有希望,但在更大规模上发现其在“复杂、多跳推理任务”上存在明显短板。他们还指出 RL 训练中的数值精度问题与基础设施成熟度是关键阻碍。他们的结论是:在规模化场景中做架构选择是一个多变量、计算成本很高的问题,因为它对数据分布、优化器等参数都很敏感……
不过,他们也承认“随着 GPU 计算增长放缓而数据长度持续增长,线性与稀疏注意力的优势将逐步显现”。这同时突显了架构消融的复杂性,以及研究与生产现实之间的差距。
现在我们再看一些相关方法,以及如何用统一框架来理解它们。
Advanced linear attention
从循环模型得到的一个有用经验是,让状态偶尔“放下”过去。在实践中,这意味着为上一时刻的状态引入门控 :
几乎所有近期的线性注意力方法都有这个门控组件,只是对 的实现不同。来自 这篇论文 的表格列出了不同的门控变体及其对应架构:
| Model | Parameterization | Learnable parameters |
|---|---|---|
| Mamba (A. Gu & Dao, 2024) | ||
| Mamba-2 (Dao & Gu, 2024) | ||
| mLSTM (Beck et al., 2025; H. Peng et al., 2021) | ||
| Gated Retention (Sun et al., 2024) | ||
| DFW (Mao, 2022; Pramanik et al., 2023) (Mao, 2022) | ||
| GateLoop (Katsch, 2024) | ||
| HGRN-2 (Qin et al., 2024) | ||
| RWKV-6 (B. Peng et al., 2024) | ||
| Gated Linear Attention (GLA) |
其中一个值得注意的变体是 Mamba-2 (Dao & Gu, 2024)。它被用于许多混合模型,例如 Nemotron-H (NVIDIA, :, Blakeman, et al., 2025)、Falcon H1 (Zuo et al., 2025) 和 Granite-4.0-h (IBM Research, 2025)。
不过这仍处于早期阶段,扩展到大型混合模型时有很多细微差别需要考虑。尽管前景可期,MiniMax 在 M2 的经验表明,小规模收益并不一定能转化为大规模生产系统的收益,尤其在复杂推理任务、RL 训练稳定性以及基础设施成熟度方面。即便如此,混合模型的发展很快,依然是前沿训练的稳健选择。Qwen3-Next(带门控的 DeltaNet 更新)(Qwen Team, 2025) 报告称在长上下文推理更快、训练更快、在常见基准上更强。我们也期待 Kimi 的下一代模型,很可能使用其新的 “Kimi Delta Attention”。此外也要提到稀疏注意力,它通过选择 block 或 query 计算注意力来解决线性注意力同样的长上下文问题。例子包括 Native Sparse Attention (Yuan et al., 2025)、DeepSeek Sparse Attention (DeepSeek-AI, 2025) 和 InfLLM v2 (M. Team, Xiao, et al., 2025)。
在转向 tokenizer 之前,我们会用一个小的决策树来收束架构选择,判断是训练 dense、MoE 还是混合模型。
To MoE or not MoE: 选择基本架构
我们已经看过 dense、MoE 和混合模型,所以你可能自然会好奇:该选哪一个?你的架构选择通常取决于模型的部署场景、团队的经验,以及时间窗口。下面我们简要概览各架构的优缺点,并给出一个简单的指引流程,帮助你做出合适选择。
Dense transformers 是最基础的标准 decoder-only transformer,每个 token 都会激活所有参数。数学推导可参考 The Annotated Transformers,直观理解可参考 The Illustrated Transformers。
优点:生态支持广、理解成熟、训练稳定、单位参数性能好。
缺点:计算量随规模线性增长,70B 模型的成本约为 3B 的 ~23×。
这通常是内存受限场景或新手训练 LLM 的默认选择。
Mixture of Experts (MoE) 将 Transformer 的前馈层替换为多个“专家”。对每个 token,门控网络只路由到少数专家,因此可以用一小部分计算获得大模型的容量。比如 Kimi K2 的总参数为 1T,但每个 token 仅激活 32B。代价是必须把所有专家都加载到内存中。可视化理解可参考 这篇博客。
优点:训练与推理的单位计算性能更好。
缺点:内存占用高(必须加载所有专家);训练比 dense 更复杂;框架支持在改善但不如 dense 成熟;分布式训练在专家放置、负载均衡、以及 all-to-all 通信上非常棘手。
当你不受内存限制,且希望单位计算性能最大化时使用。
Hybrid models 将 Transformer 与 Mamba 等状态空间模型(SSM)结合,在部分操作上提供线性复杂度,从而规避注意力的二次增长。(Mathy blog | Visual guide)
优点:可能更擅长长上下文;对超长序列更高效。
缺点:成熟度不如 dense 与 MoE,经过验证的训练配方更少;框架支持有限。
当你希望扩展到超大上下文,同时降低标准 Transformer 推理开销时使用。
总结一下,先问清楚模型会部署到哪里,再结合团队经验和训练周期,评估你能承担多少探索成本:
以 SmolLM3 为例,我们要做的是面向端侧部署的高质量小模型,时间大约只有 3 个月,且团队过去主要训练 dense 模型。于是我们排除了 MoE(内存限制)与混合模型(探索新架构的时间不足;而 dense 也能达到我们目标的 128k 最大上下文),最终选择了 Llama 风格的 dense 模型。
既然我们已经了解了模型架构的内部机制,接下来看看 tokenizer,它是数据与模型之间的桥梁。
分词器
虽然分词器很少比架构创新更耀眼,但它可能是任何语言模型中最被低估的组件之一。把它想象成在人类语言与模型的数学世界之间的翻译器,翻译质量对最终效果有很大影响。那么我们应如何为自己的需求构建或选择合适的分词器?
分词器基础
分词器的核心任务是将原始文本切分并映射为模型可处理的数字序列(token)。在深入技术细节前,先回答几个会影响分词器设计的基本问题:
- 我们要支持哪些语言? 如果打算做多语言模型,但分词器只基于英语训练,那么遇到非英语文本时会被切割成更多 token,直接影响性能、训练成本与推理速度。
- 哪些领域是重点? 数学与代码等领域对数字与符号的表示要特别谨慎。
- 我们是否知道目标数据的混合比例? 若从零训练分词器,应尽量用接近最终训练混合的样本来训练分词器。
明确这些后,再看主要设计抉择:
词表大小
词表相当于模型认识的“词典”——所有最小可处理单元(词、子词或符号)。
更大的词表能更高效压缩文本(每句话生成的 token 更少),但代价是嵌入矩阵变大:词表大小 V 与隐藏维度 h 决定了输入嵌入参数 V×h(输出层同理)。对小模型来说,嵌入会占据明显比例;模型越大,这部分占比越小。
合适的词表大小取决于覆盖需求和模型规模:英语模型常见在 ~50k;多语言模型常需 100k+。许多最新 SOTA 模型(如 Llama3)采用 128k+ 的词表以提升多语种效率。对小模型可用嵌入共享(embedding sharing)来减轻大词表带来的参数增长。 Dagan et al. (2024) 分析了词表大小对压缩率、推理与内存的影响。他们发现更大的词表带来的压缩收益呈指数递减,说明存在一个最优规模。就推理而言,大模型更能从大词表中受益,因为压缩带来的前向计算节省超过了 softmax 中额外嵌入 token 的成本。就内存而言,最优词表大小与序列长度和 batch size 相关:更长的上下文和更大的 batch 往往能从更大词表中获益,因为 token 更少会带来更小的 KV cache。
分词算法
BPE (Byte-Pair Encoding) (Sennrich et al., 2016) 依然是最常用的方案,WordPiece 或 SentencePiece 也常见。研究方向上有尝试直接以字节或字符为单位、免去分词器的方案,但目前主流仍以子词算法为主。
在了解了决定分词器的关键参数后,我们要做一个实际决策:使用现成的分词器,还是从零训练?答案取决于覆盖度:现有分词器在我们期望的词表大小下,是否能很好覆盖我们的语言与领域。
下图对比了 GPT-2 的英文分词器 (Radford et al., 2019) 与 Gemma 3 的多语分词器 (G. Team, Kamath, et al., 2025) 在同一条英语与阿拉伯语句子上的切分方式。
两者在英语上的效果相近,但在阿拉伯语上差异非常明显:GPT2 会把文本切成一百多个碎片,而 Gemma3 因为使用了多语训练数据和更大、更包容的词表,产生的 token 要少得多。
但要衡量分词器的质量,不能只靠“看起来还不错”的几个例子——就像我们不会在没有消融实验的情况下凭直觉改架构一样。我们需要明确的指标来评估分词器的质量。
衡量分词器质量
评估分词器效果时,我们可以使用 FineWeb2 (Penedo et al., 2025) 中的两项关键指标。
Fertility:
它衡量编码一个“词”平均需要多少个 token。Fertility 越低,压缩率越高,训练与推理也更快。可以这样理解:如果一个分词器在大多数词上多用一到两个 token,而另一个用得更少,那么后者明显更高效。
衡量 fertility 的标准方法是计算 words-to-tokens ratio(词级 fertility),也就是平均每个词需要多少 token。之所以围绕“词”来定义,是因为当有合适的分词工具时(如 Spacy 与 Stanza (Penedo et al., 2025)),它能提供有意义的跨语言比较。
在单一语言内比较分词器时,也可以用字符或字节代替词,得到字符/字节到 token 的比率 (Dagan et al., 2024)。但这些指标在跨语言比较时有限制。字节数会因为脚本不同而偏斜(例如 UTF-8 中汉字占 3 个字节,而拉丁字符只占 1–2 个字节)。同样,字符数量无法体现不同语言词长差异,例如中文词通常比德语复合词短得多。
Proportion of continued words(续分词比例):
该指标衡量有多少比例的词被切成多个片段。比例越低越好,因为被拆分的词更少,分词更高效。
下面实现这些指标:
import numpy as np
def compute_tokenizer_metrics(tokenizer, word_tokenizer, text):
"""
Computes fertility and proportion of continued words.
Returns:
tuple: (fertility, proportion_continued_words)
- fertility: average tokens per word (lower is better)
- proportion_continued_words: percentage of words split into 2+ tokens (lower is better)
"""
words = word_tokenizer.word_tokenize(text)
tokens = tokenizer.batch_encode_plus(words, add_special_tokens=False)
tokens_per_word = np.array(list(map(len, tokens["input_ids"])))
fertility = np.mean(tokens_per_word).item()
proportion_continued_words = (tokens_per_word >= 2).sum() / len(tokens_per_word)
return fertility, proportion_continued_words
不过在代码、数学等专业领域,仅看 fertility 还不够,我们还要关注分词器对领域特定模式的处理能力。多数现代分词器会把数字拆成单个数字(例如把 “123” 拆成 [“1”, “2”, “3”])(Chowdhery et al., 2022; DeepSeek-AI et al., 2024)。这看似反直觉,但其实有助于模型学习算术规律。如果把 “342792” 编成一个不可再分的 token,模型就得记住它与每个数字 token 做加减乘时的结果;而拆分后,模型能学到数字级的运算规律。一些分词器如 Llama3 (Grattafiori et al., 2024) 会把 1 到 999 编成独立 token,其余数字由这些 token 组合而成。
因此我们可以在目标领域上测 fertility,从而评估分词器的优势与短板。下表比较了不同分词器在多种语言与领域上的 fertility。
评估分词器
为了比较不同语言上的分词器表现,我们采用 FineWeb2 的分析设置,以 Wikipedia 文章作为评估语料。每种语言抽样 100 篇文章,既保证样本有代表性,又控制计算成本。
首先安装依赖,并定义要比较的分词器与语言:
pip install transformers datasets sentencepiece 'datatrove[multilingual]'
## we need datatrove to load word tokenizers
tokenizers = [
("Llama3", "meta-llama/Llama-3.2-1B"),
("Gemma3", "google/gemma-3-1b-pt"),
("Mistral (S)", "mistralai/Mistral-Small-24B-Instruct-2501"),
("Qwen3", "Qwen/Qwen3-4B")
]
languages = [
("English", "eng_Latn", "en"),
("Chinese", "cmn_Hani", "zh"),
("French", "fra_Latn", "fr"),
("Arabic", "arb_Arab", "ar"),
]
接着加载 Wikipedia 样本,我们使用 streaming 来避免下载完整数据集:
from datasets import load_dataset
wikis = {}
for lang_name, lang_code, short_lang_code in languages:
wiki_ds = load_dataset("wikimedia/wikipedia", f"20231101.{short_lang_code}", streaming=True, split="train")
wiki_ds = wiki_ds.shuffle(seed=42, buffer_size=10_000)
# Sample 100 articles per language
ds_iter = iter(wiki_ds)
wikis[lang_code] = "\n".join([next(ds_iter)["text"] for _ in range(100)])
数据准备好后,就可以在每种语言上评估各分词器。对每个组合,我们从 datatrove 加载相应的词级分词器,并计算两项指标:
from transformers import AutoTokenizer
from datatrove.utils.word_tokenizers import load_word_tokenizer
import pandas as pd
results = []
for tokenizer_name, tokenizer_path in tokenizers:
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path, trust_remote_code=True)
for lang_name, lang_code, short_lang_code in languages:
word_tokenizer = load_word_tokenizer(lang_code)
# Compute metrics on Wikipedia
fertility, pcw = compute_tokenizer_metrics(tokenizer, word_tokenizer, wikis[lang_code])
results.append({
"tokenizer": tokenizer_name,
"language": lang_name,
"fertility": fertility,
"pcw": pcw
})
df = pd.DataFrame(results)
print(df)
tokenizer language fertility pcw
0 Llama3 English 1.481715 0.322058
1 Llama3 Chinese 1.601615 0.425918
2 Llama3 French 1.728040 0.482036
3 Llama3 Spanish 1.721480 0.463431
4 Llama3 Portuguese 1.865398 0.491938
5 Llama3 Italian 1.811955 0.541326
6 Llama3 Arabic 2.349994 0.718284
7 Gemma3 English 1.412533 0.260423
8 Gemma3 Chinese 1.470705 0.330617
9 Gemma3 French 1.562824 0.399101
10 Gemma3 Spanish 1.586070 0.407092
11 Gemma3 Portuguese 1.905458 0.460791
12 Gemma3 Italian 1.696459 0.484186
13 Gemma3 Arabic 2.253702 0.700607
14 Mistral (S) English 1.590875 0.367867
15 Mistral (S) Chinese 1.782379 0.471219
16 Mistral (S) French 1.686307 0.465154
17 Mistral (S) Spanish 1.702656 0.456864
18 Mistral (S) Portuguese 2.013821 0.496445
19 Mistral (S) Italian 1.816314 0.534061
20 Mistral (S) Arabic 2.148934 0.659853
21 Qwen3 English 1.543511 0.328073
22 Qwen3 Chinese 1.454369 0.307489
23 Qwen3 French 1.749418 0.477866
24 Qwen3 Spanish 1.757938 0.468954
25 Qwen3 Portuguese 2.064296 0.500651
26 Qwen3 Italian 1.883456 0.549402
27 Qwen3 Arabic 2.255253 0.660318
结果显示,不同优先目标会带来不同的赢家与取舍:
Gemma3 分词器在多种语言上都达到了较低的 fertility 和拆分率,尤其是在英语、法语和西班牙语上,这与其分词器训练数据以及超大的 262k 词表有关,约为 Llama3 128k 的两倍。Qwen3 分词器在中文上表现突出,但在英语、法语和西班牙语上落后于 Llama3。Mistral Small 的分词器 (Mistral AI, 2025) 在阿拉伯语上最好,但在英语和中文上不如其他分词器。
在现有分词器与自训分词器之间做选择
目前有不少强力分词器可选。许多新模型会以 GPT4 的分词器 (OpenAI et al., 2024) 为基础,再增加多语种 token。从上表可见,Llama 3 的分词器在多语文本与代码上表现均衡,而 Qwen 2.5 在中文与部分低资源语言上更突出。
- 何时用现成分词器: 如果我们的目标用例与上面这些分词器(Llama、Qwen、Gemma)的语言或领域覆盖相匹配,那么它们是经过实战验证的稳妥选择。SmolLM3 训练中我们选了 Llama3 的分词器:它在目标语言(英语、法语、西班牙语、葡萄牙语、意大利语)上表现竞争力强,同时词表规模适中,适合小模型。对于更大的模型,嵌入在总参数中占比更小,Gemma3 的效率收益会更有吸引力。
- 何时自训分词器: 如果你面向低资源语言,或者数据混合比例差异很大,就很可能需要自训分词器以保证覆盖度。此时应尽量用接近最终训练混合的数据来训练分词器。但这会带来“鸡生蛋、蛋生鸡”的问题:我们需要分词器来做数据消融以找到混合比例。解决方法是先用近似数据训练一个分词器做消融,最终开跑前再重训分词器,并验证下游性能提升且 fertility 仍然良好。
分词器的选择看似细节,却会影响模型性能的方方面面。所以别怕在这一步投入时间,把它打磨到位。
SmolLM3
在考察完架构版图并完成系统性消融之后,我们来看这些结论如何在 SmolLM3 这样的模型上落地。
SmolLM 系列的目标,是不断拓展小模型的可能性边界。SmolLM2 交付了 135M、360M 和 1.7B 三个能力扎实的模型,全部面向端侧高效运行。到了 SmolLM3,我们希望在仍适配手机的前提下提升性能,并补齐 SmolLM2 的短板:多语言、超长上下文处理,以及更强的推理能力。综合权衡后,我们选择 3B 参数作为最佳平衡点。
因为是在放大一套已验证的配方,我们自然选择了稠密 Transformer。MoE 当时还未在 nanotron 中实现,而我们也具备训练强小型稠密模型的经验与基础设施。更关键的是,端侧部署受限于内存:即使 MoE 只有少数专家被激活,仍需把所有专家加载进内存,因此会受到限制。对我们的端侧目标来说,稠密模型更现实。
Ablations: 我们以 SmolLM2 1.7B 的架构为基础,先用 Qwen2.5-3B 的布局在 100B tokens 上训练了一个 3B 的消融模型。这样就有了一个稳固基线,便于逐项验证修改。每一项架构改动都必须满足其一:降低损失与提升英文基准的下游性能;或在不损失质量的前提下,带来可量化收益(如推理速度)。
在正式开跑最终版本前,我们测试了以下内容:
Tokenizer: 在动架构之前,首先要选分词器。我们找到了覆盖目标语言与领域的一组可用分词器。基于 fertility 分析,Llama3.2 的分词器在我们的 6 种目标语言之间给出了最佳折中,同时词表维持在 128k:足够支撑多语效率,又不会让 3B 模型的嵌入参数过度膨胀。
Grouped Query Attention (GQA) : 我们再次验证了先前结论:4 组的 GQA 能达到多头注意力的性能,这次是在 3B 规模、100B tokens 的设置下。KV cache 的效率提升非常可观,尤其在端侧内存紧张的情况下。
NoPE for long context : 我们通过每 4 层移除一次 RoPE 来实现 NoPE。3B 的消融结果印证了上文发现:NoPE 能提升长上下文处理能力,同时不牺牲短上下文性能。
Intra-document attention masking : 训练时禁止跨文档注意力,有助于在超长序列训练中提升速度与稳定性,而下游性能并未受到影响。
Model layout optimization : 我们对比了文献中近期 3B 模型的布局,有的偏深、有的偏宽。在我们的训练配置下测试了 Qwen2.5-3B(3.1B)、Llama3.2-3B(3.2B)和 Falcon3-H1-3B(3.1B)三种布局。结果很有意思:尽管 Qwen2.5-3B 参数更少,但三者在损失与下游性能上几乎一致。不过,Qwen2.5-3B 更深的架构与研究中“网络更深有利于泛化”的结论一致 (Petty et al., 2024)。因此我们选择更深的布局,押注其在训练推进时更有优势。
Stability improvements : 我们保留了 SmolLM2 的 tied embeddings,同时引入了受 OLMo2 启发的新技巧:对 embedding 取消 weight decay。消融结果表明这不会影响性能,同时降低 embedding 范数,有助于避免训练发散。
系统性消融的好处在于:我们可以确信每一项改动都被验证过,从而放心地将它们组合在一起。
实践中我们会逐步验证:一旦某个特性被确认有效,它就成为后续测试的基线。测试顺序也很关键:先从最稳妥的特性开始(tie embeddings → GQA → document masking → NoPE → remove weight decay)。
行动准则
TL;DR:用例决定选择。
让部署目标主导架构决策。 在评估新的架构创新时,先考虑模型将在哪里、以何种方式运行。
在创新与务实之间找到平衡。 关键架构进展不能忽视——当 GQA 和更优替代方案已存在时,仍使用多头注意力就是糟糕的技术选择。保持对最新研究的了解,并采纳那些在规模上有清晰、可验证收益的技术。但也要克制追逐每一篇只承诺微小增益的新论文的冲动(除非你资源充足或目标本就是架构研究)。
系统化胜过直觉。 任何架构变更都要验证,不管它在纸面上多么诱人。然后逐项测试改动,再去组合,才能弄清各自影响。
规模效应真实存在——尽可能在目标规模上重做消融实验。 不要假设小规模消融结论能在目标模型规模上完全成立。有算力就尽量复核。
在真实领域验证分词器效率。 针对目标语言与领域的 fertility 指标,比追随最新模型用什么分词器更重要。50k 的英文分词器不足以胜任严肃的多语任务,但如果语言覆盖不多,也没必要上 256k 的词表。
既然模型架构已经确定,现在是时候着手选择将驱动学习过程的优化器和超参数了。
优化器与训练超参数
各块拼图正逐一落位:我们跑完了消融实验,敲定了架构,选好了分词器。但在真正启动训练之前,仍有几块关键拼图缺失:该用哪种优化器?学习率和批次大小该设多少?训练过程中如何调度学习率?
最省事的做法是直接照搬文献里某个强模型所用的数值。毕竟大厂验证过的配置,按理说也能管用。若我们从相近架构和规模的模型中取用参数,很多时候确实没问题。
但若不做针对自身场景的调优,我们很可能错过本可获得的性能提升。文献中的超参数是为特定数据和约束优化的,有些约束甚至与性能无关——也许某个学习率是开发早期随手定下、此后从未再碰的。即便作者做了完整的超参数扫描,那些“最优值”也是针对他们那套架构、数据和训练流程的组合得出的,而非我们的。文献数值永远是好起点,但值得在邻近范围内探索是否有更优解。
本章将探讨最新的优化器(以及经典老将 AdamW (Kingma, 2014) 是否仍能经受时间检验 🎉),深入超越标准 cosine decay 的学习率调度方式,并说明在给定模型和数据规模下如何调节学习率与批次大小。
先从优化器之争说起。
优化器:AdamW 及其它
优化器是整场 LLM 训练的核心。它根据过往更新、当前权重和损失求得的梯度,决定每个参数的实际更新步长。与此同时,它也是吃显存、吃算力的巨兽,直接影响你需要的 GPU 数量和训练速度。
我们梳理了当前 LLM 预训练中常用优化器的分布情况:
| 模型 | 优化器 |
|---|---|
| Kimi K2、GLM 4.5 | Muon |
| 其它多数 | AdamW |
你可能会问:为什么大家都在用 AdamW?
本文作者认为原因是「人比较懒」(大家好,我是 Elie),但更务实的说法是:AdamW 在多个规模上长期表现稳定甚至更优,而更换这类核心组件总有风险,尤其在长训练中验证效果又难又贵的情况下。
此外,公平比较优化器比看上去更难。规模会改变训练动力学,小规模消融难以模拟,超参数调优因此变得复杂。你可能会说:「没关系,我调了几周 AdamW,直接把同一套超参数拿来比就行!」——我们也希望如此。可惜的是,每种优化器都需要单独做系统的超参数搜索(一维?二维?三维?),这让优化器研究既难又烧钱。
那就从经典、以及 Durk Kingma 那令人咋舌的学术影响力的基石说起:AdamW。
AdamW
Adam(Adaptive Momentum Estimation,自适应动量估计)是一阶优化算法。除梯度外,它还考虑前几步权重的变化量,使每个参数的学习率随动量自适应调整。
细心的读者会问:是不是漏了 W?没错。我们特意加上 W(= weight decay,权重衰减)的原因如下。在标准 SGD 中,可以直接在损失里加 ( 为权重)来做 L2 正则。但若对 Adam 也这样做,自适应学习率会影响 L2 正则项,使正则强度依赖梯度大小,削弱其效果。这并非我们所愿,因此 AdamW 将权重衰减与主优化循环解耦,单独施加。
有意思的是,过去几年 AdamW 的超参数几乎没变:
- β₁ = 0.9,β₂ = 0.95
- grad norm clipping = 1.0
- weight decay = 0.1(Llama-3-405B 降至 0.01)
从 Llama 1、2、3 到 DeepSeek-V1、2、3 671B,这套「三件套」几乎原样沿用。是 Durk Kingma 一路都对,还是我们还能更好?
Muon 一句话
Adam 是一阶方法,只用梯度;Muon 是二阶优化器,对参数张量采取 矩阵 视角。
只看公式你可能会疑惑:为何算二阶方法?我只看到梯度,没有更高阶项。二阶优化其实发生在 Newton-Schulz 步骤内部,此处不展开。已有高质量博客深入讲解 Muon,这里只概括其三个核心思想:
- 矩阵级几何 vs 逐参数更新: AdamW 按 参数 做预条件(对角二阶矩)。Muon 把每个权重 矩阵 当作整体,沿 更新,从而捕获行/列子空间结构。
- 通过正交化实现各向同性步: 用奇异值分解(SVD)将 分解后,把幅度()与方向(左右子空间 )分离。用 替代 会丢弃奇异值,使步长在活跃子空间内呈 各向同性。初看有点反直觉——丢掉 似乎损失信息——但能减少轴对齐偏置,并鼓励探索那些本会被极小奇异值压制的方向。这类探索是否会让模型具备仅看损失难以察觉的能力,仍是开放问题。
- 对大批次的经验容忍度: 实践中 Muon 往往能承受更大的 batch size。我们会在批次大小一节再详述,但这可能是采用 Muon 的关键考量之一。
多年来社区主要沿用 AdamW,前沿实验室的优化器配方也常保密(例如 Qwen 从未公开其配置),但近来 Muon 已在一些重磅发布中落地(如 Kimi K2、GLM-4.5)。希望未来能看到更多公开、稳健的用法。
优化器种类繁多,研究员在组合各种动量和导数之余,最擅长的可能就是起名:Shampoo、SOAP、PSGD、CASPR、DION、Sophia、Lion……连 AdamW 也有 NAdamW、StableAdamW 等变体。逐一深挖这些优化器足够单独写一篇博客,我们留待日后。目前推荐 Stanford/Marin 团队的这篇论文 (Wen et al., 2025),它对多种优化器做了基准测试,展示了超参数调优在比较中的重要性。
几乎每个优化器都伴生同一个问题:该以多大力度更新权重?这由学习率决定,在优化器公式里通常表现为一个标量。下面来看看这个看似简单的话题为何仍有诸多面向。
学习率
学习率是我们需要设定的最重要超参数之一。在每个训练步中,它控制我们根据计算出的梯度对模型权重调整的幅度。学习率过低,训练会极其缓慢,还可能陷入糟糕的局部最优;损失曲线会显得平坦,算力白白消耗却难有实质进展。反之,学习率过高会让优化器步长过大、越过最优解而难以收敛,甚至出现最不愿看到的情况:损失发散、一飞冲天。
最优学习率也并非恒定——训练动力学会随训练推进而变化。远离良好解时,高学习率有利;接近收敛时则带来不稳定。学习率调度因此登场:先做 warmup 避免早期混乱,再衰减以沉入良好最小值。这类模式(如 warmup + cosine decay)在神经网络训练中已被验证多年。
如 Table 1 所示,多数现代 LLM 采用固定 warmup 步数(例如 2000),与模型规模和训练长度无关。我们发现:长训练时增加 warmup 步数对性能影响不大;极短训练时,通常取训练步数的 1% 至 5%。
先看常用调度方式,再讨论如何选择峰值学习率。
学习率调度:超越 Cosine Decay
多年前就已知调节学习率有助于收敛 (Smith & Topin, 2018),cosine decay (Loshchilov & Hutter, 2017) 是训练 LLM 的首选调度:warmup 后从峰值学习率开始,沿余弦曲线平滑下降。简单且好用。但主要缺点是缺乏灵活性:必须事先确定总训练步数,因为 cosine 周期必须与总训练时长匹配。这在常见场景下会出问题:模型尚未收敛、获得更多算力想延长训练、或做 scaling law 实验需在不同 token 量下训练同一模型——cosine decay 都会逼你从头重跑。
现在许多团队改用无需在 warmup 后立即衰减的调度。Warmup-Stable-Decay(WSD) (Hu et al., 2024) 和 Multi-Step (DeepSeek-AI, :, et al., 2024) 变体就是如此,下图中有示意。训练大部分时间内保持恒定高学习率,WSD 在最后阶段(通常为最后 10–20% 的 tokens)急剧衰减;Multi-Step 则做离散下降(分步),例如 DeepSeek LLM 的做法:80% 训练后降一次,90% 后再降一次。
相比 cosine decay,这些调度更具实用性。我们可以在训练中途延长而不必重启——无论是计划延长训练、提前衰减以更好衡量进度,还是用一次主实验跑出不同 token 量下的 scaling law。此外,研究显示 WSD 和 Multi-Step 在性能上可与 cosine decay 相当 (DeepSeek-AI, :, et al., 2024; Hägele et al., 2024),且在真实训练场景中更实用。
但你可能已注意到,这些调度相比 cosine 引入了新超参数:WSD 的衰减阶段该多长?Multi-Step 各步该多长?
- WSD: 要达到与 cosine 相当的性能,所需冷却时长会随训练变长而缩短;建议将总 token 的 10–20% 用于衰减阶段 (Hägele et al., 2024)。下文的消融实验会验证这一设定与 cosine 相当。
- Multi-Step: DeepSeek LLM 的消融显示,其基线 80/10/10 划分(稳定至 80%,第一步 80–90%,第二步 90–100%)与 cosine 相当,而调整比例还能更优,例如 70/15/15 和 60/20/20 的划分。
我们还可以在这些调度上发挥更多创意。看看 DeepSeek 各代模型采用的调度:
DeepSeek LLM 采用基线 Multi-Step 调度(80/10/10)。DeepSeek V2 将比例调整为 60/30/10,给第一步衰减留出更多时间。DeepSeek V3 最为创新:不再维持恒定学习率后接两次陡降,而是用 cosine decay(从训练的 67% 到 97%)从恒定阶段过渡,再在最终陡降前插入短暂恒定阶段。
DeepSeek-V2 与 V3 的技术报告未包含这些调度变更的消融实验。建议从简单的 WSD 或 Multi-Step 开始,再考虑通过消融调参。
学习率调度的巡礼先告一段落,接下来烧些 GPU 时数,看看实践中什么管用。
消融:WSD 与 Cosine 相当
到了做消融的时候。我们来验证 WSD 在实践中是否真能与 cosine 性能相当。此处不展示 Multi-Step 的消融,但推荐参考 DeepSeek LLM 的消融,他们展示了 Multi-Step 在不同阶段划分下均可匹配 cosine。本节将对比 cosine decay 与两种衰减窗口的 WSD:10% 和 20%。
评估结果显示三种配置的最终性能相近。观察损失与评估曲线(尤其是 HellaSwag),可见一个有意思的模式:在稳定阶段(WSD 衰减开始前),cosine 的损失和评估分数更优。然而一旦 WSD 进入衰减阶段,损失与下游指标几乎线性改善,使 WSD 在训练结束时追上 cosine。
这说明 WSD 的 10–20% 衰减窗口足以在最终性能上与 cosine 相当,同时保留训练中途延长的灵活性。SmolLM3 选用 10% 衰减的 WSD。
若在稳定阶段比较 cosine 与 WSD 的中间 checkpoint,需对 WSD 的 checkpoint 施加衰减,才能公平比较。
熟悉了主流学习率调度后,下一个问题是:峰值学习率究竟该设多少?
寻找最优学习率
如何为具体的学习率调度和训练设定选出合适的学习率?
可以对短消融做学习率扫描,就像架构选择时那样。但最优学习率取决于训练时长:短消融中收敛最快的学习率,未必是完整训练的最佳选择;多次跑耗时的数周训练来试不同学习率,成本也难以承受。
先看一些可快速运行的简单扫描,排除明显过高或过低的学习率,再讨论超参数的 scaling laws。
消融:学习率扫描
为说明不同学习率的影响,我们在 45B tokens 上训练的 1B 消融模型上做了一次扫描。同一模型、同一设定下,用 4 种学习率:1e-4、5e-4、5e-3、5e-2。结果清楚展示了两端的风险:
LR 5e-2 几乎立刻发散,损失早早飙升且无法恢复,模型不可用。LR 1e-4 过于保守,虽然训练稳定,但收敛远慢于其它学习率。5e-4 与 5e-3 的中段表现更好,收敛与性能都更理想。但针对每种模型规模做扫描会很快变得昂贵,更重要的是,它无法考虑计划训练的 token 数量——这正是 scaling laws 的价值所在。
在 SmolLM3 中,我们用 AdamW 和 WSD 调度在 100B tokens 上训练 3B 模型,比较了多种学习率。2e-4 在损失和下游表现上都比 1e-4 收敛快得多,3e-4 相较 2e-4 只有小幅提升,但长训练中不稳定性风险更高,因此我们以 2e-4 作为甜点。
这些扫描能帮我们排除明显过高(发散)或过低(收敛慢)的学习率,但为每种模型规模跑扫描成本不菲,且如前所述无法体现计划 token 量的影响。下一节将深入超参数的 scaling laws。在此之前,先讨论与学习率紧密相关的另一关键超参数:batch size。
批次大小
批次大小指在更新模型权重之前所处理的样本数量,会同时影响训练效率和最终模型表现。若硬件与训练栈在多设备上扩展良好,增大批次大小可提升吞吐量;但超过某个拐点后,更大的批次会损害数据效率——要达到相同损失,模型需要更多的总 token 数。这一拐点即所谓 临界批次大小(critical batch size) (McCandlish et al., 2018)。
- 在临界值以下增大批次: 增大批次并重新调节学习率后,能与更小批次实验相同的 token 数就能达到相同损失,数据没有被浪费。
- 在临界值以上增大批次: 更大批次会牺牲数据效率;要达到相同损失需要更多总 token(因而更高成本),即便墙上时钟时间因更多芯片在工作而缩短。
下面直观说明为何需要重新调节学习率,以及如何估计临界批次大小。
批次变大时,每个 mini-batch 梯度对真实梯度的估计更准,因此可以安全地迈出更大步长(即提高学习率),用更少的更新步数达到目标损失。问题在于如何按比例缩放。
对 B 个样本取平均:
- 批次梯度:
- 均值不变:
- 协方差缩小:
SGD 的参数更新为:
该更新的方差正比于:
因此,若要大致保持更新方差不变,将批次大小乘以 k 时,应将学习率乘以 。也就是说,若你已算得最优批次大小与学习率,并发现可以增大到临界批次大小以提升吞吐量,则也需要相应调整最优学习率。
对 AdamW、Muon 等优化器,一个常用经验是随批次增大采用 平方根 LR 缩放,但这也因优化器而异。例如 AdamW 与 beta1 / beta2 的交互可能带来截然不同的行为。更务实的做法是短时分支训练:保留一条在原始批次上的运行,另开一条用更大批次和按比例缩放后的学习率,仅当两条损失曲线在缩放后对齐时才采用更大批次 (Merrill et al., 2025)。该文中在切换批次大小时会重新 warm up 学习率并重置优化器状态,还设定了容差和时间窗口来判断两条损失是否「匹配」,这两个旋钮均为经验选取。他们发现 估计(本身也有噪声)会低估「实际」临界批次大小。这种做法能快速、低风险地验证新的批次/学习率组合是否保持训练动态。
临界批次大小并非固定,会随训练推进而增大。训练早期模型梯度步长较大, 较大,故 较小,临界批次大小也较小;后期模型更新趋于稳定,更大批次更有效。因此部分大规模训练不固定批次大小,而采用所谓 批次大小 warmup。例如 DeepSeek-V3 在前约 469B tokens 使用 12.6M 的批次,之后将批次提高到 62.9M 直至训练结束。这类批次大小 warmup 与学习率 warmup 目的一致:在梯度噪声尺度增大的过程中让模型始终处在高效前沿,保持稳定且高效的优化。
另一种思路是把损失当作临界批次大小的代理。Minimax01 采用了这种做法,在最后阶段用 128M 的批次大小训练。其不同之处在于他们并未提高学习率,因此其批次大小调度实际上起到了学习率衰减的作用。
实践中可以这样选择批次大小与学习率:
- 先根据 scaling laws(见后文)或文献确定你认为最优的批次大小与学习率。
- 再调节批次大小,看能否提升训练吞吐量。
要点是:从起始批次大小到临界批次大小之间,往往存在一个区间,可以在不牺牲数据效率的前提下增大批次、提高硬件利用率,但必须相应重新调节学习率。 若吞吐量提升不明显,或更大批次(配合按比例缩放的学习率)在实验中表现出更差的数据效率,则保持初始取值即可。
如上所述,确定批次大小与学习率起点的一种方式是通过 scaling laws。下面看这些 scaling laws 如何工作,以及如何根据计算预算预测这两个超参数。
超参数的 scaling laws
最优学习率与批次大小不仅取决于模型架构与规模,还取决于计算预算——即模型参数量与训练 token 数的组合。实践中,二者共同决定更新应更激进还是更保守,scaling laws 正是在此发挥作用。
Scaling laws 建立了描述「随训练规模增大(更大模型或更多数据)模型表现如何变化」的经验关系(本章末尾「Scaling laws」一节有完整脉络)。它们还能帮助我们预测在放大训练时如何调整学习率、批次大小等关键超参数,DeepSeek 与 Qwen2.5 等近期工作即如此使用,从而得到有依据的默认值,而不必完全依赖超参数扫描。
要在这一语境下应用 scaling laws,需要先量化训练规模。常用指标是计算预算,记作 C,以 FLOPs 衡量,可近似为:
其中 N 为模型参数量(如 1B = 1e9),D 为训练 token 数。FLOPs(浮点运算次数)是与硬件无关的「实际计算量」度量。若觉得 FLOPs 太抽象,可以这样理解:在 100B tokens 上训练 1B 参数模型,其 FLOPs 约为在 100B tokens 上训练 2B 模型、或在 200B tokens 上训练 1B 模型的一半。
常数 6 来自对训练 Transformer 所需浮点运算次数的经验估计,约每参数每 token 6 FLOPs。
这与学习率有何关系?我们可以推导出将最优学习率与批次大小表示为总计算预算 C 的函数的 scaling laws,从而回答诸如:
- 从 1B 扩到 7B 参数时,学习率应如何变化?
- 训练数据翻倍时,是否需要调整学习率?
下面以 DeepSeek 的做法为例说明。首先选定学习率调度(理想情况下用 WSD 以兼顾灵活性),然后在若干计算预算下(如 1e17、5e17、1e18、5e18、1e19、2e19 FLOPs)用不同的批次大小与学习率组合训练模型;换言之,用不同模型规模、不同 token 数、不同超参数做多组实验。WSD 的优势在此体现:同一次训练可延伸到不同 token 量而无需重启。
对每种设置做学习率与批次大小的扫描,找出达到近最优表现的配置——通常定义为验证损失(在与训练集分布相近的独立验证集上计算)与最佳值相差在较小范围内(如 0.25%)。每个近最优配置对应一个数据点,即 (计算预算 C, 最优学习率 η) 或 (C, 最优批次大小 B)。在双对数坐标下,这些关系往往呈幂律,近似为直线(见上图)。对这些点做拟合即可得到描述最优超参数随计算量演化的 scaling laws。
由此得到的一个重要结论是:在固定模型规模与计算预算下,表现在一大段超参数范围内都较稳定,即存在较宽的「甜区」而非狭窄最优点。我们不必找到完美取值,只要足够接近即可,这使整个流程更易落地。
下图是 DeepSeek 推导出的 scaling laws 结果,每个点对应一个近最优配置:
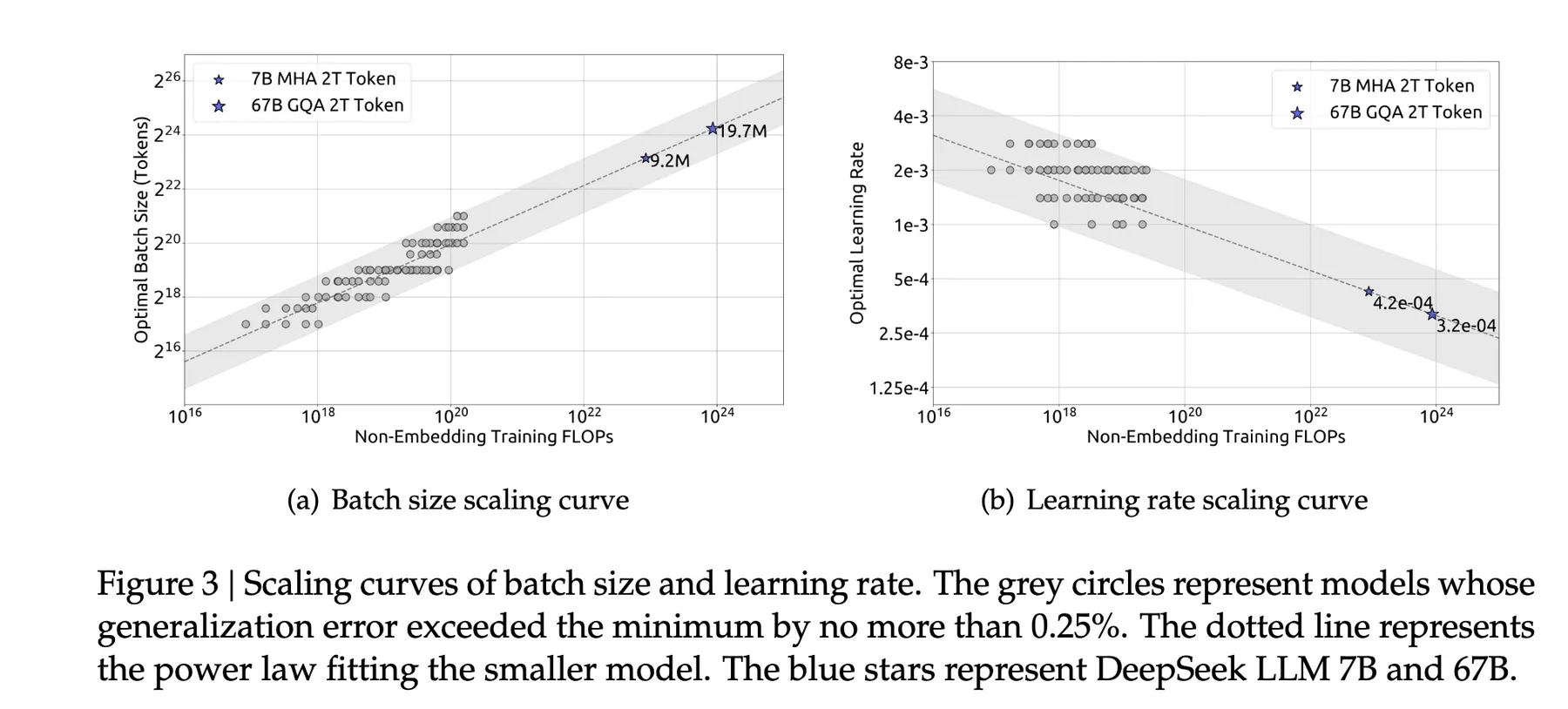
背后的直观是:训练规模越大、时间越长,我们越需要 更稳定的更新(因而学习率更小)和 更高效的梯度估计(因而批次更大)。
这些 scaling laws 为学习率与批次大小提供了起点,但目标不是「每次梯度的最优样本数」,而是在时间和 GPU 数量约束下达到 更低的损失,同时仍从每个 token 中提取完整信号。
实践中,你往往可以在预测的最优批次大小之上继续增大批次,直至前文讨论的临界批次大小,从而显著提升吞吐量而不明显损害数据效率。
SmolLM3
那 SmolLM3 最终用了什么配置?在 SmolLM3 发布前的消融阶段,我们在一个用 100B tokens 训练的 1B 模型上对比了 AdamW、AdEMAMix 和 Muon。Muon 在调参到位时能超过 AdamW,但对学习率很敏感、也更容易发散。AdeMaMix 没那么敏感,最终 loss 与 Muon 相近。AdamW 最稳定,但最终 loss 高于调好参数的方案。
不过当我们把规模扩到 3B 时,Muon 和 AdeMaMix 出现发散的次数更多。这可能与我们在完成消融后才发现的并行化 bug 有关(见「训练马拉松」一章),但目前还没证实。最终我们选择了 AdamW(beta1: 0.9, beta2: 0.95),权重衰减 0.1、梯度裁剪 1。整体就是一个很标准的配置。
学习率调度方面我们选了 WSD。SmolLM2 里我们已经用它跑得很顺,而且它易用、对总训练时长更灵活,还方便在训练中途做衰减实验,是我们最满意的决定之一。我们做了学习率 sweep,最终定在 2e-4。全局批次大小方面,我们测试了 2M 到 4M tokens,发现对 loss 或下游表现影响很小,所以选择了 2.36M tokens——吞吐量最好的那个。
行动准则
TL;DR: 在探索与执行之间取得平衡,完成胜于完美。
我们已经讨论了很多「做什么」(优化器、学习率、批次大小),但同样重要的是 怎么做。我们如何决定哪些值得实验?如何安排时间?何时停止探索、开始训练?
在探索与执行之间明智分配时间。 花上数周去打磨一种新方法带来的小幅提升,不如把同样的算力投入更好的数据策划,或更充分的架构消融。根据我们的经验,尽管这可能会让架构爱好者失望,最大的性能增益通常来自数据策划。
拿不准时,优先选择灵活性与稳定性而非峰值性能。 如果两种方法表现相当,就选更灵活或实现更成熟、更稳定的那个。像 WSD 这样允许延长训练或在训练中途做实验的学习率调度,比可能略好收敛却更僵硬的调度更有价值。
知道何时停止优化、开始训练。 总会还有一个超参数要调,或者还有一个优化器想试。为探索设定截止日期并坚持执行——真正完成训练的模型,总会胜过我们从未启动的完美模型。
完美是最大的敌人,尤其是在算力预算和截止日期有限的情况下。
Scaling laws:该用多少参数、多少数据?
在深度学习早期,语言模型(以及训练它们的集群)还没“做大”时,训练通常不太受算力限制。训练一个模型时,你只要选硬件能装下的最大模型和批次大小,然后一直训练到模型开始过拟合或数据用完为止。但即便那时,人们也感觉规模是有帮助的——比如 Hestness et al. 在 2017 年给出了一套全面结果,表明更大的模型、训练更久会带来可预测的收益。
进入大语言模型时代,我们 总是 受算力限制。为什么?Kaplan 等人的《Scaling Laws for Neural Language Models》把早期的“可扩展性直觉”系统化了,证明语言模型的性能在跨越多个数量级的规模上都很可预测。这引发了模型规模和训练时长的爆发式增长,因为我们可以 准确预测 扩大规模能提升多少性能。于是,做更好模型的竞赛变成了用越来越大的算力训练更大的模型、更多的数据,语言模型的发展也很快变成“算力受限”的问题。
在算力受限时,最关键的问题是:是训练更大的模型,还是用更多数据训练更久?令人意外的是,Kaplan 等人的缩放定律认为,把更多算力投到模型规模上更划算。这推动了例如 GPT‑3 这种庞大模型(175B 参数)用相对“节省”的 token 预算(300B tokens)进行训练。后来,Hoffman et al. 重新审视发现 Kaplan 方法存在问题,最终重新推导了缩放定律,结果建议把更多算力用在训练时长上——也就是说,175B 的 GPT‑3 在“算力最优”条件下应当消耗 3.7T tokens!
这让整个领域从“把模型做大”转向“训练更久、训练更好”。然而,大多数现代训练仍没有严格遵循 Chinchilla 定律,因为它们有一个缺陷:它们试图预测在给定算力预算下达到最好性能所需的模型规模和 训练 时长,却没有考虑更大的模型在训练结束 之后 推理成本更高。换句话说,我们可能更愿意在同样的算力预算下,用更小的模型训练更久——即便这不是“算力最优”——因为这样会让推理更便宜(Sardana et al., de Vries)。如果我们预期模型会有大量推理使用(比如开源发布 🤗),这种选择就更合理。最近,把训练时长超过缩放定律建议值的“过度训练”已成为常态,我们在开发 SmolLM3 时也采用了这一做法。
缩放定律给出了在特定算力预算下建议的模型规模和训练时长,但一旦选择过度训练,就得自己决定这些因素。对 SmolLM3 来说,我们先选了 30 亿(3B)参数作为目标规模。参考同量级的近期模型,比如 Qwen3 4B、Gemma 3 4B 和 Llama 3.2 3B,我们认为 3B 足够大,能具备有意义的能力(如推理与工具调用),同时又足够小,推理很快、适合本地高效使用。训练时长方面,我们注意到最近的模型被训练得 极其 久——例如前面提到的 Qwen3 系列据称训练了 36T tokens!因此,训练时长往往由可用算力决定。我们拿到 384 张 H100、约一个月的资源,这给了我们约 11 万亿(11T)tokens 的训练预算(假设 MFU 约为 ~30%)。
尽管有这些偏离,缩放定律在实践中仍然很有价值。 它们为实验设计提供基线, 人们常用 Chinchilla 最优设置来做消融、找信号, 也能帮助预测某个模型规模是否能达到目标性能。 正如 de Vries 在这篇 博客 中提到的, 把模型规模往下缩,可以找到一个临界模型规模:达到某个损失所需的最小容量, 再小就会出现明显的边际收益递减。
现在我们的模型架构、训练设置、模型规模和训练时长都已确定,接下来要准备两个关键部分:教模型的“数据配方”,以及能稳定训练它的基础设施。SmolLM3 的架构定在 3B 参数,我们需要策划一个数据混合,既能保证多语言、数学和代码能力,又要搭建能承受 11 万亿(11T)tokens 训练的稳定基础设施。把这些基础打牢很关键,否则再好的架构也救不了糟糕的数据策划或不稳定的训练系统。
数据策划的艺术
想象一下:你花了几周完善架构、调超参数、搭建最稳健的训练基础设施。模型收敛得很好,然后……它写不出连贯的代码、基础数学也吃力,甚至会在一句话中途切换语言。问题出在哪? 答案通常在数据上。当我们痴迷于花哨的架构创新和超参数扫描时,数据策划往往决定了模型究竟会变得真正有用,还是只是另一个昂贵的实验。这就是随机网页爬取训练与精心策划的高质量数据集之间的差别——后者能真正教会模型我们希望它学到的技能。
如果模型架构定义了模型 如何 学习,那么数据就定义了它 学什么,再多的算力或优化器调参也无法弥补训练内容选错。此外,把训练数据选对并不只是拥有好数据集。关键在于组装正确的 数据混合:在相互冲突的目标之间取得平衡(如强英语能力 vs. 强多语言能力),并调整数据比例以对齐我们的性能目标。这个过程与其说是在寻找一个放之四海而皆准的最佳配比,不如说是在提出正确的问题并制定具体计划来回答它们:
- 我们希望模型擅长什么?
- 每个领域哪些数据集最好,我们该如何混合?
- 针对目标训练规模,我们是否有足够高质量的数据?
本节将用原则性的方法、消融实验,以及一点点“炼金术”来应对这些问题,把一堆优秀的数据集变成优秀的训练混合。
什么是好的数据混合,为什么它至关重要
我们对语言模型的期待很高:它们应该能帮我们写代码、给建议、回答几乎所有问题、使用工具完成任务,等等。像网页这样的海量预训练数据源并不能覆盖完成这些任务所需的全部知识与能力。因此,近来的模型还会依赖更专业的预训练数据集,针对数学、编程等特定领域。我们过去在数据集策划上做了大量工作,但在 SmolLM3 上我们主要使用了现有数据集。想了解更多数据集策划的细节,请参阅我们关于构建 FineWeb 和 FineWeb-Edu、FineWeb2、Stack-Edu 与 FineMath 的报告。
数据混合的反直觉本质
如果你刚开始训练语言模型,找到一个好的数据混合看起来可能很直接:先明确目标能力,再为每个领域收集高质量数据集,然后将它们组合起来。现实要复杂得多,因为不同领域可能会争夺同一份训练预算。当你聚焦某项特定能力(比如代码)时,很容易想提高任务相关数据(如源代码)的权重。然而,提高某一来源的权重,实际上就意味着降低其他所有来源的权重,这可能会损害语言模型在其他场景下的能力。因此,在多来源数据上训练,本质上是在不同下游能力之间寻求平衡。
此外,在这些来源和领域中,通常会有一部分“高质量”数据,对提升语言模型能力特别有帮助。那为什么不直接丢掉所有低质量数据,只用最高质量数据训练?对于 SmolLM3 的 11T tokens 大规模训练预算而言,进行这种极端过滤会导致数据被反复使用。已有研究表明,这类重复可能有害 (Muennighoff et al., 2025),因此理想情况下,我们应当同时利用高质量和较低质量数据,并尽可能最大化模型性能。
为了在不同来源间平衡数据并利用高质量数据,我们需要精心设计 mixture:即各来源训练文档的相对占比。由于语言模型在某项任务或领域上的表现,很大程度取决于它见过多少与该任务相关的数据,调节 mixing weights 就提供了一种直接的方式来平衡模型在各领域的能力。由于这些权衡高度依赖具体模型且难以预测,消融实验至关重要。
但数据混合不必在整个训练过程中保持不变。随着训练推进动态调整混合比例,也就是我们所说的多阶段训练(multi-stage training)或 curriculum,可以更好地同时利用高质量和较低质量数据。
训练课程的演进
在大语言模型训练的早期,标准做法是在整个训练过程中固定单一的数据混合。GPT-3 和早期版本的 Llama 等模型,都是从开始到结束使用静态混合。近些年,行业逐渐转向 多阶段训练 (Allal et al., 2025),即在训练过程中动态调整数据混合。主要动机在于:语言模型的最终行为会受到训练后期所见数据的强烈影响 (Y. Chen et al., 2025b)。这一洞察带来了一个实用策略:在训练前期提高更充足数据源的权重,在训练后期再混入规模更小、质量更高的数据源。
一个常见问题是:应当在什么时候调整混合比例?虽然没有放之四海而皆准的规则,但我们通常遵循以下原则:
- 性能驱动的干预 : 监控关键基准上的评估指标,并调整数据集混合来解决特定能力瓶颈。例如,如果数学能力进入平台期而其他能力仍在提升,这就是引入更高质量数学数据的信号。
- 将高质量数据留给后期阶段 : 规模较小但高质量的数学和代码数据集,在退火阶段(学习率衰减的最终阶段)引入时影响最大。
现在我们已经明确了为什么混合比例重要、训练课程如何运作,接下来讨论如何同时调优这两者。
消融实验设置:如何系统化测试数据配方
在测试数据混合时,我们的方法与架构消融实验类似,但有一个关键区别:我们尽量在目标模型规模上进行实验。小模型和大模型的容量不同,例如非常小的模型可能难以同时处理多种语言,而更大的模型可以在不牺牲其他能力的情况下吸收这些数据。因此,如果在过小规模上做数据消融,很可能会对最优混合比例得出错误结论。
在 SmolLM3 中,我们直接在 3B 模型上开展主要数据消融,使用 50B 和 100B tokens 的短程训练。我们还使用了另一类消融设置:退火实验(annealing experiments)。我们不是从头用不同混合比例重新训练,而是从主训练过程中的中间检查点(例如 7T tokens)继续训练,并修改数据组成。这个方法可以用于测试多阶段训练中的数据混合调整(即在训练中途改变数据配方),最近的 SmolLM2、Llama3 和 Olmo2 等工作也采用了类似做法。评估方面,我们在标准英文评测之外加入了多语言任务,以便更准确地衡量不同语言配比之间的权衡。
近期也有一些工作提出了自动化方法来寻找最优数据配比,包括:
- DoReMi (Xie et al., 2023):使用小型代理模型学习各领域权重,以最小化验证损失。
- Rho Loss (Mindermann et al., 2022):基于留出集损失选择单条训练样本,优先保留“可学习、与任务相关、且模型尚未学会”的样本。
- RegMix (Q. Liu et al., 2025):通过正则化回归确定最优数据混合比例,在多个评估目标和数据领域之间平衡性能。
我们在过去的项目中尝试过 DoReMi 和 Rho Loss,但发现它们往往会收敛到与数据集自然规模分布大致相似的配比,本质上就是“哪类数据更多,就继续用更多”。这在理论上很有吸引力,但在我们的场景里并没有超过精细的手工消融。近期的 SOTA 模型仍主要依赖通过系统化消融和退火实验进行手工配比调优,这也是我们在 SmolLM3 中采用的方法。
SmolLM3:数据混合策划(web、多语言、数学、代码)
对于 SmolLM3,我们希望模型既能处理英语和多种其他语言,又能在数学与代码方面表现出色。web 文本、多语言内容、代码和数学这些领域在大多数 LLM 中都很常见,但我们这里介绍的流程同样适用于低资源语言,或金融、医疗等特定领域的训练。方法是一致的:选出优质候选数据集,运行消融实验,并设计一个能平衡所有目标领域的数据混合。
这里我们不展开讲如何构建高质量数据集,因为此前工作(FineWeb、FineWeb2、FineMath 和 Stack-Edu)已经详细介绍过。相反,本节聚焦于如何将这些数据集 组合 成有效的预训练混合。
在成熟基础上构建
说到预训练数据,一个好消息是我们很少需要从零开始。开源社区已经为大多数常见领域构建了很强的数据集。有时我们确实需要创建新数据集,比如 Fine 系列(FineWeb、FineMath 等);但更多时候,挑战在于如何选择并组合现有来源,而不是重复造轮子。
SmolLM3 就是这种情况。SmolLM2 已经在 1.7B 参数规模上为英语 web 数据建立了强配方,并识别出了我们可用的最佳数学与代码数据集。我们的目标是把这套成功经验扩展到 3B,同时加入一些能力:更稳健的多语言能力、更强的数学推理能力和更好的代码生成能力。
英语 Web 数据:基础层
web 文本是通用 LLM 的骨干,但质量和数量同样重要。
在 SmolLM3 中,我们知道 FineWeb-Edu 和 DCLM 是训练当时最强的开源英语 web 数据集。两者合计提供了 5.1T tokens 的高质量英语 web 数据。问题是:最优混合比例是多少?FineWeb-Edu 更有利于教育与 STEM 基准,DCLM 则能提升常识推理。
我们沿用了 SmolLM2 的方法,在 3B 模型上做了 100B tokens 的比例扫描,测试了 20/80、40/60、50/50、60/40、80/20(FineWeb-Edu/DCLM)。结果显示,将两者混合(约 60/40 或 50/50)能取得最佳权衡。我们还在 100B tokens 的 3B 模型上复现了 SmolLM2 论文 的同类消融,结论一致。
60/40 或 50/50 在各项基准上都提供了最佳平衡,与 SmolLM2 的发现一致。我们在 Stage 1 采用了 50/50。
我们还加入了 Pes2o、Wikipedia & Wikibooks 和 StackExchange 等其他数据集。它们对性能没有明显提升,但我们仍然纳入以增强数据多样性。
多语言 Web 数据
在多语言能力上,我们重点覆盖了 5 种其他语言:法语、西班牙语、德语、意大利语和葡萄牙语。我们从 FineWeb2-HQ 中选择了这些语言,合计 628B tokens。我们还以较小比例加入了 10 种其他语言(如中文、阿拉伯语和俄语),目的不是追求这些语言的 SOTA,而是让用户更容易在这些语言上对 SmolLM3 做持续预训练。对于 FineWeb2-HQ 不支持的语言,我们使用了 FineWeb2。
关键问题是:我们的 web 数据中,非英语应占多少?我们知道,模型在某种语言或领域见到的数据越多,它在该语言或领域通常越强。但由于算力预算固定,增加某种语言的数据就意味着要减少其他语言(包括英语)的数据。
通过 3B 模型消融,我们发现 web 混合中多语言内容占 12% 时达到了理想平衡:多语言性能提升,同时英语基准不退化。这也符合 SmolLM3 的预期使用场景,即英语仍是主语言。另外需要注意的是,非英语数据只有 628B tokens,而英语有 5.1T tokens;如果比例再高很多,就需要更多重复使用多语言数据。
代码数据
我们 Stage 1 的代码来源提取自 The Stack v2 and StarCoder2 训练语料:
- The Stack v2(16 种语言)作为基础,并按 StarCoder2Data 方式过滤。
- StarCoder2 的 GitHub pull requests,用于真实世界代码审查推理。
- Jupyter 与 Kaggle notebooks,用于可执行、分步骤的工作流。
- GitHub issues 和 StackExchange 讨论串,用于围绕代码的上下文讨论。
(Aryabumi et al., 2024) 指出,代码数据对语言模型的提升不止体现在编码任务上,也会提升自然语言推理和世界知识等能力,并建议在训练混合中使用 25% 的代码数据。受此启发,我们最初从 25% 代码占比开始消融。但我们观察到英语基准(HellaSwag、ARC-C、MMLU)显著下降。将代码比例降到 10% 后,相比 0% 代码,我们在英语基准套件上仍未看到提升;不过由于代码能力对模型非常重要,我们仍保留了这部分数据。
我们将 Stack-Edu(StarCoder2Data 的教育过滤子集)延后到后续阶段引入,以遵循“高质量数据后置、最大化后期训练收益”的原则。
数学数据
数学数据沿用了与代码相似的思路。早期我们使用规模更大、更通用的 FineMath3+ 和 InfiWebMath3+;后期我们上采样了 FineMath4+ 与 InfiWebMath4+,并引入了新的高质量数据集:
- MegaMath (Zhou et al., 2025)
- 指令与推理数据集,如 OpenMathInstruct (Toshniwal et al., 2024) 和 OpenMathReasoning (Moshkov et al., 2025)
在 Stage 1,我们给数学分配 3%,并在 FineMath3+ 与 InfiWebMath3+ 之间均分。可用数学数据只有 54B tokens,而 Stage 1 预计训练 8T 到 9T tokens;如果数学占比超过 3%,数据集训练轮次就会超过 5 个 epoch。
为新阶段寻找合适的数据混合
我们通过从零开始的消融确定了 stage 1 的混合配方;而在测试新阶段的新数据集时(我们这里是两个新阶段),使用的是退火消融:在约 7T tokens(stage 1 后期)处取一个 checkpoint,然后进行 50B tokens 的退火实验,配置如下:
- 40% baseline mixture :我们一直在训练的 stage 1 原始配方
- 60% new dataset :待评估的候选数据集
例如,为了测试 MegaMath 是否能提升数学性能,我们使用 40% 的 Stage 1 配方(保持 75/12/10/3 的领域占比)和 60% 的 MegaMath 来训练。
三阶段的具体组成见下一节。
当数据被精心策划、配方也通过消融验证后,我们就可以进入真正的训练旅程。下一章讲述的就是 SmolLM3 这次为期一个月训练的故事:准备过程、意外挑战,以及一路上得到的经验教训。
训练马拉松
你已经走到这里了,恭喜!真正有意思的部分现在才开始。
到了这一步,我们已经把关键要素都准备好了:经过验证的架构、最终确定的数据混合,以及调优后的超参数。剩下的唯一工作,就是把基础设施准备就绪并按下“train”。
对于 SmolLM3,我们使用 384 张 H100 GPU(48 个节点)训练了将近一个月,处理了 11 万亿 tokens。本节会带你了解一次长周期训练在现实中会发生什么:起飞前检查、不可避免的意外,以及我们如何保持系统稳定。你会直观看到,扎实的消融实践和可靠的基础设施为何同样关键。关于 GPU 硬件、存储系统和吞吐优化等基础设施细节,我们会在最后一章展开。
我们的团队已经经历过很多次这样的训练:从 StarCoder 和 StarCoder2,到 SmolLM、SmolLM2,再到现在的 SmolLM3。每一次训练都不一样。即使你已经训练过十几个模型,每一次新运行仍会以新的方式给你“惊喜”。本节的目标是尽量把胜算堆到你这边,让你为这些意外做好准备。
起飞前检查清单:按下“train”前要核对什么
在按下“train”之前,我们会逐项检查,确保整条链路端到端可用:
基础设施就绪性:
- 如果你的集群支持 Slurm reservation,尽量使用。对 SmolLM3 来说,我们为整个训练周期预留了固定的 48 个节点。这意味着没有排队延迟、吞吐更稳定,也能持续追踪节点健康状态。
- 在启动前对 GPU 做压力测试(我们使用 GPU Fryer 和 DCGM Diagnostics),以发现降频或性能退化问题。SmolLM3 在启动前就发现了两张正在降频的 GPU,并进行了替换。
- 避免存储膨胀:我们的系统会把每个 checkpoint 上传到 S3,并在保存下一个 checkpoint 后立即删除本地副本,因此本地高速 GPU SSD 上始终最多只保留一个 checkpoint。
评估流程: 评估往往比看起来更耗时。即使所有功能都已经实现,每次手动运行评估、记录结果并画图,仍可能耗掉数小时。因此尽量把它们完全自动化,并在开跑前确认评估任务能正确运行和记录。对于 SmolLM3,每次保存 checkpoint 都会自动触发一个集群评估任务,并将结果记录到 Wandb 和 Trackio。
Checkpoint 与自动恢复系统: 验证 checkpoint 能被正确保存,且训练作业在失败后无需人工干预即可从最新 checkpoint 自动恢复。在 Slurm 上,我们使用 --requeue 选项,让失败作业自动重新提交并从最近 checkpoint 继续。
指标日志: 确认你记录了所有关心的指标:评估分数、吞吐(tokens/sec)、训练损失、梯度范数、节点健康状态(GPU 利用率、温度、显存使用)以及本次训练特有的自定义调试指标。
训练配置健全性检查: 反复核对训练配置、启动脚本和 Slurm 提交命令。
关于 GPU 测试、存储基准、监控配置以及如何构建高韧性训练系统的详细指南,请参见基础设施章节。
规模化的意外
在为 SmolLM3 完成了大量消融实验后,我们已经准备好启动全规模训练。我们在 100B tokens 上做的 3B 消融结果很有希望。相较 SmolLM2 的架构改动(详见架构选择:GQA、NoPE、文档掩码、分词器)要么带来提升,要么至少不退化;我们也找到了能平衡英语、多语言、代码和数学表现的数据混合(见数据策划的艺术)。我们还将配置优化到在 384 张 GPUS(48 个节点)上达到约 30% 的 MFU。
我们已经准备好打大仗:11T tokens。也正是在这时,现实开始不断抛出难题。
谜题 #1:吞吐量消失
启动后几小时内,吞吐量就断崖式下跌。先是一次大跳水,随后反复出现尖锐下跌。
吞吐量衡量的是训练过程中系统每秒处理的 token 数。它直接决定训练耗时,吞吐量下降 50%,就意味着原本一个月的训练会变成两个月。在基础设施章节里,我们会展示在启动前如何为 SmolLM3 优化吞吐量。
这种情况在任何消融实验中都没出现,那么变化到底在哪里?有三点:
- 硬件状态会随时间变化。在消融中表现正常的 GPU 可能在持续负载下失效,网络连接也可能退化。
- 训练数据集规模变了。我们用了完整约 24 TB 的训练数据集,而不是消融时用的小子集,尽管数据源本身相同。
- 训练步数变了。我们设置了对应 11T tokens 的真实步数,而不是 100B-token 消融所用的短训练周期。
其他所有配置都与吞吐量消融完全一致:节点数、dataloader 配置、模型布局和并行设置……
直觉上,数据集大小和步数都不该导致吞吐量下跌,所以我们首先怀疑硬件问题。我们检查了节点监控指标,发现大幅吞吐波动与磁盘读取延迟峰值相关。这把我们直接指向了数据存储。
对于 SmolLM3 的 24TB 数据集,我们最初把数据存放在 FSx(Weka)上。24TB 的训练数据叠加其他团队已经占用的存储,使我们把 Weka 顶到了容量极限。结果是它在训练中途逐出数据分片,我们不得不反复回拉这些分片,造成停顿,也解释了吞吐量的大幅跳变。更糟的是:我们无法在整个训练期间把数据集目录固定为热数据。
修复 #1:更换数据存储方案
我们在 Weka 上找不到把数据集目录全程固定为热数据的方法,于是尝试更换存储方案。直接从 S3 流式读取太慢,所以我们决定把数据存到每个节点的本地存储 /scratch 。
但这也有代价:如果节点宕机并被替换,新节点上的 GPU 没有数据。用 s5cmd 从 S3 下载 24TB 需要 3 小时。我们改为通过 fpsync 从另一台健康节点复制数据,不再走 S3,把时间缩短到 1 小时 30 分钟。由于所有节点都在同一个数据中心,这个方案更快。
即便如此,每次节点故障就要停机 1 小时 30 分钟,而且还需要立刻手动把数据拷到新节点,仍然很痛苦。最后让流程可接受的“土办法”是:在 Slurm reservation 里预留一个已预载数据的备用节点。一旦某个节点宕机,我们就立刻把它替换成备用节点,实现零恢复延迟。备用节点空闲时还能跑评估或开发任务,不会浪费。
这似乎解决了谜题 #1……至少我们当时是这么以为的。
谜题 #2:持续出现的吞吐量下跌
即使迁移到 scratch 后,吞吐量仍然持续出现单次下跌,而我们在硬件监控指标中并没有发现异常。下图把修复存储问题后的吞吐量(橙色)与消融期间的吞吐量(蓝色)做了对比。可以看到,下跌变得更尖锐了。
仍然怀疑是硬件问题,我们决定减少节点数量做测试。384 张 GPU 的规模下,确实很容易有某处失败。出乎意料的是,无论测试哪一台节点,我们都能在单节点上复现完全相同的吞吐量下跌。这排除了硬件问题。
还记得与消融相比变化的三件事吗?数据存储问题我们已经通过迁移到本地存储解决了;硬件也被排除。那就只剩下一个变量:训练步数。我们把步数从 3M 回退到 32k 后,吞吐量下跌变小了!步数越大,下跌越尖锐、越频繁。
为验证这一点,我们运行了仅训练步数不同(从 32k 到 3.2M)的同配置实验。你可以查看我们使用的完整配置:
## Short run (32k steps)
- "lr_decay_starting_step": 2560000
- "lr_decay_steps": 640000
- "train_steps": 3200000
## Long run (3.2M steps)
+ "lr_decay_starting_step": 26000
+ "lr_decay_steps": 6000
+ "train_steps": 32000
图中的结果非常清楚:短跑实验只有轻微吞吐量下跌,而长步数实验会出现更尖锐、更频繁的下跌。所以问题不是硬件,而是软件瓶颈,很可能出在 dataloader!因为大多数其他训练组件在每个 batch 上的处理并不依赖总步数。
这时我们才意识到,我们其实从未在大规模预训练中真正使用过 nanotron 的 dataloader。SmolLM2 是通过 nanotron 的内部封装,使用一个源自 Megatron-LM 的 dataloader(TokenizedBytes)稳定训练出来的。到了 SmolLM3,我们切换到了 nanotron 内置的 dataloader( nanosets )。
深入实现后我们发现,它在朴素地构建一个随训练步数增长的巨型索引。步数很大时,这会导致共享内存占用升高,从而触发吞吐量下跌。
修复 #2:引入 TokenizedBytes dataloader
为了确认 dataloader 确实是罪魁祸首,我们用内部 SmolLM2 框架和 TokenizedBytes dataloader 启动了同样配置。没有下跌。即使在使用同一批数据集的 48 节点上也是如此。
最快的推进路径:把这个 dataloader 复制进 nanotron。下跌消失了,吞吐量也回到了目标值。
我们准备再次启动……直到下一个难题出现。
谜题 #3:噪声很大的 loss
换用新 dataloader 后,我们不再有吞吐量下跌,但 loss 曲线看起来更嘈杂。
nanosets 产生的 loss 一直更平滑,这个差异让我们想起了一场旧的调试战:几年前我们曾在预训练代码里发现一个打乱 bug,文档被打乱了,但 batch 内序列没有被打乱,从而导致小尖峰。
检查新 dataloader 后也证实了这一点:它会按顺序读取每个文档中的序列。对于短文件这没问题,但在代码等领域中,单个低质量长文件就可能填满整个 batch,导致 loss 尖峰。
修复 #3:在序列级别打乱
我们有两个选择:
- 修改 dataloader 以支持随机访问(风险:内存占用更高)。
- 离线预打乱已分词序列。
在必须尽快重启训练、且集群 reservation 持续消耗的时间压力下,我们选择了选项 #2,作为更稳妥且更快的修复。分词后的数据本来就在每个节点上,所以本地重排成本很低(约 1 小时)。我们还为每个 epoch 使用不同 seed 生成打乱序列,避免跨 epoch 重复相同的打乱模式。
面对紧急截止日期时,采用成熟方案或快速绕行往往比修自己有问题的实现更快。前面我们是直接接入 TokenizedBytes dataloader,而不是去修 nanosets 的索引实现;这里我们选择了离线预打乱,而不是改 dataloader 本身。但也要知道何时该走捷径,何时不该,否则系统最终会变成难以维护和优化的补丁拼盘。
二次发车
到这时我们已经实现了:
- 稳定吞吐量 (scratch 存储 + 备用节点策略)
- 不再有由步数引发的下跌 (
TokenizedBytesdataloader) - 干净的序列级打乱 (每个 epoch 离线预打乱)
我们重新启动了训练。这一次一切稳定:loss 曲线平滑,吞吐量稳定,我们终于可以专注训练本身,而不是持续救火。
谜题 #4:性能不理想
修复吞吐量和 dataloader 问题后,我们再次启动训练,并在前两天顺利推进。吞吐量稳定,loss 曲线符合预期,日志里看不出异常。然而在大约 1T token 时,评估结果暴露了意外。
作为监控流程的一部分,我们会评估中间 checkpoint,并与历史运行做对比。例如,我们有 SmolLM2(1.7B)在类似配方下训练得到的中间 checkpoints,因此可以对齐训练阶段比较两个模型的进展。结果令人困惑:尽管 3B 模型参数更多、数据混合更优,但在同一训练阶段的表现反而比 1.7B 更差。loss 仍在下降、基准分数也在上升,但提升速度明显低于预期。
考虑到我们已经充分测试了 SmolLM3 相对 SmolLM2 引入的每项架构与数据变更,也验证了训练框架,两个训练设置之间仍未被验证的差异其实只剩很少。最显眼的是张量并行(TP)。SmolLM2 可以单卡容纳,因此训练时不需要 TP;而 SmolLM3 需要 TP=2 才能放进显存。我们之前并未怀疑这一点,也没想到要测试,因为 TP 在 3B 消融里用过且结果看起来合理。
修复 #4:最终修复
为了验证 TP bug 假设,我们用与 SmolLM3 完全一致的设置训练了一个 1.7B 模型:相同架构改动(document masking、NoPE)、相同数据混合、相同超参数,并分别开启与关闭 TP。差异立刻出现:TP 版本的 loss 持续更高、下游性能更低于非 TP 版本。这确认了问题与 TP 相关。
随后我们详细检查了 TP 实现,对比 TP 与非 TP 运行得到的权重。问题很隐蔽但影响显著:我们在所有 TP rank 上使用了相同随机种子,而正确做法是每个 rank 使用不同 seed。这导致不同分片之间权重初始化相关,进而影响收敛。影响并非灾难性的,模型仍能训练并改进,但足以解释我们在大规模训练时观察到的性能差距。 下面是 bug 修复:
diff --git a/src/nanotron/trainer.py b/src/nanotron/trainer.py
index 1234567..abcdefg 100644
--- a/src/nanotron/trainer.py
+++ b/src/nanotron/trainer.py
@@ -185,7 +185,10 @@ class DistributedTrainer:
):
# Set random states
- set_random_seed(self.config.general.seed)
+ # Set different random seed for each TP rank to ensure diversity
+ tp_rank = dist.get_rank(self.parallel_context.tp_pg)
+ set_random_seed(self.config.general.seed + tp_rank)
+
在修复 seed、确保每个 TP rank 使用不同 seed 后,我们重新做了消融实验,并确认 TP 与非 TP 运行在 loss 曲线和下游性能上已经对齐。为排除其他隐藏问题,我们又做了额外健全性检查:一个 3B 参数的 SmolLM2 风格运行(架构和数据都对齐 SmolLM2),以及一个独立的 3B 参数 SmolLM3 运行,并把两者都与 SmolLM2 的 checkpoints 对比。结果终于符合预期:1.7B 的 SmolLM2 表现低于 3B 的 SmolLM2 变体,而后者又低于 SmolLM3 的 3B 表现。
这次调试过程再次强化了我们在本文前面提出的一条核心原则:
“扎实的消融体系价值不仅在于构建好模型本身。当主训练运行中不可避免地出问题时(无论准备多充分,问题都会发生),我们希望能对每个决策有把握,并快速定位哪些组件没有被充分验证、最可能导致故障。这种准备能节省大量调试时间,也能保住心态。最糟糕的莫过于面对神秘训练故障,却完全不知道 bug 可能藏在哪里。”
正因为训练中的其他组件都已经被验证,我们才能把 TP 锁定为唯一合理原因,并在发现性能差距后的 1 天内修复该 bug。
至此,我们解决了自启动以来一连串意外问题中的最后一个。事不过三,从那以后,剩下一个月的训练基本风平浪静,只是在少数节点故障时偶尔重启,其余时间就是稳定地把万亿级 tokens 锻造成最终模型。
稳住节奏
正如上一节所示,从消融实验扩展到完整预训练并不是简单的“即插即用”。这个过程带来了意料之外的挑战,但我们最终逐一定位并解决了问题。本节将介绍大规模训练运行所需的关键监控配置与注意事项。我们会回答几个核心问题:遇到问题后应在何时重启训练?对于在训练后期才暴露的问题该如何处理?哪些指标才真正重要?是否应该在整个训练过程中保持固定的数据混合配方?
训练监控:不止看 loss 曲线
我们之所以能发现 tensor-parallelism 的 bug,并不是因为 loss 曲线(它看起来一切正常),而是因为下游评估明显落后于预期。此外,SmolLM2 中间 checkpoints 的评估结果也至关重要:它们提供了 sanity check,让我们能在早期判断 3B 模型是否走在正确轨道上。因此,如果你在训练大模型,请尽早开始跑下游评估;如果你在与开源模型对比,也可以询问作者是否能提供中间 checkpoints,这些通常是非常有价值的参考点。
在基础设施层面,最重要的指标是吞吐量,通常以每秒处理的 tokens 数来衡量。对于 SmolLM3,我们预期全程吞吐量稳定在 13,500–14,000 tokens/sec,任何持续偏离都应视为危险信号。但仅有吞吐量还不够:你还需要持续进行硬件健康监控,以便提前预判并及时发现硬件故障。我们重点跟踪的指标包括 GPU 温度、显存占用和计算利用率。我们将这些数据记录到 Grafana 仪表盘,并为硬件异常配置实时 Slack 告警。
修复并重启,还是边跑边修
鉴于我们在 1T tokens 后重启了训练,一个重要问题随之而来:一旦出现问题,是否总要重启?答案取决于问题的严重程度和根本原因。
在我们的案例中,TP seeding bug 意味着我们从一开始就偏离了正确轨道,有一半权重没有被正确初始化。模型表现与 SmolLM2 相近,并在相近位置进入平台期,这意味着我们最终很可能得到一个性能差不多、但训练成本几乎翻倍的模型。重启是合理的。不过,许多问题其实可以在训练中途纠偏,以避免浪费算力。最常见的问题是 loss spikes :训练损失突然跳升,这既可能只是短暂波动,也可能意味着模型正在发散。
正如 Stas Bekman 在 Machine Learning Engineering Open Book 中所说:“训练损失曲线就像心跳图,有好的,有坏的,还有那些你必须警惕的。”
{kind=link}
loss spikes 可分为两类:
- Recoverable spikes: 可以快速恢复(尖峰后立即回归),也可以慢速恢复(需要额外若干训练步才能回到尖峰前轨迹)。这类情况通常可以继续训练。如果恢复非常慢,可以尝试回退到更早的 checkpoint,跳过有问题的 batch。
- Non-recoverable spikes: 模型要么发散,要么停留在比尖峰前更差的性能平台上。这类问题往往需要比“回退到前一个 checkpoint”更强的干预手段。
虽然我们还没有完全理解训练不稳定性的机理,但可以确定它在大规模训练中会更频繁地出现。在采用保守架构和优化器的前提下,常见诱因包括:
- 学习率过高:会在训练早期引发不稳定,通常可通过降低学习率修复。
- 数据质量差:通常是可恢复尖峰的主要原因,但恢复可能较慢。这种情况可能发生在训练后段,当模型遇到低质量数据时更常见。
- 数据与参数状态的交互:PaLM (Chowdhery et al., 2022) 观察到,尖峰往往来自特定数据 batch 与模型参数状态的组合,而不只是“坏数据”本身。即使用不同 checkpoint 在同一问题 batch 上继续训练,也未复现相同尖峰。
- 初始化不佳:OLMo2 (OLMo et al., 2025) 的近期工作表明,将缩放初始化改为简单正态分布(mean=0, std=0.02)可以提升稳定性。
- 精度问题:虽然如今几乎没人再用 FP16 训练,但 BLOOM 发现它相较 BF16 明显更不稳定。
在尖峰发生前,先构建稳定性:
小模型在保守学习率和高质量数据下很少出现尖峰,但更大模型需要主动的稳定性措施。随着越来越多团队进行大规模训练,我们积累了一套可用于预防训练不稳定的工具箱:
数据过滤与打乱:看到这里你应该已经发现,我们反复强调数据。确保数据干净且打乱充分,可以显著减少尖峰。例如,OLMo2 发现,移除包含重复 n-gram 的文档(1-13 token 片段重复 32 次以上)能显著降低尖峰频率。
训练层面的改动:Z-loss regularisation 可以在不损害性能的情况下抑制输出 logits 过度增大。将 embeddings 排除在 weight decay 之外也有帮助。
架构层面的改动:QKNorm(在 attention 前对 query 和 key 投影进行归一化)已被证明有效。OLMo2 和其他团队都发现它有助于稳定性;有意思的是,Marin team 发现它甚至可以在训练中途引入,用来修复发散问题。
即便出现尖峰,也要做好损害控制:
即便采取了上述预防措施,尖峰仍可能出现。以下是一些应对选项:
- 跳过问题 batch :回退到尖峰发生前,并跳过问题 batch。这是最常见的尖峰修复手段。Falcon 团队 (Almazrouei et al., 2023) 通过跳过 1B tokens 解决尖峰;PaLM 团队 (Chowdhery et al., 2022) 则发现跳过尖峰位置附近的 200-500 个 batch 可以避免再次出现。
- 收紧梯度裁剪 :临时降低梯度范数阈值。
- 应用架构层面的修复 :例如 Marin 中采用的 QKnorm。
我们已经走过了规模化训练中的一系列挑战:从吞吐量下跌到 TP bug,从用于尽早发现问题的监控实践,到预防和修复 loss spikes 的策略。接下来,让我们用“多阶段训练如何提升模型最终性能”来结束本章。
训练中期
现代 LLM 预训练通常包含多个阶段,每个阶段使用不同的数据混合,最后常接一个用于扩展上下文长度的阶段。例如,Qwen3 (A. Yang, Li, et al., 2025) 采用三阶段方案:先在 4k 上下文长度下用 30T tokens 进行通用训练;随后使用 5T 质量更高、侧重 STEM 与代码的数据进行推理阶段训练;最后再进行一个 32k 上下文长度、数千亿 tokens 的长上下文阶段。SmolLM3 遵循了类似思路:一方面按计划引入更高质量数据集并扩展上下文,另一方面基于训练监控结果做响应式调整。
正如我们在数据策划章节所述,数据混合并不需要在整个训练过程中保持不变。多阶段训练让我们能够随着训练推进,策略性调整各类数据占比。有些干预从一开始就已规划好:对 SmolLM3 而言,我们在 Stage 2 计划引入更高质量的 FineMath4+ 与 Stack-Edu,并在最终衰减阶段加入精选的问答与推理数据。另一些干预是响应式的,由训练过程中的监控结果驱动。例如,在 SmolLM2 中,当我们发现数学与代码能力落后于目标时,我们专门构建了全新数据集(FineMath 和 Stack-Edu),并在训练中期引入。这种灵活性,无论是遵循既定课程还是针对新暴露的短板动态调整,都是最大化算力预算价值的关键。
Stage 2 与 Stage 3 的数据混合
下图展示了我们 3 个训练阶段,以及训练过程中 web/code/math 比例的变化。SmolLM3 各阶段的训练配置和精确数据权重可在这里查看。关于每个阶段背后的设计理由与数据构成,请参考数据策划章节。
Stage 1:基础训练(8T tokens,4k context) 基础阶段使用我们的核心预训练配方:Web 数据(FineWeb-Edu、DCLM、FineWeb2、FineWeb2-HQ),来自 The Stack v2 与 StarCoder2 的代码数据,以及来自 FineMath3+ 与 InfiWebMath3+ 的数学数据。该阶段全部在 4k 上下文长度下训练。
Stage 2:高质量数据注入(2T tokens,4k context) 我们引入过滤质量更高的数据集:代码侧使用 Stack-Edu;数学侧使用 FineMath4+ 与 InfiWebMath4+;并加入 MegaMath 用于更高级的数学推理(同时加入 Qwen Q&A 数据、合成改写数据以及 text-code 交错块)。
Stage 3:在学习率衰减阶段加入推理与问答数据(1.1T tokens,4k context) 在学习率衰减阶段,我们进一步上采样高质量代码与数学数据集,并引入 OpenMathReasoning、OpenCodeReasoning 和 OpenMathInstruct 等指令与推理数据。Q&A 样本采用简单拼接,并用换行分隔。
长上下文扩展:从 4k 到 128k tokens
上下文长度决定了模型一次能处理多少文本。这对分析长文档、维持连贯的多轮对话、或处理完整代码库等任务至关重要。SmolLM3 起始训练于 4k tokens,但在真实应用中我们需要将其扩展到 128k。
为什么要在训练中期扩展上下文?
从一开始就在长上下文上训练计算成本很高,因为注意力机制的计算量会随序列长度呈二次增长。此外,研究表明,在训练后期或持续预训练阶段,用数百亿到千亿 tokens 进行上下文扩展,就足以获得不错的长上下文性能 (Gao et al., 2025)。
顺序扩展:4k→32k→64k
我们没有直接跳到 128k。相反,我们按阶段逐步扩展上下文,让模型在每个长度先完成适应,再继续推进。我们运行了两个长上下文阶段:先从 4k 到 32k,再从 32k 到 64k(128k 能力来自推理阶段外推,而非训练)。我们发现,相比在主训练衰减阶段最后 100B tokens 才扩展上下文,在每个阶段基于 50B tokens 重启一套新的学习率调度效果更好。每个阶段我们都进行了消融实验,以找到更优的长上下文数据混合和 RoPE theta 取值,并在 Ruler 基准上评估。
在长上下文消融实验中,我们发现 HELMET 在 base model 上噪声很大(相同训练设置仅随机种子不同,就会得到波动明显的结果)。Gao et al. 建议先做 SFT,以降低这些基准任务的方差。 因此我们改用 RULER,因为它在 base model 层面给出的信号更稳定。
在这一阶段,常见做法是上采样长文档(如长网页和书籍)以提升长上下文性能 (Gao et al., 2025)。我们做了多组消融实验,上采样了书籍、文章,甚至合成文档(用于检索和 fill-in-the-middle 等任务),并参照 Qwen2.5-1M 的方法 (A. Yang, Yu, et al., 2025) 结合 FineWeb-Edu 与 Python-Edu。令人意外的是,与仅使用 Stage 3 的 baseline 混合相比,我们没有观察到改进;而后者在 Ruler 上已与 Llama 3.2 3B、Qwen2.5 3B 等 SOTA 模型具有竞争力。我们的假设是,baseline 混合本身已自然包含来自 Web 与代码数据的长文档(估计约占 10% tokens),同时 NoPE 也带来了帮助。
RoPE ABF(RoPE with Adjusted Base Frequency): 当从 4k 扩展到 32k 时,我们将 RoPE theta(base frequency)提高到 2M;从 32k 扩展到 64k 时,提高到 5M。我们发现使用 10M 这类更大取值会略微提升 RULER 分数,但会伤害某些短上下文任务(如 GSM8k),因此我们保留了对短上下文几乎无影响的 5M。 在这一上下文扩展阶段,我们也借机进一步上采样了数学、代码和推理 Q&A 数据,并额外加入了数十万条 ChatML 格式样本。
YARN 外推:达到 128k 即使已经在 64k 上下文上训练,我们仍希望 SmolLM3 在推理时支持 128k。与其在 128k 序列上训练(成本高得难以接受),我们采用了 YARN(Yet Another RoPE extensioN method)(B. Peng et al., 2023),使模型能外推出超过训练长度的上下文。理论上,YARN 允许将序列长度提升至原来的四倍。我们发现,使用 64k checkpoint 在 128k 上的表现优于 32k checkpoint,验证了“训练长度越接近目标推理长度越有利”。但当扩展到 256k(相对 64k 再四倍)时,Ruler 性能明显下降,因此我们建议将该模型使用到 128k 为止。
至此,我们完整走完了 SmolLM3 的预训练旅程:从规划与消融实验,到最终训练运行,以及一路上的所有幕后挑战。
预训练收官
我们已经覆盖了大量内容。从帮助我们明确“为什么训练、训练什么”的 training compass,到战略规划、逐项验证架构选择的系统化 ablations,再到真正的 training marathon:一旦上规模,意外就会接连出现(throughput 莫名下滑、dataloader 成为瓶颈,以及一个隐蔽的 tensor parallelism bug,让我们在 1T tokens 时不得不重启)。
至此,那些技术报告中被打磨过的表象背后,真实而复杂的一面已经很清楚: 训练 LLMs,既关乎 architecture innovations 与 data curation,也同样依赖严谨的 experimentation 和快速 debugging。 planning 决定什么值得测试。ablations 验证每一项决策。monitoring 让问题尽早暴露。而当系统不可避免地出故障时,系统化的 derisking 会直接指向排查入口。
就 SmolLM3 而言,这套流程确实交付了我们最初设定的目标:一个在 11T tokens 上训练出的 3B model,在 math、code、multilingual understanding 和 long-context tasks 上都具备竞争力,并跻身 Qwen3 models 的 Pareto frontier。
当 base model checkpoint 已经保存、训练结束、GPU 终于开始降温时,我们很容易觉得可以收工了。毕竟,这个模型已经具备很强的 text prediction 能力,benchmark 分数也不错,目标能力基本都已达成。
但还不能。因为今天用户真正需要的是 assistants 和 coding agents,而不是裸露的 next-token predictors。
post-training 正是在这里登场。而且和 pretraining 一样,真实过程远比论文里看起来更复杂。
超越基础模型:2025 年的后训练
预训练一结束,我们应该能在一天内拿到一个 SFT baseline
预训练赋予了 SmolLM3 原始能力,但在 GPU 还没完全降温之前,我们就进入了模型能力的下一前沿: 后训练(post-training) 。这包括监督微调(supervised fine-tuning)、强化学习(reinforcement learning)、模型合并(model merging)等,目标都是弥合“会预测文本的模型”与“人们真正能用的模型”之间的差距。若说预训练是在权重中强行注入知识,后训练就是把这份原始能力雕琢成可靠、可控的系统。和预训练一样,精修过的后训练论文并不会写出那些深夜里的意外:GPU 崩溃、脆弱的数据混合配方,或者一个看似微小的 chat template 决策如何层层传导到下游基准。本节我们会展示,如何在复杂而混乱的后训练世界中推进,把 SmolLM3 从一个强大的 base model 打造成 SOTA 的混合推理模型。
混合推理模型有两种不同的工作模式:一种用于简洁、直接的回答,另一种用于更长链路的逐步推理。通常,运行模式由用户在 system message 中设定。我们沿用 Qwen3 的做法,用轻量命令显式切换:“/think” 启用扩展推理,“/no_think” 强制简洁回答。这样用户就能自行控制模型是优先深度还是优先速度。
后训练指南:why → what → how
与 pre-training 一样,post-training 也需要一个清晰的指南针,以避免浪费研究与工程迭代周期。可以按下面的方式来框定:
-
为什么要做后训练? 我们在预训练指南中提到的三类训练动机(研究、生产和战略性开源)同样适用于后训练。比如,你可能在探索 RL 是否能为现有模型解锁新的推理能力(研究);也可能因时延约束需要把大模型蒸馏为小模型(生产);或者你发现某个特定用例没有足够强的开源模型(战略性开源)。区别在于:后训练是建立在已有能力之上,而不是从零创造能力。不过,在调动 GPU 之前,先问自己:
- 你真的需要后训练吗?如今很多开放权重模型在大量任务上已可比肩闭源模型。部分模型甚至可以在量化后,用有限算力本地运行。如果你要的是通用助手,来自 Hugging Face Hub 的现成模型可能已经满足需求。
- 你是否能拿到高质量、领域相关的数据?当你的目标任务或领域里通用模型表现不足时,后训练最有价值。有了合适的数据,你可以让模型在最关键应用上输出更准确的结果。
- 你能否衡量成功?如果没有清晰的评估标准,你将无法判断后训练是否真的有效。
-
后训练应该达成什么? 这取决于你的优先级:
- 你是否希望得到一个执行指令干脆、很少跑题的 instruction-follower?
- 一个能按需切换语气与角色的多面助手?
- 一个能处理数学、代码或 agentic 问题的推理引擎?
- 一个能进行多语言对话的模型?
-
你将如何实现? 这时配方(recipes)就很关键。我们会覆盖:
- 监督微调(SFT) 来注入核心能力。
- 偏好优化(PO) 来直接从人类或 AI 偏好中学习。
- 强化学习(RL) 来在监督数据之外进一步提升可靠性与推理能力。
- 数据策划(Data curation) 来在多样性与质量之间取得平衡。
- 评估(Evaluation) 来追踪进展并尽早发现回归。
这个指南针能让后训练中的混乱保持在可控范围内: why 提供方向, what 设定优先级, how 把目标转化为可执行的训练循环。
下面看我们如何为 SmolLM3 回答这些问题:
- Why? 对我们来说,这个“why”很直接:我们有一个发布前必须完成后训练的 base model。与此同时,像 Qwen3 这样的混合推理模型越来越流行,但公开的训练配方仍然稀缺。SmolLM3 让我们有机会同时做到两件事:让模型可用于真实场景,并贡献一套完整开源配方,使其能与 Qwen3 的 1.7B 和 4B 模型一起位于 Pareto front。
- What? 我们要训练的是一个贴合 SmolLM3 优势的混合推理模型,尤其是要保证其在英语之外语言上的推理质量。同时,现实应用越来越依赖 tool calling 和 long-context workflow,因此这两项也成为我们后训练配方的核心要求。
- How? 这就是本章剩余内容 😀。
与 pre-training 一样,我们先从基本功开始:evals 和 baselines,因为每个大模型都始于一个小型消融实验。但后训练中的消融有一个关键差异。在 pre-training 里,“小”通常意味着更小的模型与数据集;在 post-training 里,“小”更多意味着更小的数据集和 更简单 的 算法 。我们几乎不会在消融中换一个不同的 base model,因为模型行为高度依赖具体模型本身,而且后训练单次运行足够短,可以直接在目标模型上迭代。
让我们从一个很多模型训练者直到项目后期才会认真面对的话题开始:evals。
先做最重要的事:把 evals 放在一切之前
后训练的第一步和预训练一样,都是先确定一套合适的 evals。鉴于如今大多数 LLM 都被当作助手使用,我们发现,相比追逐 ARC-AGI 这类抽象的“智能”基准,把目标设为“模型是否真正好用”更实际。那么,一个好助手要做到什么?至少应具备:
- 处理含糊不清的指令
- 逐步规划
- 编写代码
- 在合适时机调用工具
这些行为依赖多种能力组合:推理、长上下文处理,以及数学、代码和工具使用能力。参数规模在 3B 左右甚至更小的模型也可以作为不错的助手,但当规模低于 1B 时,性能通常会明显下滑。
在 Hugging Face,我们使用分层的评估套件(layered eval suite),沿用了我们在预训练消融章节中总结的原则:单调性、低噪声、高于随机的有效信号、以及排名一致性。
随着模型持续进步,可选的 evals 列表也在不断变化。下面提到的内容反映的是我们在 2025 年年中的关注重点。想全面了解后训练评估,可参考 Evaluation Guidebook。
下面是评估后训练模型的几类常见方式:
- 能力评估(Capability evals)
这类评估针对基础能力,例如推理、竞赛数学和代码能力。
- 知识。 目前我们使用 GPQA Diamond (Rein et al., 2024) 作为科学知识的主评估。该基准由研究生水平的多项选择题构成。对小模型而言,它远未饱和,信号通常比 MMLU 等基准更好,而且运行更快。另一个检验事实性的好基准是 SimpleQA (Wei et al., 2024),不过受限于知识容量,小模型在这个基准上通常表现较弱。
- 数学。 为了衡量数学能力,如今大多数模型会在最新版本的 AIME 上评估(目前是 2025 版)。MATH-500 (Lightman et al., 2023) 对小模型仍是有价值的 sanity check,但对推理模型来说已基本饱和。若想覆盖更全面的数学评估,我们推荐 MathArena。
- 代码。 我们使用最新版 LiveCodeBench 跟踪代码能力。尽管它主要面向竞赛编程题,我们观察到 LiveCodeBench 的提升确实会转化为更强的代码模型,但这种相关性主要体现在 Python。SWE-bench Verified 是更复杂的代码能力指标,但通常对小模型过难,因此不属于我们常用评估。
- 多语言。 遗憾的是,评测模型多语言能力的选择并不多。我们目前主要依赖 Global MMLU (Singh et al., 2025) 来覆盖模型重点语言,并加入 MGSM (Shi et al., 2022) 评估多语言数学能力。
- 综合任务评估(Integrated task evals)
这类评估更贴近我们最终要交付的能力:多轮推理、长上下文使用,以及半真实场景中的工具调用。
- 长上下文。 长上下文检索最常见的测试是 Needle in a Haystack(NIAH)(Kamradt, 2023):把一个随机事实(“needle”)放入长文档(“haystack”)中,要求模型检索出来。但这个基准过于表层,不足以区分真正的长上下文理解能力,因此社区发展出了更全面的评估,如 RULER (Hsieh et al., 2024) 和 HELMET (Yen et al., 2025)。最近 OpenAI 还发布了 MRCR 与 GraphWalks 基准,进一步提高了长上下文评估难度。
- 指令遵循。 IFEval (J. Zhou et al., 2023) 目前是最常用的指令遵循评估,基于“可验证指令”进行自动打分。IFBench (Pyatkin et al., 2025) 是 Ai2 的新扩展,包含比 IFEval 更多样的约束,并缓解了近来模型发布中出现的一些刷榜化(benchmaxxing)现象。对于多轮指令遵循,我们推荐 Multi-IF (He et al., 2024) 或 MultiChallenge (Sirdeshmukh et al., 2025)。
- 对齐。 衡量模型对用户意图的对齐程度,通常依赖人工标注或 LMArena 这类公开榜单。原因是自由生成质量、风格或整体有用性等属性,很难用自动化指标做量化。然而这类评估成本很高,因此社区普遍会用 LLM 充当人类偏好的代理。此类最常见基准包括 AlpacaEval (Dubois et al., 2025)、ArenaHard (T. Li et al., 2024) 和 MixEval (Ni et al., 2024);其中 MixEval 与 LMArena 人类 Elo 评分的相关性最强。
- 工具调用。 BFCL 提供了相对全面的工具调用测试,但往往很快饱和。TAU-Bench (Barres et al., 2025) 在模拟客服场景中评估模型的工具使用与问题解决能力,也已成为常被报告的热门基准。
- 防过拟合评估(Overfitting-prevention evals)
为了检验模型是否对某项能力过拟合,我们会加入鲁棒性或适应性评估。例如 GSMPlus (Q. Li et al., 2024) 会扰动 GSM8k (Cobbe et al., 2021) 的题目,测试模型在相近难度问题上是否仍然可解。
- 内部评估(Internal evals)
公开基准在模型开发过程中能提供一定信号,但它不能替代你自己的内部评估,也不能替代让内部专家直接与模型交互,以验证特定能力。
例如,对 SmolLM3 来说,我们需要一个能评估模型是否具备 多轮 推理 能力的基准,因此我们实现了 Multi-IF 的一个变体来测量它。
- Vibe 测评与竞技场(Vibe evaluations and arenas)
我们同样发现,对中间 checkpoint 做“vibe testing”(即亲自与模型交互)对于发现 eval 分数捕捉不到的细微行为问题至关重要。正如后文会提到的,vibe testing 曾帮我们发现数据处理代码中的一个 bug:语料中的所有 system messages 都被删掉了。 这类评估也可以规模化,用来衡量人类偏好,例如在 LMArena 上进行。但众包人类评估往往比较脆弱(偏好迎合与辞藻,而非真实有用性),因此应将其视为低信号反馈。
依赖公开基准的一个风险是,模型很容易被“刷”到这些基准上,尤其当你用合成数据生成与目标基准相似的 prompt 和 response 时更是如此。因此,必须针对用于指导开发的评估集,对训练数据做去污染。你可以用 N-gram 匹配来完成,例如 Open-R1 中的脚本。
就 SmolLM3 而言,我们希望构建一个混合推理模型:既能稳定遵循指令,又能在数学和代码等常见领域具备良好推理能力。同时,我们也希望保留 base model 在多语言和长上下文检索上的能力。
这带来了我们最终采用的这组 evals:
| 基准 | 类别 | 提示数量 | 指标 |
|---|---|---|---|
| AIME25 | 竞赛数学 | 30 | avg@64 |
| LiveCodeBench(验证用 v4,最终发布用 v5) | 竞赛编程 | 100 (268) | avg@16 |
| GPQA Diamond | 研究生水平推理 | 198 | avg@8 |
| IFEval | 指令遵循 | 541 | accuracy |
| MixEval Hard | 对齐 | 1000 | accuracy |
| BFCL v3 | 工具使用 | 4441 | mixed |
| Global MMLU(验证使用 lite 版本) | 多语言问答 | 590,000 (6,400) | accuracy |
| GSMPlus(验证使用 mini 版本) | 鲁棒性 | 10,000 (2,400) | accuracy |
| RULER | 长上下文 | 6,500 | accuracy |
下面我们从每个基准中看几个示例题,直观感受这些评估到底在测什么:
浏览上面的示例,你会看到不同基准各自的问题类型。它们覆盖了不同领域,确保我们在整套消融实验中能持续检验模型能力的不同维度。
对于我们当时使用的 3B 模型规模,这组 evals 能提供可执行信号,运行速度也快于训练本身,并让我们更有把握确认提升是真实的,而不是采样噪声。我们也同步跟踪了预训练阶段的 evals(完整列表见消融章节),确保 base model 能力没有明显退化。
上面的叙述看起来像是:我们团队先坐下来统一评估集,然后在训练前全部准备完毕。现实要混乱得多。我们的截止时间很紧,因此在上面很多 evals 尚未实现时就匆忙启动了训练(例如 RULER 直到模型发布前几天才可用 🙈)。现在回看,这是一个 错误。我们本该更早与预训练团队讨论:哪些核心 evals 需要在后训练阶段持续保留,并在 base model 训练完成前很久就把它们优先实现。换句话说,先把 evals 排到最高优先级。
行动准则
让我们用几条“从评估过成千上万模型后换来的经验教训”来总结这一节:
- 在模型开发阶段,使用 小规模子集来加速评估 。例如,LiveCodeBench v4 与 v5 的相关性很高,但运行时间只有后者的一半。你也可以使用 tinyBenchmarks (Polo et al., 2024) 一类方法,寻找能稳定代表全量评估结果的最小提示子集。
- 对于 推理模型 ,要从 计分输出 中去除 chain-of-thought。这能减少误判(false positives),也会直接影响 IFEval 这类基准,因为它会惩罚违反约束的回答(例如“把诗写在 50 个词以内”)。
- 如果某个评估使用 LLM 评审器(judge) ,请固定评审模型及其版本,以便长期进行可比对(apples-to-apples)的比较。更理想的是使用开源权重模型,这样即使服务商下线了评审模型,评估仍可复现。
- 要警惕 base model 中的 污染(contamination) 。例如,大多数在 AIME 2025 之前发布的模型,在 AIME 2025 上显著差于 AIME 2024,这表明可能存在 benchmaxxing 现象。
- 在条件允许时,把消融阶段使用的一切都视作 验证集(validation) ,而不是 测试集(test) 。这意味着要像 Tulu3 评估框架 (Lambert et al., 2025) 那样,为最终模型报告保留一组真正留出的基准。
- 始终在你自己的数据和任务上保留一小组 “vibe evals” ,以捕捉模型对公开基准过拟合的问题。
- 对于题量较小的评估(通常少于约 2k 题),请采样
k次并报告avg@k准确率。这对抑制噪声很关键,否则开发阶段很容易做出错误决策。 - 实现新评估时,请先确保你 能够复现若干已发布模型的公开结果 (允许一定误差)。否则后续一旦需要修实现并重评大量 checkpoint,会浪费很多时间。
- 如果拿不准,就回到评估数据本身,重点检查你到底在用什么提示词(prompt)喂给模型。
评估准备就绪后,就该开始训练模型了!但在此之前,我们先需要选定一个后训练框架。
工具箱:常用训练框架
每一套后训练配方背后,都有一组支撑大规模实验的框架与库。每个框架在支持的算法、微调方式和可扩展能力上各有侧重。下表汇总了主要能力覆盖范围,从监督微调(SFT)到偏好优化(PO)和强化学习(RL):
| 框架 | SFT | PO | RL | 多模态 | FullFT | LoRA | 分布式 |
|---|---|---|---|---|---|---|---|
| TRL | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Axolotl | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| OpenInstruct | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
| Unsloth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| vERL | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Prime RL | ✅ | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ |
| PipelineRL | ❌ | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ |
| ART | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ |
| TorchForge | ✅ | ❌ | ✅ | ❌ | ✅ | ❌ | ✅ |
| NemoRL | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ |
| OpenRLHF | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
这里的 FullFT 指 全参数微调 ,即在训练中更新模型的全部参数。 LoRA 是 Low-Rank Adaptation(低秩适配) ,这是一种参数高效方法:在冻结基座模型的同时,只更新少量低秩矩阵。 Multi-modal 表示是否支持文本之外模态(如图像)的训练, Distributed 表示是否支持在多张 GPU 上训练模型。
在 Hugging Face,我们开发并维护 TRL,因此它是我们的首选框架,也是我们用于 SmolLM3 后训练的框架。
考虑到这个领域变化极快,我们发现基于 TRL 的内部 fork 来运行实验非常高效。这样可以让我们快速添加新功能,后续再回流到主库。如果你熟悉所用框架的内部实现,采用类似工作流会是实现快速迭代的有力方法。
为什么还要使用训练框架?
有一类研究者很喜欢批评训练框架,转而主张你应该始终从零实现一切。这里隐含的说法是:只有把每个 RL 算法都重写一遍、手工编码每个分布式训练原语,或临时拼一个一次性评测 harness,才算“真正”理解。
但这种立场忽略了现代研究和生产的现实。以 RL 为例,像 PPO 和 GRPO 这样的算法在“正确实现”上出了名地棘手 (Huang et al., 2024),而归一化或 KL 惩罚里的微小错误,就可能造成数天的算力与人力浪费。
同样,虽然把某个算法写成单文件实现很诱人,但同一份脚本真能从 1B 扩展到 100B+ 参数规模吗?
框架之所以存在,恰恰是因为基础问题已经被充分理解,而无休止地重复造轮子并不划算。这并不意味着底层折腾没有价值。亲手从零实现一次 PPO 是很好的学习练习;不借助框架写一个玩具 Transformer,也能帮助你真正理解注意力机制。但在大多数情况下,更务实的做法是选一个你顺手的框架,然后按自己的需求改造它。
说完这段“吐槽”,下面我们看看自己通常从哪里开始训练流程。
为什么(几乎)所有后训练流程都从 SFT 开始
如果你最近经常刷 X,可能会觉得强化学习(RL)几乎成了唯一值得讨论的方向。每天都会出现新的缩写、算法改动,以及关于 RL 是否真的能激发新能力的激烈争论 (Chu et al., 2025; Yue et al., 2025)。
当然,RL 并不新鲜。OpenAI 和其他实验室很早就大量依赖基于人类反馈的强化学习(RLHF)(Lambert et al., 2022) 来对齐早期模型,但直到 DeepSeek-R1 发布 (DeepSeek-AI, Guo, et al., 2025),基于 RL 的后训练才在开源生态里真正流行起来。
但有一件事没变:几乎所有有效的后训练流程仍然从监督微调(SFT)开始。原因很直接:
- 成本低: 与 RL 相比,SFT 所需算力更温和。通常不需要“烧”大量芯片,就能拿到有意义的提升,而且耗时只是 RL 的一小部分。
- 稳定: RL 对奖励设计和超参数高度敏感,而 SFT 往往“就是能跑通”。
- 是正确的 baseline: 一个高质量的 SFT checkpoint 往往已经覆盖了你想要的大部分收益,同时也会让后续的 DPO 或 RLHF 更有效。
在实践中,这意味着 SFT 并不只是因为“简单”才作为第一步;在尝试更复杂方法之前,它是最稳定、最持续带来性能提升的一步。尤其当你面对的是 base model 时,这一点更明显。除少数例外,base model 通常还不够成熟,难以直接从高级后训练方法中受益。
在前沿场景里,从 SFT 开始的常见理由并不总成立。你可能没有更强的模型可供蒸馏,人类标注对于长 chain-of-thought 这类复杂行为也往往噪声太大。因此 DeepSeek 跳过了 SFT,直接用 R1-Zero 进入 RL;目的是去 发现 那些无法通过标准监督直接教会的推理行为。
如果你正处在这个范式里,从 RL 起步是合理的。但如果你已经在那个层级……你大概率也不会在看这篇博客 😀。
所以,如果大多数流程都从 SFT 开始,下一个问题就是:你应该微调 什么 ?这要从选对 base model 开始。
选择 base model
在为后训练选择 base model 时,有几个实用维度最关键:
- 模型规模: 尽管 smol 模型这些年进步显著,但在当下,更大的模型通常仍有更好的泛化能力,而且往往所需样本更少。应选择能代表你训练后实际使用或部署形态的模型规模。在 Hugging Face Hub 上,你可以按模态和参数规模筛选候选模型:
- 架构(MoE vs Dense): MoE 模型会为每个 token 只激活部分参数,在单位计算量下提供更高容量。它们在大规模服务场景很有吸引力,但按我们的经验,微调更棘手。相比之下,Dense 模型训练更简单,并且在较小规模上常常优于 MoE。
- 后训练履历: 基准分数固然有用,但如果某个 base model 已经孵化出一批受社区认可的强后训练模型,会更有参考价值。这可以作为该模型是否“容易训好”的代理信号。
根据我们的经验,Qwen、Mistral 和 DeepSeek 的 base model 都比较适合做后训练,其中 Qwen 尤其突出,因为每一代模型通常覆盖很宽的参数区间(例如 Qwen3 从 0.6B 到 235B)。这一点会让后续扩展更直接。
当你选定与部署需求匹配的 base model 后,下一步就是建立一个简单、快速的 SFT baseline,用来探查它的核心能力。
训练简单 baseline
对于 SFT,一个好的 baseline 应该具备几个特征:训练快、聚焦模型核心能力,并且当某项能力不足时,能方便地通过加入更多数据进行扩展。为初始 baseline 选择哪些数据集,既需要一定判断,也需要你熟悉哪些数据集更可能具备高质量。总体来说,不要过度依赖那些在学术基准上分数很高的公开数据集,而应更多关注那些已被用于训练优秀模型(如 OpenHermes)的数据。例如,在开发 SmolLM1 时,我们最初使用 WebInstruct 做 SFT。它在“纸面上”是个很好的数据集,但在 vibe 测试中我们发现它过于偏重科学内容,模型甚至会对 “How are you?” 这类简单问候直接回公式。
这促使我们创建了 Everyday Conversations 数据集。事实证明,它对在小模型中注入基础对话能力至关重要。
在 SmolLM3 中,我们的目标是训练一个混合推理模型,因此最初挑选了一组小规模数据集,重点覆盖推理、指令遵循和可控性(steerability)。下表展示了各数据集的统计信息:1
| 数据集 | 推理模式 | 样本数 | 样本占比 (%) | token 数 (M) | token 占比 (%) | 平均每样本 token 数 | 平均上下文 token 数 | 平均回复 token 数 | 平均轮次 |
|---|---|---|---|---|---|---|---|---|---|
| Everyday Conversations | /no_think | 2,260 | 2.3 | 0.6 | 0.8 | 260.2 | 222.3 | 94.0 | 7.8 |
| SystemChats 30k | /no_think | 33,997 | 35.2 | 21.5 | 28.2 | 631.9 | 422.8 | 267.7 | 6.3 |
| Tulu 3 SFT Personas IF | /no_think | 29,970 | 31.0 | 13.3 | 17.5 | 444.5 | 119.8 | 380.7 | 2 |
| Everyday Conversations (Qwen3-32B) | /think | 2,057 | 2.1 | 3.1 | 4.1 | 1,522.4 | 376.8 | 1,385.6 | 4 |
| SystemChats 30k (Qwen3-32B) | /think | 27,436 | 28.4 | 29.4 | 38.6 | 1070.8 | 84.6 | 1,042.7 | 2 |
| s1k-1.1 | /think | 835 | 0.9 | 8.2 | 10.8 | 8,859.3 | 370.9 | 9,728.5 | 2 |
| Total | - | 96,555 | 100.0 | 76.1 | 100.0 | 2,131.5 | 266.2 | 2,149.9 | 4.0 |
正如我们在 SmolLM3 开发过程中学到的,训练混合推理模型比标准 SFT 更棘手,因为你不能只是把数据集简单混在一起,而是需要在不同模式之间对数据进行 配对 。每条样本都必须明确告诉模型:此处应该进行扩展推理,还是给出简洁回答;理想情况下,你还需要并行样本来教会模型何时切换模式。上表还有一点很关键:平衡数据混合时,应该按 token 而不是按 样本数 。例如,s1k-1.1 只占总样本数约 1%,但由于推理回答更长,它贡献了约 11% 的总 token。
这让我们在最关注的能力上获得了基础覆盖,但也带来了新挑战:每个数据集的格式都要根据是否启用扩展思考而不同。为了统一这些格式,我们需要一个一致的 chat template。
选择合适的 chat template
在选择或设计 chat template 时,并不存在放之四海皆准的答案。根据我们的实践经验,先问清楚以下几个问题通常很关键:
- 用户能否自定义 system role? 如果用户需要定义自己的 system prompt(例如 “act like a pirate”),template 就必须能干净地支持这一点。
- 模型是否需要工具调用? 如果模型需要调用 API,template 就必须支持 tool call 和响应的结构化输出。
- 它是否是推理模型? 推理模型会使用
<think> ... </think>这类模板,把模型“思考过程”和最终回答分开。一些模型会在多轮对话中丢弃中间轮次的推理 tokens,因此 chat template 需要处理这套逻辑。 - 它能否与推理引擎兼容? vLLM 和 SGLang 这类推理引擎对推理和工具调用有专用 parser2。与这些 parser 兼容能在后期省去大量麻烦,尤其在复杂 agent 基准中,一致的工具调用是必需条件。3
下表给出几个常见 chat template,并从关键维度做了对比:
| Chat template | System role 自定义 | Tools | Reasoning | Inference 兼容性 | 备注 |
|---|---|---|---|---|---|
| ChatML | ✅ | ✅ | ❌ | ✅ | 简单,适合大多数场景。 |
| Qwen3 | ✅ | ✅ | ✅ | ✅ | 混合推理模板。 |
| DeepSeek-R1 | ❌ | ❌ | ✅ | ✅ | 会通过 <think> 预填充推理内容。 |
| Llama 3 | ✅ | ✅ | ❌ | ✅ | 内置工具能力,如 Python 代码解释器。 |
| Gemma 3 | ✅ | ❌ | ❌ | ❌ | system role 自定义在首轮 user 消息中定义。 |
| Command A Reasoning | ✅ | ✅ | ✅ | ❌ | 同一模型提供多个 chat template。 |
| GPT-OSS | ✅ | ✅ | ✅ | ✅ | 基于 Harmony response format。复杂但灵活。 |
在大多数情况下,我们发现 ChatML 或 Qwen 的 chat template 都是很好的起点。对于 SmolLM3,我们需要一个支持混合推理的模板,而 Qwen3 是少数能在我们关心的多个维度上取得平衡的选择之一。不过它有一个我们不太满意的点:在多轮对话中,除最后一轮外,推理内容都会被 丢弃 。如下图所示,这与 OpenAI 推理模型的工作方式 类似:
flowchart LR
subgraph Turn1 ["Turn 1"]
T1_Input["**INPUT**"]
T1_Output["**OUTPUT**"]
end
subgraph Turn2 ["Turn 2"]
T2_Input["**INPUT**"]
T2_Output["**OUTPUT**"]
end
subgraph Turn3 ["Turn 3"]
T3_Input["**INPUT**"]
T3_Output1["**OUTPUT**"]
Reasoning["**REASONING**"]
T3_Output2_Top["**OUTPUT**"]
TruncatedOutput["**TRUNCATED OUTPUT**"]
end
T1_Input --> T2_Input
T1_Output --> T2_Input
T2_Input --> T3_Input
T2_Output --> T3_Input
T3_Input --> T3_Output1
T3_Output1 --> Reasoning
Reasoning --> T3_Output2_Top
T3_Output2_Top -->|CONTEXT WINDOW ✂️| TruncatedOutput
classDef input fill:#e8f5e8,stroke:#4caf50,stroke-width:2px
classDef output fill:#e3f2fd,stroke:#2196f3,stroke-width:2px
classDef reasoning fill:#f5f5f5,stroke:#999,stroke-width:1px
classDef truncated fill:#ffebee,stroke:#f44336,stroke-width:3px
classDef subgraphStyle fill:#f8f9fa,stroke:#dee2e6,stroke-width:1px
classDef linkLabel fill:#f8f9fa,stroke:#dee2e6,stroke-width:1px
class T1_Input,T2_Input,T3_Input input
class T1_Output,T2_Output,T3_Output1,T3_Output2_Top output
class Reasoning reasoning
class TruncatedOutput truncated
class Turn1,Turn2,Turn3 subgraphStyle
linkStyle 4 stroke:#333,stroke-width:2px,fill:#f8f9fa
这对 inference 来说是合理的(避免上下文被迅速占满),但我们认为对 training 而言,必须在所有轮次中 保留推理 tokens ,才能正确地对模型进行条件化。
因此,我们决定设计自己的 chat template,具备以下特性:
- 使用结构化 system prompt,风格类似 Llama 3 和一些从闭源模型逆向整理出的模板。同时我们也希望支持完全覆盖 system prompt。
- 支持 code agents,即执行任意 Python 代码,而不是只做 JSON 工具调用。
- 通过 system message 显式控制推理模式。
为了迭代 chat template 的设计,我们使用了 Chat Template Playground。这个实用工具由 Hugging Face 的同事开发,能方便地预览消息渲染结果并调试格式问题。下面是内嵌版本,你可以直接体验:
你可以在下拉菜单中切换不同示例,观察 chat template 在多轮对话、推理和工具调用场景下的行为。你还可以手动修改 JSON 输入来触发不同模式,例如设置 enable_thinking: false ,或在 system message 末尾追加 /no_think 。
当你确定了初始数据集和 chat template 后,就可以开始训练 baseline 了!
Baby baselines(起步基线)
在深入优化、榨取每一点性能之前,我们需要先建立一些“起步基线(baby baselines)”。这些基线的目标(暂时)不是冲击 SOTA,而是验证 chat template 是否按预期工作,以及初始超参数组合能否带来稳定训练。只有打好这层基础后,我们才开始大幅调参与调整训练数据混合。
在训练 SFT baseline 时,主要需要考虑以下几点:
- 你会使用全参数微调(FullFT),还是 LoRA、QLoRA 这类参数高效方法?正如 Thinking Machines 在这篇精彩的博客中所说,在某些条件下(通常由数据集大小决定),LoRA 可以达到与 FullFT 相当的效果。
- 你需要哪种并行策略?对于小模型或使用 LoRA 训练的模型,通常数据并行就够了。对于更大的模型,你需要 FSDP2 或 DeepSpeed ZeRO-3 来分摊模型权重和优化器状态。对于长上下文训练,可采用 context parallelism 等方法。
- 如果硬件支持,使用 FlashAttention 和 Liger 等 kernel。许多这类 kernel 托管在 Hugging Face Hub 上,并可通过 TRL 中一个简单参数启用,从而显著降低 VRAM 占用。
- 对 loss 做 mask,只在 assistant tokens 上训练。正如下文会讨论的,这可以通过在 chat template 的 assistant 轮次中包裹特殊的
{% generation %}关键字来实现。 - 调好学习率;除数据本身外,这是决定你的模型是“meh”还是“great”的最关键因素。
- 使用 packing 打包训练样本,并将序列长度调整到与数据分布匹配。这会显著提升训练速度。TRL 提供了一个实用工具来帮助你完成这件事。
我们来看看其中一些选择在 SmolLM3 上的实际表现。在第一轮 baseline 实验中,我们先做了一个简单的 sanity check:chat template 是否真的能诱导出混合推理能力?为此,我们比较了 table 中的三种数据混合:
- Instruct: 在非推理样本上训练。
- Thinking: 在推理样本上训练。
- Hybrid: 在全部样本上训练。
针对每种混合,我们都在 SmolLM3-3B-Base 上进行 SFT,采用 FullFT,学习率设为 1e-5,有效 batch size 为 128,并训练 1 个 epoch。
由于这些数据集规模较小,我们没有启用 packing:Instruct 子集的序列上限设为 8,192 tokens,其余子集设为 32,768 tokens。在 1 个包含 8 张 H100 的节点上,这些实验很快就能跑完,按子集不同耗时约 30-90 分钟。下图对比了各子集在对应推理模式下的性能:
这些结果很快表明,hybrid 模型会出现一种“split brain”现象:针对一种推理模式优化的数据混合,对另一种模式几乎没有影响。大多数评测中,Instruct、Thinking 与 Hybrid 子集得分相近;例外是 LiveCodeBench v4 和 IFEval,在这两项上 hybrid 数据能提升整体表现。
给 baseline 做一次“体感测试(vibe test)”
虽然评测结果看起来还不错,但当我们尝试让 hybrid 模型扮演不同人格(例如海盗)时,它始终会忽略我们放在 system message 里的内容。进一步排查后,我们发现原因出在数据格式化方式上:

具体来说,在 chat template 设计中,我们暴露了一个 custom_instructions 参数来存放 system prompts。比如,下面是我们在对话里设置 persona 的方式:
from transformers import AutoTokenizer
tok = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM3-3B")
messages = [
{
"content": "I'm trying to set up my iPhone, can you help?",
"role": "user",
},
{
"content": "Of course, even as a vampire, technology can be a bit of a challenge sometimes [TRUNCATED]",
"role": "assistant",
},
]
chat_template_kwargs = {
"custom_instructions": "You are a vampire technologist",
"enable_thinking": False,
}
rendered_input = tok.apply_chat_template(
messages, tokenize=False, **chat_template_kwargs
)
print(rendered_input)
## <|im_start|>system
### Metadata
## Knowledge Cutoff Date: June 2025
## Today Date: 28 October 2025
## Reasoning Mode: /no_think
### Custom Instructions
## You are a vampire technologist
## <|im_start|>user
## I'm trying to set up my iPhone, can you help?<|im_end|>
## <|im_start|>assistant
## <think>
## </think>
## Of course, even as a vampire, technology can be a bit of a challenge sometimes # [TRUNCATED]<|im_end|>
问题在于,我们的数据样本实际上是这样的:
{
"messages": [
{
"content": "I'm trying to set up my iPhone, can you help?",
"role": "user",
},
{
"content": "Of course, even as a vampire, technology can be a bit of a challenge sometimes [TRUNCATED]",
"role": "assistant",
},
],
"chat_template_kwargs": {
"custom_instructions": None,
"enable_thinking": False,
"python_tools": None,
"xml_tools": None,
},
}
我们的处理代码里有一个 bug,把 custom_instructions 设成了 None ,这等于把 每一条训练样本 的 system message 都移除了 🙈!结果这些训练样本不再使用预期的人设,而是回退到了 SmolLM3 的默认 system prompt:
chat_template_kwargs = {"custom_instructions": None, "enable_thinking": False}
rendered_input = tok.apply_chat_template(messages, tokenize=False, **chat_template_kwargs)
print(rendered_input)
## <|im_start|>system
#### Metadata
## Knowledge Cutoff Date: June 2025
## Today Date: 28 October 2025
## Reasoning Mode: /no_think
#### Custom Instructions
## You are a helpful AI assistant named SmolLM, trained by Hugging Face.
## <|im_start|>user
## I'm trying to set up my iPhone, can you help?<|im_end|>
## <|im_start|>assistant
## <think>
## </think>
## Of course, even as a vampire, technology can be a bit of a challenge sometimes [TRUNCATED]<|im_end|>
这对 SystemChats 子集尤其致命,因为其中所有 persona 都通过 custom_instructions 定义,因此模型会在对话中倾向于随机切换角色。这引出了下面这条准则:
即使评测看起来没问题,也一定要给模型做 vibe test。很多时候,你会因此发现训练数据中非常隐蔽的 bug。
修复这个 bug 后,评测结果并没有变化,但我们终于确认 chat template 和数据集格式都在正常工作。等你的配置稳定、数据管线也验证通过后,下一步就是聚焦于特定能力的构建。
定向构建特定能力
在开发 Open-R1 的过程中,我们注意到,如果只用单轮推理数据来训练一个 base model,它往往无法泛化到多轮场景。这其实并不令人意外;如果训练时完全没有这类样本,那么测试时模型就等于被放到了训练分布之外。
为了在 SmolLM3 上定量衡量这个问题,我们借鉴了 Qwen3 的做法。他们开发了一个内部评测 ThinkFollow ,会随机插入 /think 或 /no_think 标签,用来测试模型能否稳定切换推理模式。在我们的实现中,我们使用了 Multi-IF 的 prompts,然后检查模型生成的 <think> 和 </think> 标签之间的 think block 是空还是非空。正如预期,我们的 hybrid baseline 结果表明:模型在第一轮之后几乎完全无法继续启用推理模式:
为了修复这项能力,我们构建了一个名为 IFThink 的新数据集。基于 Multi-IF 的流程,我们取用了 Tulu 3 instruction-following 子集中的单轮指令,再使用 Qwen3-32B 将其扩展为多轮交互,同时生成可验证指令与推理轨迹。方法如下图所示:
flowchart TD
%% Inputs
IFEval["Tülu3 IF Dataset"]
InstructionTypes["指令类型集合"]
%% English Multi-Turn Generation
SingleTurn["单轮 prompt"]
LLM1["用 Qwen3-32B 生成指令"]
subgraph Turns ["多轮 prompts"]
Turn1["第 1 轮 prompt"]
Turn2["第 2 轮 prompt"]
Turn3["第 3 轮 prompt"]
end
MultiTurn["用 Qwen3-32B 生成推理轨迹"]
IFThink["IFThink"]
%% Connections
IFEval --> SingleTurn
IFEval --> InstructionTypes
SingleTurn --> Turn1
InstructionTypes --> LLM1
LLM1 --> Turn2
LLM1 --> Turn3
Turn1 --> MultiTurn
Turn2 --> MultiTurn
Turn3 --> MultiTurn
MultiTurn --> IFThink
%% Styling
classDef question fill:#ffd0c5
classDef decision fill:#f9f9f9
classDef success fill:#d1f2eb
classDef danger fill:#fef3c7
classDef category fill:#fef3c7
class IFEval,InstructionTypes question
class SingleTurn,LLM1,MultiTurn decision
class Turn1,Turn2,Turn3 decision
class IFThink success
把这份数据加入 baseline 数据混合后,效果得到了显著提升:
在用 IFThink 修复了多轮推理问题之后,我们的 baseline 终于按预期工作了;它能够在多轮对话中保持一致、遵循指令,并正确使用 chat template。在这个基础打稳之后,我们又回到了更基础的问题:调优训练设置本身。
哪些超参数真正重要?
在 SFT 中,真正重要的超参数其实并不多。学习率、批次大小和 packing,几乎决定了模型训练的效率以及它的泛化能力。在我们的 baby baselines 中,我们先选了一组合理的默认值,只为验证数据和 chat template 是否正常。现在既然整套流程已经稳定,我们就回过头来重新审视这些选择,看看它们究竟会对 baseline 造成多大影响。
遮蔽用户轮次
chat template 中一个很微妙的设计选择,是训练时是否要遮蔽用户轮次。在大多数聊天风格的数据集中,每个训练样本都由交替出现的 user 和 assistant 消息组成,其中也可能夹杂工具调用。如果我们让模型预测所有 token,它实际上学到的会更像是“自动补全用户问题”,而不是专注于生成高质量的 assistant 回复。
如下图所示,遮蔽用户轮次可以避免这个问题,因为这样模型的 loss 只会计算 assistant 的输出,而不会计算用户消息:
在 TRL 中,只要 chat template 能返回 assistant tokens mask,就可以启用 masking。实际做法是在模板里加入 {% generation %} 关键字,如下所示:
{%- for message in messages -%}
{%- if message.role == "user" -%}
{{ "<|im_start|>" + message.role + "\n" + message.content + "<|im_end|>\n" }}
{%- elif message.role == "assistant" -%}
{% generation %}
{{ "<|im_start|>assistant" + "\n" + message.content + "<|im_end|>\n" }}
{% endgeneration %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{ "<|im_start|>assistant\n" }}
{%- endif %}
随后,当 apply_chat_template() 搭配 return_assistant_tokens_mask=True 使用时,chat template 就会指出对话中哪些部分应该被遮蔽。下面是一个简单例子:assistant 的 token 会被标成 1,而 user 的 token 会被标成 0:
chat_template = '''
{%- for message in messages -%}
{%- if message.role == "user" -%}
{{ "<|im_start|>" + message.role + "\n" + message.content + "<|im_end|>\n" }}
{%- elif message.role == "assistant" %}
{% generation %}
{{ "<|im_start|>assistant" + "\n" + message.content + "<|im_end|>\n" }}
{% endgeneration %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{ "<|im_start|>assistant\n" }}
{%- endif %}
'''
rendered_input = tok.apply_chat_template(messages, chat_template=chat_template, return_assistant_tokens_mask=True, return_dict=True)
print(rendered_input)
## {'input_ids': [128011, 882, 198, 40, 2846, 4560, 311, 743, 709, 856, 12443, 11, 649, 499, 1520, 30, 128012, 198, 257, 128011, 78191, 198, 2173, 3388, 11, 1524, 439, 264, 51587, 11, 5557, 649, 387, 264, 2766, 315, 264, 8815, 7170, 510, 2434, 12921, 9182, 60, 128012, 271], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'assistant_masks': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
在实践中,masking 对下游 eval 的影响通常不算特别大,大多数情况下只是带来几个点的提升。对 SmolLM3 来说,我们发现它对 IFEval 的影响最明显,可能是因为模型不那么倾向于复述 prompt,并且能更严格地遵守各种约束。下图比较了用户轮次 masking 对各项评测以及不同推理模式的影响:
该不该做 packing?
Sequence packing 是那些会显著影响训练效率的细节之一。在 SFT 中,大多数数据集都由不同长度的样本构成,这意味着每个 batch 都会包含大量 padding token,既浪费算力,也会拖慢收敛。
Packing 通过把多条序列拼接在一起,直到达到目标最大 token 长度,来解决这个问题。具体的拼接方式有很多,TRL 采用的是一种 “best-fit decreasing” 策略 (Ding et al., 2024),也就是按照序列长度来决定打包顺序。如下图所示,这种策略既能尽量减少文档在 batch 边界处被截断,也能减少 padding token 的数量:
在预训练中,这几乎不是一个需要讨论的问题。面对数万亿 token 的训练规模,packing 是必须的,否则会在 padding 上浪费大量算力。Megatron-LM 和 Nanotron 这类预训练框架默认就实现了 packing。后训练则不同,由于运行时间更短,权衡关系也会随之变化。
为了更直观地感受 packing 对训练效率的影响,下面我们比较了在 baseline 数据集上跑一个 epoch 时,packing 和 no-packing 的运行时间:
根据 batch size 的不同,packing 能把吞吐提升到 3-5 倍!那么,你是否 总是 应该启用 packing 呢?在一定程度上,这取决于你的数据集有多大,因为 packing 会让每一步塞进更多 token,从而减少每个 epoch 的优化步数。你可以在下图中看到这一点,我们绘制了每个 batch 中非 padding token 的平均数量:
启用 packing 后,每个 batch 的 token 数会随着 batch size 线性增长;与不做 packing 的训练相比,每一步优化中纳入的 token 最多可以多出 33 倍!不过,packing 也会轻微改变训练动力学:虽然你整体处理了更多数据,但梯度更新次数变少了,这可能影响最终性能,尤其是在每个样本都更关键的小数据集上。举个例子,如果我们在相同的 effective batch size 128 下比较 packing 和 no-packing,会发现某些 eval,例如 IFEval,性能会显著下降,将近 10 个百分点:
更一般地看,对于这个特定模型和数据集,一旦 effective batch size 大于 32,平均性能就会开始下降:
在实践中,对于大规模 SFT,只要数据集足够大,packing 几乎总是有益的,因为节省下来的算力远远超过梯度更新频率变化带来的轻微差异。但对于更小或更多样化的数据集,例如特定领域微调,或基于有限人工整理数据做 instruction-tuning,关闭 packing 反而可能更合适,因为这样能保留样本粒度,确保每个样本都更干净地参与优化。
归根结底,最佳策略仍然是经验性的:先开启 packing,同时监控吞吐和下游 eval,再根据速度提升是否真正转化为同等甚至更好的模型质量来做调整。
调学习率
现在来到最后一个但仍然很重要的超参数:学习率。设得太高,训练可能会发散;设得太低,收敛速度又会慢得令人难受。
在 SFT 中,最优学习率通常会比预训练时使用的值小一个数量级,甚至更多。这是因为我们是从一个已经具备丰富表征能力的模型出发,过于激进的更新很容易导致灾难性遗忘。
不同于预训练,在预训练里对完整训练过程做超参数扫描通常贵得难以承受;而后训练运行时间足够短,我们实际上可以对学习率做完整的 sweep。
在我们的实验中,“最佳”学习率会随着模型家族、模型规模以及是否启用 packing 而变化。由于过高的学习率可能导致梯度爆炸,我们发现当启用 packing 时,略微降低学习率通常会更安全。你可以在下图中看到,像 3e-6 或 1e-5 这样较小的学习率,整体表现优于更大的数值:
虽然平均来看只差几个点似乎不算多,但如果你看 AIME25 这类单项 benchmark,就会发现当学习率高于 1e-5 时,性能会出现明显下滑。
增加训练轮数
在我们的消融实验里,通常只训练一个 epoch,以便快速迭代。一旦你确定了不错的数据混合,并调好了学习率等关键参数,下一步通常就是在最终训练时增加 epoch 数。
例如,如果我们使用 baseline 数据混合训练 5 个 epoch,就能看到平均性能还可以再挤出几个百分点:
正如我们在学习率扫描中看到的那样,平均性能会掩盖增加 epoch 数对单项 eval 的影响。以带 extended thinking 的 LiveCodeBench v4 为例,我们相较于 1 个 epoch 几乎把性能翻倍了!
当你对 SFT 数据混合做过几轮迭代,并让模型达到一个还不错的性能水平后,下一步通常就是探索更高级的方法,比如[偏好优化](#from-sft-to-preference-optimisation:-teaching-models-what- better- means)或强化学习。不过,在真正投入这些方法之前,也值得先想一想:额外的算力是否更应该花在通过 continued pretraining 来增强 base model 上。
我们在预训练部分提到过另一个重要组件:优化器。同样,AdamW 仍然是后训练中的默认选择。一个尚未完全定论的问题是:如果模型在预训练阶段使用了 Muon 这类替代优化器,那么后训练阶段是否也应该继续使用 同一种 优化器。Kimi 团队发现,对他们的 Moonlight 模型来说,预训练和后训练使用同一个优化器能得到最佳表现。
通过持续预训练增强推理能力
持续预训练(continued pretraining),如果你想说得更时髦一点,也可以叫 mid-training,指的是在做 SFT 之前,先拿一个 base model 用大量特定领域的 token 继续训练。当前者与 SFT 的目标能力共享某种核心技能时,例如代码或推理,mid-training 就会特别有用。在实践中,这会把模型推向一个更有利于推理、特定语言能力,或任何你关心能力的数据分布上。这样一来,当你从一个已经吸收了这项核心技能的模型出发做 SFT 时,模型就能把更多注意力放在 SFT 数据中的具体主题上,而不是把算力花在从零学习这项核心技能上。
mid-training 这一路线可以追溯到 ULMFit (Howard & Ruder, 2018)。它提出了“通用预训练 → mid-training → 后训练”的三阶段流程,如今这已经成为现代 LLM 的常见范式,例如 FAIR 的 Code World Model (team et al., 2025):
Phi-4-Mini-Reasoning 的训练也采用了这种方法 (Xu et al., 2025),但做了一点变化:作者并不是在网页数据上做持续预训练,而是使用从 DeepSeek-R1 蒸馏出来的推理 token 作为 mid-training 语料。结果很有说服力,显示出多阶段训练能够带来稳定而显著的收益:
| Model | AIME24 | MATH-500 | GPQA Diamond |
|---|---|---|---|
| Phi-4-Mini | 10.0 | 71.8 | 36.9 |
| + Distill Mid-training | 30.0 | 82.9 | 42.6 |
| + Distill Fine-tuning | 43.3 | 89.3 | 48.3 |
| + Roll-Out DPO | 50.0 | 93.6 | 49.0 |
| + RL (Phi-4-Mini-Reasoning) | 57.5 | 94.6 | 52.0 |
这些结果促使我们尝试类似的方法。结合我们此前在 Open-R1 中构建和评估推理数据集的经验,我们主要考虑了三个候选数据集:
- Mixture of Thoughts : 35 万条从 DeepSeek-R1 蒸馏得到的推理样本,覆盖数学、代码和科学。
- Llama-Nemotron-Post-Training-Dataset: NVIDIA 的大规模蒸馏数据集,来源涵盖 Llama3、DeepSeek-R1 等多种模型。我们从中筛选出 DeepSeek-R1 的输出,得到约 364 万个样本,也就是 18.7B tokens。
- OpenThoughts3-1.2M: 质量最高的推理数据集之一,包含 120 万条从 QwQ-32B 蒸馏得到的样本,共 16.5B tokens。
由于我们计划在最终的 SFT 数据混合中加入推理数据,因此我们决定把 Mixture of Thoughts 留到那个阶段使用,而另外两个数据集则用于 mid-training。我们采用 ChatML 作为 chat template,避免过早把 SmolLM3 自己的模板“烧录”进去。训练时我们使用 8 个节点,将有效 batch size 提升到 128,并以 2e-5 的学习率训练 5 个 epochs。
你可能会疑惑,为什么我们会在做过一些 SFT 运行之后才来讨论 mid-training。按时间顺序来说,mid-training 的确发生在 base model 做 SFT 之前。但是否需要做 mid-training,通常只有在你先跑过初始的 SFT 实验、识别出性能短板之后,才会变得清晰。在实践中,你往往会这样迭代:先跑 SFT 找出薄弱点,再做有针对性的 mid-training,然后重新跑一轮 SFT。把这一节理解为“当仅靠 SFT 不够时该怎么办”会更合适。
GPU 融化之谜
在我们的集群上跑这些实验,结果成了一场出乎意料的挑战:那批逐渐老化的 GPU 会在不同阶段触发降频,进而导致硬件故障,并迫使每次运行重新启动。为了让你直观感受一下当时的情况,下面是一段某次运行的日志,其中每种颜色都代表一次重启:
一开始我们以为罪魁祸首可能是 DeepSpeed,毕竟这个加速器对吞吐做了大量优化。为了验证这一点,我们切换到了 DP。情况确实稍有改善,但 loss 却出现了明显不同。
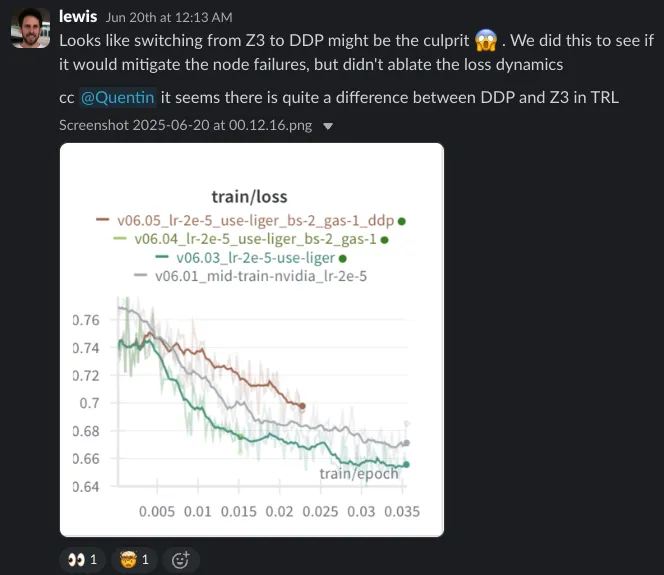
后来我们发现,Accelerate 里的 DP 存在一个 bug,导致权重和梯度都以模型的原生精度存储(这里是 BF16),这会在梯度累积和优化过程中引发数值不稳定,并损失梯度精度。
于是我们又切回 DeepSpeed,并加入更激进的 checkpoint 保存策略,以尽量减少 GPU 过热和 “falling off the bus” 带来的时间损失。这个策略最终证明是有效的,而且我们也更普遍地推荐这样做:
正如我们在预训练部分强调过的那样,在训练过程中要频繁保存模型 checkpoint,最好还能推送到 Hugging Face Hub,以避免被意外覆盖。同时,你的训练框架也应该能够稳健地应对故障,并支持自动重启。这两种策略都能帮你节省大量时间,尤其是在 mid-training 这种长时间运行的任务里。
在盯着这些运行状态“带娃”一周左右之后,我们终于拿到了结果:
总体来看,我们发现 NVIDIA 的 post-training 数据集表现优于 OpenThoughts,但两者组合起来的效果最好。
接下来我们再看看,如果从这些 checkpoint 中拿一个出来,并套用同样的 baseline 数据混合,会产生什么效果:
使用经过 mid-training 的推理模型来替代原始预训练模型,带来的效果非常惊人:在 extended thinking 模式下,AIME25 和 LiveCodeBench v4 的表现几乎提升到原来的三倍,而 GPQA-D 也整整提高了 10 分。更让人意外的是,这种推理能力也部分迁移到了 /no_think 推理模式,在这些推理基准上依然带来了约 4 到 6 分的提升。这些结果清楚地表明:对于推理模型来说,如果你的 base model 在预训练阶段还没有见过足够多的推理数据,那么做一定程度的 mid-training 几乎总是值得的。
当模型必须学习一项新的核心技能时,mid-training 最能发挥作用。如果 base model 已经具备这项技能,或者你只是想激发一些较浅层的能力,例如文风或闲聊对话,那么它的价值就没有那么大。在这些情况下,我们建议跳过 mid-training,把算力投入到偏好优化或强化学习等其他方法上。
当你已经对自己的 SFT 数据混合和模型的整体能力有了足够信心,关注点就会自然从“学习技能”转向“打磨技能”。在大多数情况下,接下来最有效的路线就是 偏好优化(preference optimisation)。
从 SFT 到偏好优化:教会模型什么才算 更好
尽管你可以继续通过增加数据规模来扩展 SFT,但到某个阶段,你会发现收益开始递减,或者出现一些失败模式,比如模型无法修复自己写出的有 Bug 的代码。为什么会这样?因为 SFT 本质上是一种 模仿学习(imitation learning),模型学到的只是复现训练数据中的模式。如果数据本身并没有包含高质量的修复方案,或者目标行为很难通过蒸馏诱导出来,那么模型就得不到关于什么才算“更好”的明确信号。
这正是偏好优化发挥作用的地方。我们不再只是让模型照搬示范,而是给它提供比较式反馈,例如“回答 A 比回答 B 更好”。这些偏好为“质量”提供了更直接的训练信号,使模型性能能够突破仅靠 SFT 所能达到的上限。
偏好优化的另一个好处是,它通常所需的数据远少于 SFT,因为此时的起点已经是一个相当不错的模型了,它既能遵循指令,也具备前几个训练阶段积累的知识。
下面我们来看这些数据集是如何构建出来的。
偏好数据集的构建
历史上,偏好数据集通常通过向人工标注者提供成对的模型回复,并让他们判断哪一个更好来构建,有时还会要求按等级打分。这种方法至今仍被不少 LLM 提供方用于收集 人类偏好 标签,但成本极高,而且很难扩展。近来,LLM 已经能够生成高质量回复,而且往往具备不错的成本效益。这些进展使得让 LLM 为许多应用场景 生成 偏好成为现实。实践中,常见的方法主要有两类:
强模型 vs. 弱模型
- 选取一组固定的提示词 ,通常会为覆盖面和难度做专门筛选。
- 分别让一个较弱的模型或 baseline 模型,以及一个性能更强的模型,各生成一条回复。
- 将强模型的输出标记为被选中的回复 ,将弱模型的输出标记为被拒绝的回复 。
这样就能得到一个“强于弱”比较数据集 ,其构建方式相对简单,因为我们默认强模型的输出会更可靠地优于弱模型。
下面是 Intel 的一个经典示例:他们从一个包含 gpt-3.5 与 gpt-4 回复的 SFT 数据集中出发,将 gpt-4 的回复选作 chosen、gpt-3.5 的回复选作 rejected,从而将其转换为偏好数据集:
On-policy + 打分器
- 使用你即将训练的 同一个模型 ,针对同一条提示词生成多条候选回复。由于这些数据反映的是该模型自然会产出的回复分布,因此它们属于“on-policy”数据。
- 不再依赖更强的模型作为参考答案,而是引入一个 外部打分器 :它可以是 verifier,也可以是 reward model,用来沿着一个或多个质量维度(例如 helpfulness 或 factual accuracy)为回复打分。
- 随后由打分器在这些候选回复之间赋予偏好标签,从而产出更细致、也更灵活的偏好数据集。
这种方法允许随着模型能力提升,持续自举出新的偏好数据;但它的效果高度依赖评估器本身的可靠性以及校准质量。
SnorkelAI 就提供了一个很好的例子:他们取用了一个流行偏好数据集 UltraFeedback 中的提示词,将其划分为 3 个子集,然后迭代应用上述流程来不断改进模型:
在开发 SmolLM3 时,市面上还没有带有 reasoning trace 的偏好数据,因此我们决定采用“强模型 vs. 弱模型”的方法自行生成一部分数据。我们使用 Ai2 的 Tulu 3 preference mixture 中的提示词,在 /think 模式下分别让 Qwen3-0.6B 和 Qwen3-32B 生成回复。最终得到的是一个超过 25 万条、由 LLM 生成偏好的大规模数据集,可用于配合偏好优化算法,从多个维度同时提升我们的 SFT checkpoint。
选择哪种算法?
Direct Preference Optimization(DPO)(Rafailov et al., 2024) 是第一个在开源社区获得广泛采用的偏好优化算法。
DPO 之所以受到欢迎,是因为它实现简单、实践中稳定,而且即使只有适量的偏好数据也能取得良好效果。因此,在尝试 RL 等更复杂技术之前,DPO 已经成为改进 SFT 模型的默认方法。
但研究人员很快发现,DPO 还有许多可以改进的方向,如今也已经出现了大量可供探索的替代方案。下面列出的是我们认为最有效的几种:
- Kahneman-Tversky Optimisation(KTO)[ Ethayarajh et al. (2024) ]: KTO 不依赖偏好对,而是借鉴人类决策理论,去建模单条回复是否“值得偏好”。如果你拿不到成对的偏好数据,这会是一个不错的选择,例如你手里只有来自终端用户的原始反馈,像 👍 或 👎 这样的标记。
- Odds Ratio Preference Optimisation(ORPO)[ Hong et al. (2024) ]: ORPO 通过在交叉熵损失中加入 odds ratio,将偏好优化直接整合进 SFT。因此它不再需要 reference model,也不需要单独的 SFT 阶段,这使得它在计算上更高效。
- Anchored Preference Optimisation(APO)[ D’Oosterlinck et al. (2024) ]: 这是一个更可控的目标函数,它会显式正则化模型对 chosen 与 rejected 输出的概率应当偏移多少,而不是只优化二者之间的差值。它有两个变体(APO-zero 和 APO-down),具体该选哪一个,取决于你的模型与偏好数据之间的关系,也就是 chosen 输出究竟比当前模型更好,还是更差。
幸运的是,这些方法在 TRL 的 DPOTrainer 中很多都只需要改一行代码。因此,在最初的 baseline 实验里,我们做了下面几件事:
- 使用 Ai2 的 Tülu3 Preference Personas IF dataset 中的 prompts 和 completions,在
/no_think推理模式下衡量模型在 IFEval 上的指令跟随能力提升。 - 复用上面的 prompts,但改为用 Qwen3-32B 和 Qwen3-0.6B 生成“强模型 vs. 弱模型”的偏好对。这样我们就得到了适用于
/think推理模式的偏好数据。 - 训练 1 个 epoch,并测量模型在 IFEval 上的 in-domain 提升,同时观察它对其他评测的 out-of-domain 影响,例如与指令跟随能力直接相关的 AIME25。
如下图所示,两种推理模式在领域内评测上的提升都非常明显:在 IFEval 上,APO-zero 相比 SFT checkpoint 提高了 15 到 20 个百分点!
由于 APO-zero 在整体的 out-of-domain 表现上也最好,我们最终决定在后续所有消融实验中都使用它。
正如上面的结果所示,偏好优化不仅能让模型更有帮助性、更对齐,它还能教会模型 更好地推理。如果你想快速提升推理模型,不妨尝试构造 strong-vs-weak 偏好数据,并对不同损失函数做消融实验;你很可能会看到相较于 vanilla DPO 的显著收益。
哪些超参数对偏好优化最重要?
对于偏好优化来说,通常只有三个超参数会明显影响训练动态:
- 学习率,通常应比 SFT 使用的学习率小 10 到 100 倍。
- β 参数,通常用于控制偏好对之间的间隔大小。
- batch size。
下面我们以在完整 smoltalk2 上训练得到的 SFT checkpoint 为起点,看看这些因素在 SmolLM3 上分别带来了什么影响。
使用较小的学习率以获得最佳性能
我们做的第一个消融实验,是检查学习率对模型性能的影响。我们测试的学习率范围,从比 SFT 学习率(2e-5)小约 200 倍(1e-7),到小约 2 倍(1e-5)。此前像 Zephyr 7B 这样的项目已经告诉我们,对于偏好优化方法,最佳学习率通常比 SFT 所用学习率小约 10 倍;而我们在 SmolLM3 上做的消融实验,也验证了这条经验法则。
如下图所示,当学习率缩小约 10 倍时,SFT 模型在两种推理模式下的性能都会提升;但一旦超过这个 10 倍阈值,在 extended thinking 模式下,性能就会变差:
对于 /no_think 推理模式,这一趋势更稳定,其中最优学习率是 5e-6。不过,这主要是由单一基准(LiveCodeBench v4)驱动的,因此我们在 SmolLM3 的实际训练中选择了 1e-6。
我们对你的训练建议是:将学习率扫描范围设置为比 SFT 学习率小 5 倍到 20 倍。在这个区间里,你极有可能找到最优性能点。
调节你的 β
我们对 ß 参数做的实验,取值范围是 0.01 到 0.99,以探索不同程度“向 reference model 对齐”的效果。回顾一下,较小的 beta 值会鼓励模型更贴近 reference model,而较大的值则允许模型更紧密地贴合偏好数据。实验结果显示,β=0.1 时,模型在两种推理模式下的表现都是最好的,并且相较于 SFT checkpoint 的指标都有提升。相反,beta 值太低会损害模型性能,使模型甚至比 SFT checkpoint 更差;而在不使用 extended thinking 的情况下,跨多个 ß 取值,性能则基本保持稳定。
这些结果表明,对于偏好优化来说,大于 0.1 的取值更值得优先考虑;同时,与其尽量贴近 reference model,不如更好地向偏好数据对齐,收益更大。不过,我们仍建议把 ß 的探索范围设在 0.01 到 0.5 之间。更高的取值可能会抹掉 SFT checkpoint 中的一些能力,而这些能力未必能在图中展示的评测里被捕捉到。
扩大偏好数据规模
我们还做了实验来观察数据集大小如何影响结果,测试范围从 2k 到 340k 个偏好对。在这个区间内,整体性能基本保持稳定。当数据集超过 100k 个偏好对时,extended thinking 模式下会出现性能下降,但下降幅度没有学习率变化时那么明显。我们在 SmolLM3 正式训练中使用的数据集规模是 169k 个偏好对,但结果表明,更小的数据集同样能带来相较于 SFT checkpoint 的提升。对于未来项目,这意味着我们可以在迭代阶段先用更小的数据集做实验,因为尝试更多想法、快速识别最有前景的配置非常重要。
把这些结论整合起来
把这些线索综合起来之后,我们得到了最终的 SmolLM3-3B 模型:在同尺寸模型中属于最优,并且与 Qwen 自家的 hybrid reasoning 模型一起位于 Pareto front 上。
对于几周时间做出来的成果来说,这已经相当不错了。
实战原则
下面总结一下我们关于偏好优化的发现,这些结论可能会对你未来的项目有帮助:
- 不要害怕自己构造偏好数据!随着推理成本变得“低到几乎可以忽略不计”,现在通过各种 inference providers 生成 LLM 偏好数据,已经变得既简单又划算。
- 把 DPO 作为初始 baseline,然后从那里开始迭代。我们的经验是,具体哪种算法最好,取决于偏好数据的类型;像 ORPO、KTO 或 APO 这样的算法,往往能相较于 DPO 带来显著收益。
- 使用比 SFT 小约 10 倍的学习率。
- 对 β 做扫描,通常探索范围设在 0.01 到 0.5。
- 大多数偏好算法训练 1 个 epoch 后就会过拟合,因此最好对数据做分块,并以迭代方式训练,以获得最佳效果。
偏好优化通常是在“简单性”和“性能”之间的最佳平衡点,但它仍然继承了一个关键限制:它的效果上限,取决于你能收集到的离线偏好数据质量。静态数据集终究会耗尽有效信号;到了某个阶段,你就需要能够在模型与 prompt 和环境交互时,在线生成新训练反馈的方法。也正是在这里,偏好优化开始与更广义的 on-policy 和基于 RL 的方法 汇合。
走向 on-policy,并超越监督标签
如果你希望模型能够稳定地解数学题、生成可执行代码,或者完成多步规划,那么你通常需要的就不只是“答案 A 比答案 B 更好”这种信号,而是一个 reward signal。
这正是 RL 开始发挥作用的地方。你不再只是用偏好来监督模型,而是让它与环境交互(这个环境可以是数学验证器、代码执行器,甚至是真实用户反馈),并直接从结果中学习。RL 在以下情形中特别适合:
- 你能够自动检查正确性, 例如通过单元测试、数学证明、API 调用,或者你有高质量的 verifier 或 reward model。
- 任务需要多步推理或规划,这时局部偏好未必能反映长期成功。
- 你想优化的不只是偏好标签所表达的目标,例如让代码通过单元测试,或最大化某种具体目标。
在 LLM 场景中,RL 主要有两种形式:
- Reinforcement Learning from Human Feedback(RLHF): 这是由 OpenAI 的 InstructGPT 论文 (Ouyang et al., 2022) 推广开来的方法,也是 gpt-3.5 和许多现代 LLM 的基础。在这种方法中,由人工标注者比较模型输出(例如“答案 A 比答案 B 更好”),再训练一个 reward model 去预测这些偏好。随后,用 RL 微调 policy,使其最大化学到的 reward。
- Reinforcement Learning with Verifiable Rewards(RLVR): 这是由 DeepSeek-R1 推广开来的方法,它依赖 verifier 去检查模型输出是否满足某些明确定义的正确性标准(例如代码能否编译并通过全部测试,或者数学答案是否正确)。然后再用 RL 微调 policy,以产生更多可验证为正确的输出。
RLHF 和 RLVR 都定义了模型究竟在为 什么 目标优化,但它们并没有告诉我们这种优化应当 如何 执行。实际上,基于 RL 的训练在效率和稳定性上的表现,很大程度取决于所用学习算法是 on-policy 还是 off-policy。
像 GRPO 这样的方法,通常属于 on-policy 优化算法:生成 completions 的模型(也就是 policy)与正在被优化的模型是同一个。虽然从整体上看 GRPO 确实是 on-policy 算法,但其中还是有一些细节需要注意。首先,为了优化生成步骤,训练中可能会先采样若干个 batch 的生成结果,然后对模型执行 次更新;其中第一个 batch 是 on-policy 的,而后续几个 batch 则会轻微偏离 on-policy。
为了处理“用于生成的模型”和“当前正在优化的模型”之间的 policy lag,通常会使用 importance sampling 和 clipping,来对 token 概率重新加权,并限制更新步长的大小。
由于 LLM 的自回归生成速度较慢,许多框架,例如 verl 和 PipelineRL,都加入了异步 completion 生成和模型权重的 “in-flight” 更新,以最大化训练吞吐。这些方法实现起来更复杂,也更需要谨慎设计,但训练速度可以达到同步训练方法的 4 到 5 倍。后文我们会看到,对于 token 分布呈长尾特征的推理模型,这类训练效率提升尤其明显。
对于 SmolLM3,我们当时完全跳过了 RL,主要原因是时间有限,而且依靠离线偏好优化,我们已经得到一个在同尺寸中表现最优的模型。不过在发布之后,我们重新回到了这个话题,并将在后训练章节的最后,分享一些将 RLVR 应用于 hybrid reasoning 模型时得到的经验。
将 RLVR 应用于 hybrid reasoning 模型
Hybrid reasoning 模型会给 RLVR 带来额外复杂度,因为生成长度会随着推理模式不同而显著变化。例如,在下图中,我们展示了 SmolLM3 的 final APO checkpoint 在 AIME25 上的 token 长度分布:
可以看到,/no_think 模式生成解答的中位长度约为 2k tokens,而 /think 模式则大得多,中位长度达到 16k tokens,并且呈现明显的 fat-tailed distribution。理想情况下,我们希望用 RLVR 同时提升这两种模式的整体性能,同时又不要过于剧烈地改变它们各自的长度分布。
为了研究这一点,我们先专注于优化 /no_think 模式,并从 Big-Math 中抽取了一部分 prompt。这个数据集包含超过 25 万道带有已验证答案的数学题。
令人意外的是,直接、朴素地应用 GRPO 会导致一种 reward hacking:尽管我们从未提示模型输出长 CoT,它还是学会了利用自身已有的推理能力来提高 reward。如下图所示,不仅 reward 上升了,completion 的长度也一并暴涨:
换句话说,带有 GRPO 的 RLVR 把我们推理模型中的 /no_think 模式,训练成了一个看起来非常像 /think 模式的东西!
当我们检查模型生成的 completions 时,会发现模型现在会输出很长的 CoT,甚至还会包含一些与推理模型相关的认知行为 (Gandhi et al., 2025),比如 “Wait, …”。下面就是一个例子:
However, since the jogger and the train are moving in the same direction, the relative speed between them is the difference of their speeds:
\\( v_{\\text{rel}} = v_t - v_j = 12.7778 - 2.7778 = 10 \\) m/s
**Wait,** let me double-check the calculation:
**Wait,** 46 km/hr to m/s:
46 * 1000 m / 3600 s = (46 * 10)/36 = 460/36 ≈ 12.7778 m/s (correct)
10 km/hr is:
10 * 1000 / 3600 = 10000 / 3600 ≈ 2.7778 m/s (correct)
Difference: 12.7778 - 2.7778 = 10 m/s (exact, since 46-10=36 km/hr → 36*(1000/3600)=10 m/s exactly)
The jogger is 340 meters ahead of the train's engine. When the train passes the jogger, the distance the train needs to cover relative to the jogger is 340 meters plus the length of the train? Wait, actually, let me think about the problem again.
**Wait,** actually, when the problem says the train takes 46 seconds to pass the jogger, that usually means the time from the front of the train to the end passing the jogger. The length of the train would then be equal to the relative speed multiplied by the time.
But first, the initial position: the jogger is 340 meters ahead of the engine. So the engine is 340 meters ahead of the jogger. Wait no, the wording says "340 m ahead of the engine", so the jogger is ahead by 340 meters. So when the jogger is running alongside, the engine of the train is 340 m away behind the jogger? Wait, maybe I need to clarify.
**Wait** the problem says: "A jogger running at 10 km/hr alongside a railway track is 340 m ahead of the engine of a train running at 46 km/hr in the same direction. The train takes 46 seconds to pass the jogger. How long is the train in meters?"
Hmm, so the jogger is 340 m ahead of the engine along the track. Since they're moving in the same direction, the train is behind the jogger by 340 meters. To pass the jogger, the train has to cover that 340 meters plus the length of the train itself?
用超长惩罚缓解 reward hacking
这个问题可以通过加入 overlong completion penalty 来缓解,也就是对超过某个长度阈值的 completion 施加惩罚。这个惩罚由两个参数控制:最大 completion 长度 和 soft punishment cache 。这一惩罚项是 DAPO 论文 (Yu et al., 2025) 提出的改进之一,对应的 reward function 如下:
通过这个惩罚项,我们就可以直接控制模型的输出分布,并衡量“回复长度增加”与“性能提升”之间的权衡。下图给出了一个例子:我们将 overlong penalty 从 1.5k 调到 4k,每次步进 512 tokens:
当我们观察 AIME25 上的性能提升时,这种“回复长度与性能之间的权衡”会变得更加清晰:
现在我们可以清楚地看到 overlong penalty 如何影响下游性能:当惩罚范围设在 2k 到 4k 时,模型能够获得显著提升,同时 token 分布仍然保持可控。如下图所示,如果取 step 400 时的 checkpoints,就可以比较不同惩罚设置下,初始 policy 与最终模型之间的输出 token 分布差异:
把这些结果整合起来
我们发现,把长度惩罚设在 2.5k 到 3k 的范围内,可以在性能和回复长度之间取得最佳平衡。下图显示,相比 APO 这样的离线方法,GRPO 在 AIME 2025 上几乎把性能翻了一倍:
现在我们已经知道如何提升 /no_think 推理模式下的性能,那么 RL 训练流水线的下一步,本应是同时对两种推理模式进行 joint training。但我们发现,这件事相当难啃,因为每种模式都需要各自独立的长度惩罚,而两者之间的相互作用到目前为止都会导致训练不稳定。这也凸显了将 RL 应用于 hybrid reasoning 模型时的核心挑战。我们也能从一个新趋势中看到这一点:像 Qwen 这样的模型开发者,开始分别发布 instruct 和 reasoning 两种变体。
我们的实验表明,RLVR 的确能够有效引导推理行为,但前提是必须精心设计 reward shaping 和稳定性机制。考虑到这种复杂度,一个自然的问题是:强化学习真的是唯一可行的前进方向吗?事实上,最近的文献中已经提出了几种更轻量级的 on-policy 优化策略,但在开源社区里却仍然没有得到充分探索。下面就用它们来结束这一章。
RL 是唯一的选择吗?
其他 on-policy 学习方法,会把偏好优化和蒸馏扩展为一个迭代循环,让训练信号随着模型演化而不断刷新:
- Online DPO: 不再是在一个固定的偏好数据集上训练一次,而是让模型持续采样新的回复、收集新的偏好标签(来自 reward models 或 LLM graders),再不断更新自身。这使优化过程保持 on-policy,并减少训练数据与模型当前行为之间的漂移 (Guo et al., 2024)。
- On-policy distillation: 信号不再来自偏好,而是来自一个更强的 teacher model。student 在每一个训练 step 上采样回复,而 student 与 teacher 在这些样本上的 logits 之间的 KL divergence 就构成学习信号。这样一来,student 就能持续吸收 teacher 的能力,而不需要显式的偏好标签或 verifier (Agarwal et al., 2024)。
这些方法模糊了静态偏好优化与完整 RL 之间的边界:你仍然可以获得“适应模型当前分布”的好处,但不需要承担设计并稳定整个强化学习循环的全部复杂性。
我该选哪种方法?
虽然关于哪种 on-policy 方法“最好”的研究论文已经多到数不过来,但在实践里,决策通常取决于下表所示的几个因素:
| Algorithm | When to Use | Tradeoffs | Best for Model Size |
|---|---|---|---|
| Online DPO | 当你可以低成本获得偏好标签时使用。最适合让行为对齐不断演化的分布。 | 易于做迭代扩展,比 RL 更稳定,但依赖标签质量和覆盖范围。支持它的训练框架较少。 | 适用于任意尺寸,只要偏好信号能捕捉到超越模仿学习的提升。 |
| On-policy distillation | 当你能访问更强的 teacher model,并希望高效转移能力时使用。 | 实现简单、运行便宜,但会继承 teacher 的偏差,能力上限也受 teacher 限制。当前只有 TRL 和 NemoRL 支持。 | 对小到中等规模模型最有效(<30B)。 |
| Reinforcement learning | 当你有可验证奖励,或任务需要多步推理/规划时最适合。也可以配合 reward model 使用,但会面临 reward-hacking 等问题,即模型会利用 reward model 的弱点。 | 灵活且强大,但成本更高,也更难稳定;需要精细的 reward shaping。大多数后训练框架都支持。 | 更适合中到大规模模型(20B+),因为额外容量能帮助模型利用结构化 reward signal。 |
在开源生态中,像 GRPO 和 REINFORCE 这样的强化学习方法通常是使用最广泛的。不过,Qwen3 技术报告 (A. Yang, Li, et al., 2025) 特别强调了:对于 32B 参数以下的模型,他们采用的是 on-policy distillation:
flowchart LR
subgraph Flagship ["Flagship Models"]
Base1["Base Models"] --> Stage1["Stage 1:
Long-CoT Cold Start"]
Stage1 --> Stage2["Stage 2:
Reasoning RL"]
Stage2 --> Stage3["Stage 3:
Thinking Mode Fusion"]
Stage3 --> Stage4["Stage 4:
General RL"]
Stage4 --> FlagshipOut["Qwen3-235B-A22B
Qwen3-32B"]
end
subgraph Lightweight ["Lightweight Models"]
Base2["Base Models"] --> Distillation["Strong-to-Weak
Distillation"]
FlagshipOut --> Distillation
Distillation --> LightweightOut["Qwen3-30B-A3B
14B/8B/4B/1.7B/0.6B"]
end
classDef flagshipStage fill:#ffd0c5
classDef lightweightStage fill:#fef3c7
classDef output fill:#f8d7da
class Stage1,Stage2,Stage3,Stage4 flagshipStage
class Distillation lightweightStage
class FlagshipOut,LightweightOut output on-policy distillation 在小模型上的一个有趣特性是:它通常能以远低于 RL 方法的计算成本,取得更好的效果。原因在于,它不需要为每个 prompt 生成多个 rollout,我们只采样一次,然后由 teacher 在一次前向-反向传播中完成评估。正如 Qwen3 技术报告所展示的,相比 GRPO,这种收益可能非常显著:
| Method | AIME’24 | AIME’25 | MATH500 | LiveCodeBench v5 | MMLU -Redux | GPQA -Diamond | GPU Hours |
|---|---|---|---|---|---|---|---|
| Off-policy Distillation | 55.0 | 42.8 | 92.4 | 42.0 | 86.4 | 55.6 | - |
| + Reinforcement Learning | 67.6 | 55.5 | 94.8 | 52.9 | 86.9 | 61.3 | 17,920 |
| + On-policy Distillation | 74.4 | 65.5 | 97.0 | 60.3 | 88.3 | 63.3 | 1,800 |
最近,Thinking Machines 还表明,on-policy distillation 对缓解 catastrophic forgetting 也很有效。所谓 catastrophic forgetting,是指一个后训练模型在新领域上继续训练后,先前的性能反而退化。在下表中,他们展示了这样一个现象:Qwen3-8b 的 chat 性能(IFEval)虽然会在内部数据上微调后明显下滑,但可以通过低成本蒸馏把这种行为恢复回来:
我们自己也对 on-policy distillation 非常兴奋,因为现在已经有大量能力很强的 open-weight LLM,可以被蒸馏成更小、更面向特定任务的模型。不过,所有 on-policy distillation 方法都有一个弱点:teacher 和 student 必须共享同一个 tokenizer。为了解决这个问题,我们开发了一种新方法,叫做 General On-Policy Logit Distillation(GOLD),它允许任意 teacher 被蒸馏到任意 student 中。如果你对这些话题感兴趣,我们建议阅读我们的 technical write-up。
类似地,FAIR 的研究者比较了 DPO 在 fully off-policy 与 on-policy 两种设定下的效果,并表明:用远少于 GRPO 的计算量,也有可能匹配 GRPO 的性能 (Lanchantin et al., 2025):
正如他们论文所示,online DPO 在数学任务上表现良好;即便是 semi-on-policy 变体,虽然已经偏离 on-policy 很多个 step,依然能取得可比的性能:
| Training method | Math500 | NuminaMath | AMC23 |
|---|---|---|---|
| Seed (Llama-3.1-8B-Instruct) | 47.4 | 33.9 | 23.7 |
| Offline DPO (s = ∞) | 53.7 | 36.4 | 28.8 |
| Semi-online DPO (s = 100) | 58.9 | 39.3 | 35.1 |
| Semi-online DPO (s = 10) | 57.2 | 39.4 | 31.4 |
| Online DPO (s = 1) | 58.7 | 39.6 | 32.9 |
| GRPO | 58.1 | 38.8 | 33.6 |
总体来看,我们认为,无论是在有效扩展 RL 方面 (Khatri et al., 2025),还是在探索其他计算效率更高的方法方面,都还有大量工作可以做。的确是一个很令人兴奋的时期。
后训练小结
如果你已经读到这里,那么恭喜你:你现在已经掌握了做好后训练所需的全部核心要素。你已经准备好去跑大量实验,测试不同算法,并争取做到 SOTA 结果。
但正如你可能已经意识到的,知道如何训练出优秀模型,只是故事的一半。要真正把这些模型变成现实,你还需要合适的基础设施。下面就让我们用 LLM 训练中那位“无名英雄”来为这部作品收尾。
基础设施:那位无名英雄
既然你已经了解了我们关于模型构建与训练的全部经验,接下来就该谈谈那个关键却又常被低估的组成部分了。它既可能成就你的项目,也可能拖垮你的项目,甚至连你的预算都会受影响:这就是基础设施。无论你关注的是框架、架构还是数据整理,理解基础设施的基本原理,都有助于识别训练瓶颈、优化并行策略,以及调试吞吐问题。(至少,它还能让你和基础设施团队沟通得更顺畅 😉)。
大多数训练模型的人都非常关心架构和数据,但真正理解基础设施细节的人却很少。基础设施相关的知识通常掌握在框架开发者和集群工程师手中,在其他人看来,它更像一个已经“被解决的问题”:租几张 GPU,装上 PyTorch,就可以开始了。我们在 384 张 H100 上训练 SmolLM3,持续了将近一个月,总共处理了 11 万亿个 tokens……而这段过程一点也不平稳!在那期间,我们遇到了节点故障、存储问题和训练重启(见训练马拉松章节)。你必须提前准备好应急方案和处理策略,才能让训练过程尽可能平稳、低维护。
这一章的目标,就是弥补这部分知识鸿沟。你可以把它看作一份面向硬件层的实用指南,聚焦于训练中真正重要的问题。(注:每个小节开头都有一个 TL;DR,因此你可以按自己需要的深度来读。)
前两个小节会讨论硬件工作原理的基础:GPU 到底由什么组成?内存层级是如何工作的?CPU 和 GPU 是如何通信的?我们也会介绍采购 GPU 时应当考虑哪些因素,以及在真正投入长时间训练之前,应该如何测试它们。更重要的是,我们会在每一步都告诉你,如何亲自去测量和诊断这些系统。后面的章节则更偏应用,我们会讨论如何让你的基础设施更抗故障,以及怎样把训练吞吐尽可能优化到极致。
这一章的核心目标,就是找到并修复瓶颈!
你可以把这一章理解为:建立一种直觉,去理解为什么某些设计决策如此重要。当你理解模型的激活值必须经过多级 cache 流动,而每一级 cache 都有不同的带宽和延迟特性时,你自然就会开始思考,如何组织训练流程,才能尽量减少数据移动。当你看到跨节点通信比节点内通信慢上好几个数量级时,你也就会明白,并行策略为什么会如此关键。
我们先从“拆开”一块 GPU,看看里面到底有什么开始。
GPU 内部:内部架构
从根本上说,GPU 是一种大规模并行处理器,它优先针对吞吐量而不是延迟进行优化。CPU 擅长快速执行少量复杂的指令流,而 GPU 则通过同时执行成千上万个简单操作来获得性能优势。
理解 GPU 性能的关键在于认识到:它不只是原始算力的问题,更是“计算”和“数据移动”之间相互作用的问题。GPU 也许拥有以 TFLOPs 计的理论算力,但如果数据不能足够快地送达计算单元,这些潜力就无法发挥出来。这就是为什么我们既要理解内存层级(数据如何流动),也要理解计算流水线(工作是如何完成的)。
因此,从最高层面看,GPU 会执行两个核心任务:
- 移动和存储数据(内存系统)
- 用这些数据做有意义的计算(计算流水线)
计算单元与 FLOPs
TL;DR: GPU 的性能通常用 FLOPs(每秒浮点运算次数)来衡量。像 H100 这样的现代 GPU,在更低精度下能提供高得多的吞吐:BF16 下可达 990 TFLOPs,而 FP32 下只有 67 TFLOPs。不过,由于内存瓶颈,真实世界中的性能通常只有理论峰值的 70% 到 77%。当前最先进的训练任务,其端到端效率通常在 20% 到 41% 之间,这也被称为 model flops utilization(MFU)。规划训练任务时,要用现实可达的数字,而不是宣传参数。
GPU 的计算性能通常用 FLOPs(floating-point operations per second,每秒浮点运算次数)来衡量。一个 FLOP 就是一条浮点算术操作,最典型的例子是像 a + b 这样的加法;而现代 GPU 每秒可以执行数万亿次这样的操作,也就是 TFLOPs。
GPU 计算最基础的构件是 Streaming Multiprocessors(SM),也就是能够并行执行指令的独立处理单元。每个 SM 中都包含两类 cores:用于标准浮点运算的 CUDA cores,以及专门为矩阵乘法优化的 Tensor Cores。后者是深度学习中的主力运算单元,对 transformer 的性能尤其关键。
现代 GPU 会在整块芯片上组织起数百个这样的 SM。以 H100 的 SXM5 版本为例(这正是我们集群中使用的 GPU),它包含 132 个 SM。每个 SM 都能独立工作,以锁步方式执行一组由 32 个线程组成的 warps。为了实现这一点,SM 还依赖另一个组件:warp schedulers。它们通过在不同 warp 之间调度指令,使 SM 能够在某个 warp 被阻塞时切换到其他 warp,从而“隐藏延迟”。这种 SIMT(Single Instruction, Multiple Thread)执行模型意味着:同一个 warp 中的所有线程会同时在不同数据上执行同一条指令。
在数百个 SM、且每个 SM 都同时执行多个 warp 的情况下,一块 GPU 就可以同时运行数以万计的线程。正是这种大规模并行能力,让 GPU 在深度学习负载中占主导地位的矩阵运算上表现得如此出色。
讨论 FLOPs 时,精度会带来非常显著的差异。Tensor Cores 可以在多种不同精度下工作(FP64、FP32、FP16/BF16、FP8、FP4,关于浮点数可以参考这里)。因此,可达到的吞吐量会随着数据类型不同而发生巨大变化,往往相差一个甚至多个数量级。更低的精度能够实现更高吞吐,因为它们需要搬运的数据更少,而且能在相同的芯片面积中容纳更多运算。但在过去,人们常常因为训练不稳定而避免使用低精度。不过如今,随着一系列新技术的出现,训练和推理都在不断向更低精度推进,已经逐渐走到 FP8,甚至 FP4。
下表展示了 NVIDIA 不同 GPU 世代、不同精度下的理论峰值性能:
| Precision\GPU Type | A100 | H100 | H200 | B100 | B200 |
|---|---|---|---|---|---|
| FP64 | 9.7 | 34 | 34 | 40 | 40 |
| FP32 | 19.5 | 67 | 67 | 80 | 80 |
| FP16/BF16 | 312 | 990 | 990 | 1750 | 2250 |
| FP8 | - | 3960 | 3960 | 4500 | 5000 |
| FP4 | - | - | - | 9000 | 10000 |
表格展示了不同精度与 GPU 代际下的理论 TFLOPs。来源:NVIDIA、SemiAnalysis
在低精度下吞吐量的大幅增长,并不只是“更快”这么简单,它实际上反映了我们对数值计算方式的一个根本性变化。FP8 和 FP4 让模型在每 瓦特 和每 秒 内都能完成更多运算,因此它们已经成为大规模训练和推理中的关键能力。H100 在 FP8 下的 3960 TFLOPs,相比 FP16/BF16 提升了 4 倍;而 B200 在 FP4 下的 10000 TFLOPs,则把这一趋势又进一步推进。
如何理解这些数字:这些理论峰值 FLOPs 表示的是 理想条件下可达到的最大计算吞吐,也就是所有计算单元都被完全利用,且数据可以随取随到。在实际中,真实性能高度依赖于你的工作负载能否持续给计算单元“喂饱”数据,以及这些运算能否高效地映射到现有硬件上。
对于 SmolLM3,我们计划在 NVIDIA H100 80GB HBM3 GPU 上训练,因此首先想验证一下:H100 的理论 TFLOPs 指标,和真实世界中的性能之间到底差多少。为此,我们使用了 SemiAnalysis GEMM benchmark。它会在来自 Meta Llama 70B 训练的真实矩阵乘法形状上测试吞吐。
| Shape (M, N, K) | FP64 torch.matmul | FP32 torch.matmul | FP16 torch.matmul | BF16 torch.matmul | FP8 TE.Linear (autocast, bias=False) | FP8 torch._scaled_mm (e5m2/e4m3fn) | FP8 torch._scaled_mm (e4m3) |
|---|---|---|---|---|---|---|---|
| (16384, 8192, 1280) | 51.5 TFLOPS | 364.5 TFLOPS | 686.5 TFLOPS | 714.5 TFLOPS | 837.6 TFLOPS | 1226.7 TFLOPS | 1209.7 TFLOPS |
| (16384, 1024, 8192) | 56.1 TFLOPS | 396.1 TFLOPS | 720.0 TFLOPS | 757.7 TFLOPS | 547.3 TFLOPS | 1366.2 TFLOPS | 1329.7 TFLOPS |
| (16384, 8192, 7168) | 49.5 TFLOPS | 356.5 TFLOPS | 727.1 TFLOPS | 752.9 TFLOPS | 1120.8 TFLOPS | 1464.6 TFLOPS | 1456.6 TFLOPS |
| (16384, 3584, 8192) | 51.0 TFLOPS | 373.3 TFLOPS | 732.2 TFLOPS | 733.0 TFLOPS | 952.9 TFLOPS | 1445.7 TFLOPS | 1370.3 TFLOPS |
| (8192, 8192, 8192) | 51.4 TFLOPS | 372.7 TFLOPS | 724.9 TFLOPS | 729.4 TFLOPS | 1029.1 TFLOPS | 1404.4 TFLOPS | 1397.5 TFLOPS |
验证理论性能:我们的实验揭示了理论峰值与实际可达性能之间的差距。
对于 FP64 Tensor Core 运算,我们测得 49 到 56 TFLOPs,相当于理论峰值(67 TFLOPs)的 74% 到 84%。对于 TF32(TensorFloat-32,也就是 PyTorch 在 Tensor Cores 上默认用于 FP32 tensors 的格式),我们测得 356 到 396 TFLOPs,相当于理论峰值(稠密计算下约 495 TFLOPs)的 72% 到 80%。虽然这已经说明硬件利用率很高,但在现代深度学习训练中,这两种精度都不太常用:FP64 的问题在于计算成本太高,而 TF32 则因为 BF16、FP8 等更低精度格式能带来更好的性能而逐渐被取代。
对于 BF16 运算,我们在不同矩阵形状下稳定测得 714 到 758 TFLOPs,大约是 H100 理论峰值 990 TFLOPs 的 72% 到 77%。在真实工作负载中,这已经是非常优秀的利用率了!
kernel benchmark 衡量的是原始 TFLOPS,而端到端训练效率通常用 Model FLOPs Utilization(MFU) 来表示:也就是“有效模型计算量”与“硬件理论峰值性能”之间的比值。
我们的 BF16 matmul benchmark 表明,实际达到了 H100 理论峰值的 72% 到 77%。这代表了在我们这套环境里,kernel 层面大致能达到的上限。由于还存在更复杂的非 matmul 操作、通信开销以及其他辅助计算,端到端训练中的 MFU 必然会更低。
训练中的 SOTA MFU:Meta 在训练 Llama 3 405B 时达到了 38% 到 41%,而 DeepSeek-v3 在受 MoE 架构通信瓶颈影响更强的 GPU 环境中达到了约 20% 到 30%。至于 SmolLM3,我们后面会看到,它大约达到了 30% 的 MFU。这个差距有很大一部分来自分布式训练中的跨节点通信开销。考虑到我们的 kernel 层上限大约是 77%,这些端到端数字相当于相对于“可达的 matmul 性能”实现了约 50% 到 55% 的效率。推理任务中的 MFU 可以更高,超过 70%,更接近原始 matmul 性能,不过来自生产部署的公开结果仍然较少。
FP8 的结果则更复杂一些。我们来看一下 3 种不同矩阵乘法方法/内核下的结果。
使用 PyTorch 的 torch._scaled_mm 内核,并采用 e4m3 精度时,我们根据不同矩阵形状测得了 1,210 到 1,457 TFLOPs,大约是理论峰值 3,960 TFLOPs 的 31% 到 37%。😮 为什么会这样?这种较低的利用率百分比(在 FP8 下)其实并不意味着性能差;相反,它反映的是:随着计算吞吐不断升高,这些操作会越来越受到内存限制。 Tensor Cores 处理 FP8 数据的速度,已经快到超过内存系统供数的速度,因此真正的瓶颈变成了内存带宽。
Transformer Engine 的 TE.Linear 在不同形状下达到的是 547 到 1,121 TFLOPs,而 torch._scaled_mm 则始终表现出更高吞吐。这说明了一个重要教训: kernel 的实现方式非常重要 ,即使针对的是同一套硬件能力,仅仅 API 选择不同,性能也可能相差 2 到 3 倍。
对于 SmolLM3 的训练来说,这些实测结果帮助我们建立了更现实的吞吐预期。你在规划自己的训练任务时,也应该用这些“实际可达”的数字,而不是理论峰值,来设定预期。
除了选择合适的 kernel API,我们还必须确保这些 kernels 是为正确的硬件代际编译的。Compute Capability(CC)是 NVIDIA 的版本体系,它把物理 GPU 的细节抽象到 PTX 指令集之上,用来决定你的 GPU 支持哪些指令和功能。
为什么这很重要:为特定 compute capability 编译的 kernel,可能无法在更老的硬件上运行;而如果你的代码没有针对目标 GPU 的 CC 进行编译,你也可能错过本该有的优化。更糟糕的是,框架有时会悄悄选择次优 kernel。我们就发现过,PyTorch 在 H100 上选择了 sm_75 的 kernels(compute capability 7.5,原本是给 Turing GPU 设计的),从而导致莫名其妙的性能下降。PyTorch 社区里也有一个类似问题的记录:框架往往会默认选择更老、兼容性更好的 kernels,而不是最佳 kernels。这个看似不起眼的细节,可能会让同一套硬件的性能,从 720 TFLOPS 掉到 500 TFLOPS。
使用预编译库或自定义 kernels 时,一定要确认它们是为你的硬件 compute capability 构建的,这样才能保证兼容性和最佳性能。例如,sm90_xmma_gemm_…_cublas 就表示这是为 SM 9.0(也就是 compute capability 9.0,H100 所用)编译的 kernel。
你可以通过 nvidia-smi —query-gpu=compute_cap 查看 GPU 的 compute capability,也可以在 NVIDIA CUDA C Programming Guide 的 Compute Capability 章节中查阅相关技术规格。
正如我们刚才看到的,当低精度下的计算速度变得太快时,GPU 内存似乎就会变成瓶颈。接下来我们就来看看 GPU 内存是如何工作的,以及瓶颈究竟是如何产生的。
GPU 内存层级:从寄存器到 HBM
GPU 要完成计算,就必须不断地读写内存,因此理解这些数据传输到底有多快是非常重要的。想写出高性能 kernel,理解 GPU 内存层级是关键。
TL;DR: GPU 会把内存组织成一个层级体系:从快但小的部分(寄存器、shared memory),到慢但大的部分(HBM 主存)。理解这一层级结构非常关键,因为现代 AI 工作负载往往是 memory-bound 的,真正的瓶颈在于搬数据,而不是做计算。像 Flash Attention 这样的 operator fusion,之所以能实现 2 到 4 倍加速,就是因为它把中间结果保留在快速的片上内存中,而不是写回较慢的 HBM。benchmark 表明,H100 的 HBM3 在实际中可以达到约 3 TB/s,基本符合大规模传输时的理论规格。
为了在实践中直观地看到内存操作是如何在 GPU 中流动的,我们先来看 NVIDIA Nsight Compute 的 Memory Chart。这是一种 profiling 图,可以把任意 kernel 中数据在不同内存单元之间的移动情况可视化出来:
一般来说,Memory Chart 同时展示 逻辑单元(绿色),例如 Global、Local、Texture、Surface 和 Shared memory;以及 物理单元(蓝色),例如 L1/TEX Cache、Shared Memory、L2 Cache 和 Device Memory。各单元之间的连线表示两者之间发生的指令数(Inst)或请求数(Req),颜色则表示峰值利用率百分比:从未使用(0%)到满载运行(100%)。
你可以使用 NVIDIA Nsight Compute 为任意 kernel 生成这样的 memory chart:
## 用内存工作负载分析来剖析特定 kernel
ncu --set full --kernel-name "your_kernel_name" --launch-skip 0 --launch-count 1 python your_script.py
## profiling 完成后,在 Nsight Compute GUI 中打开结果查看 Memory Chart
它能提供几个关键洞察:
- 瓶颈识别:被打满的链路(红色/橙色)表明数据移动受限的位置
- Cache 效率:L1/TEX 和 L2 cache 的命中率能反映你的 kernel 对内存层级的利用情况
- 内存访问模式:逻辑单元与物理单元之间的数据流,能显示你的 kernel 是否具备良好的空间/时间局部性
- 端口利用率:即使总体带宽看起来没有打满,某些单独的内存端口也可能已经饱和
在上面的具体例子里,你可以看到 kernel 指令是如何流经内存层级的(这里是我们硬件上的 FP64 矩阵乘法):global load 指令先向 L1/TEX cache 发出请求,可能命中,也可能 miss;如果 miss,就会继续向 L2 发请求,最终在 L2 miss 时访问 device memory(HBM)。单元内部的彩色矩形表示端口利用率,所以即便某些单独链路没有跑满,共享数据端口仍然可能已经饱和。
为了获得最佳性能,你应该尽量减少对较慢内存层(HBM)的访问,同时最大化对较快层(shared memory、registers)的利用。
现在我们来理解一下,让这张图成立的底层内存层级。现代 GPU 会把内存组织成一个在速度、容量和成本之间做平衡的层级结构,而这种设计最终受制于物理规律和电路约束。
在这个层级的最底部,是 HBM(High Bandwidth Memory):也就是 GPU 的主存,也常被称为 global memory 或 device memory。H100 搭载的是 HBM3,理论带宽为 3.35 TB/s。HBM 是整个内存层级里容量最大、但速度最慢的一层。
沿着层级向上,越靠近计算单元,内存会变得越来越快,但容量也越来越小:
- L2 cache:一种基于 SRAM 的大型 cache,由整块 GPU 共享,通常有几十 MB。H100 上这一层是 50 MB,带宽约为 13 TB/s
- L1 cache 和 Shared Memory(SMEM):每个 Streaming Multiprocessor(SM)都有自己的 L1 cache 和由程序员管理的 shared memory,它们共享同一块物理 SRAM 存储。在 H100 上,这部分每个 SM 有 256 KB,带宽约为每个 SM 31 TB/s
- Register File(RMEM):位于层级最顶端,register 是速度最快的存储,直接紧邻计算单元。register 对单个线程私有,带宽可达每个 SM 数百 TB/s 量级
这种层级之所以存在,是因为 SRAM(用于 caches 和 registers)虽然快,但物理面积大、成本高;而 DRAM(用于 HBM)虽然密度高、成本低,但速度慢。结果就是:越快的内存,容量越小、离计算越近;越远的内存池则容量更大,但速度更慢。
为什么这很重要:理解这一层级对于优化 kernel 至关重要。核心洞察在于,memory-bound 操作受限的不是“你能算多快”,而是“你能搬数据多快”。正如 Horace He 在 Making Deep Learning Go Brrrr From First Principles 中解释的,“从内存加载” → “自乘两次” → “写回内存” 与 “从内存加载” → “自乘一次” → “写回内存” 所花的时间几乎一样:和内存访问比起来,计算几乎是“免费的”。
{kind=link}
这就是为什么 operator fusion 如此强大:把多个操作合并进同一个 kernel 后,中间结果就可以保留在快速的 SRAM 里,而不是在每个操作之间反复写回较慢的 HBM。Flash Attention 正是这一原则的经典实例。
标准 attention 实现之所以是 memory-bound 的,是因为它会把完整 attention matrix 物化到 HBM 中:
- 计算
Q @ K^T→ 把 N×N 的 attention scores 写入 HBM - 应用 softmax → 从 HBM 读出,计算,再写回 HBM
- 与 V 相乘 → 再次从 HBM 读取 attention scores
Flash Attention 之所以能实现 2 到 4 倍加速,是因为它把这些操作融合在一起,并把中间结果保留在 SRAM 中:
- 它不再计算完整 attention matrix,而是按能装进 SRAM 的 tile 分块处理 attention
- 中间 attention scores 从不离开快速的片上内存
- 只有最终输出才会写回 HBM
结果是:Flash Attention 将对 HBM 的访问从 O(N²) 降到 O(N),把一个 memory-bound 操作转化为一个能更好利用 GPU 算力的实现。这正是高效 kernel 设计的本质: 尽量减少慢速内存搬运,尽量放大快速计算 。
示例:在实践中验证我们的 HBM3 带宽
现在我们已经理解了内存层级,就来把理论落到实践中,验证一下我们 H100 GPU 上的实际带宽。这正是 benchmarking tools 发挥作用的地方。
NVBandwidth 是 NVIDIA 开源的 benchmark 工具,专门用于测量 GPU 系统中的带宽和延迟。它会使用 copy engine 和基于 kernel 的方式,评估多种内存拷贝模式下的数据传输速率,包括 host-to-device、device-to-host 和 device-to-device。这个工具对于评估 GPU 之间的通信(例如 NVLink 和 PCIe 这两类连接器)尤其有价值,也很适合用于验证多 GPU 环境中的系统性能。
你可以从 NVIDIA 的 GitHub 仓库 安装 NVBandwidth。这个工具会输出详细的带宽矩阵,展示不同设备之间的数据传输效率,因此非常适合用来诊断性能瓶颈,或确认 GPU 互连是否处于健康状态。
我们先用它的 device_local_copy 测试来测量 H100 的本地内存带宽。这个测试会在不同 message size 下,测量 GPU 本地 device buffers 之间通过 cuMemcpyAsync 拷贝时的带宽。
$ ./nvbandwidth -t device_local_copy -b 2048
memcpy local GPU(column) bandwidth (GB/s)
0 1 2 3 4 5 6 7
0 1519.07 1518.93 1519.07 1519.60 1519.13 1518.86 1519.13 1519.33
结果揭示了内存系统的一个重要特性: 当 message size 很小(< 1 MB)时,我们受限于 latency,而不是 bandwidth。发起内存传输本身的开销主导了性能,因此达不到峰值带宽。而 当 message size 足够大(≥ 1 MB)时,我们在读和写两个方向上都能达到约 1,500 GB/s 的持续带宽。
由于 HBM 带宽统计的是同时发生的读写,因此我们把两者相加,得到 3 TB/s 的总双向带宽(1,519 读 + 1,519 写),这与 H100 HBM3 理论上的 3.35 TB/s 非常接近。
Roofline 模型
判断你的 kernel 是 compute-bound 还是 memory-bound,会直接决定哪些优化是有效的。
通常有两种情况:
- 如果你是 memory-bound(大部分时间花在搬数据上),提升计算吞吐并没有帮助:你需要通过 operator fusion 等技术减少内存流量。
- 如果你是 compute-bound(大部分时间花在 FLOPs 上),优化内存访问模式帮助不大:你需要更多算力,或者更好的算法。
roofline model 为理解这类性能特征、以及识别优化空间提供了一个可视化框架。
我们把它用到一个真实 kernel 的分析上。这个视图可以在前面提到的 NSight Compute profiling 工具里找到(位于 “roofline analysis view”)。结果如下:
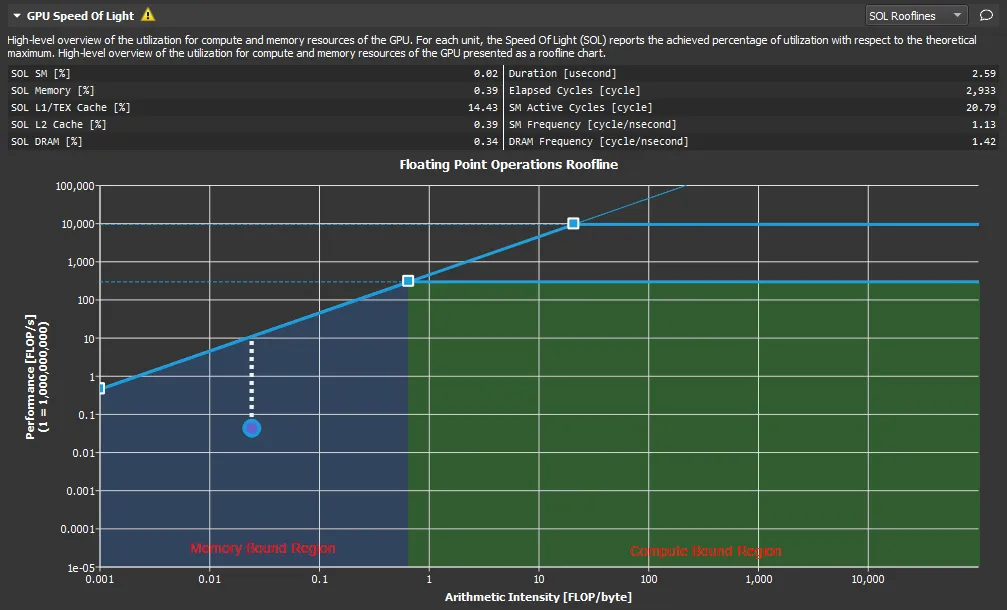
我们来看一下这个图怎么读。它有两个坐标轴:
- 纵轴(FLOP/s):表示实际达到的每秒浮点运算次数,采用对数坐标以容纳很大的数值范围
- 横轴(Arithmetic Intensity):表示工作量(FLOPs)与内存流量(bytes)之间的比值,也就是每 byte 对应多少 FLOPs,同样使用对数坐标
roofline 本身由两条边界组成:
- Memory Bandwidth Boundary(斜线):由 GPU 的内存传输速率(HBM 带宽)决定。位于这条线上的性能,受限于数据搬运速度。
- Peak Performance Boundary(水平线):由 GPU 的最大计算吞吐决定。位于这条线上的性能,受限于计算执行速度。
这两条边界的交点,也就是 ridge point,代表 memory-bound 与 compute-bound 两个区域的分界。
我们可以通过图中划分出的两个区域来理解性能:
- Memory Bound(位于斜线边界下方):这个区域里的 kernels 受限于内存带宽。GPU 在等数据,增加算力没有意义。优化应聚焦于减少内存流量,例如 operator fusion、更好的内存访问模式,或者提高 arithmetic intensity。
- Compute Bound(位于水平边界下方):这个区域里的 kernels 受限于计算吞吐。GPU 有足够数据,但处理不过来。优化应聚焦于算法改进,或者利用 Tensor Cores 这类专用硬件。
图中的 achieved value(也就是那个点)表示你的 kernel 当前所处的位置。这个点距离 roofline 边界的远近,就代表了你的优化空间有多大;越接近边界,说明 kernel 的性能越接近最优。
在我们的例子中,这个 kernel 落在 memory-bound 区域,说明通过优化内存流量,仍然有进一步提升的空间。
如果你想更深入了解 GPU 内部原理,包括 CUDA cores、Tensor Cores、内存层级以及底层优化技巧,可以看看 Ultrascale Playbook。既然我们已经理解了 GPU 内部 发生了什么,下面就把视角拉远,看看 GPU 是如何与外部世界通信的。
GPU 外部:GPU 如何与世界通信
现在我们已经理解了 GPU 如何借助内部内存层级完成计算,但还必须面对一个关键现实:GPU 并不是孤立工作的。在任何计算发生之前,数据必须先被加载进 GPU 内存;CPU 需要负责调度 kernels 和协调工作;而在分布式训练中,GPU 之间还必须持续交换 activations、gradients 和模型权重。

这正是外部通信基础设施变得关键的地方。不管 GPU 的计算单元有多强,如果数据不能足够快地从 CPU、存储或其他 GPU 送到它那里,那么昂贵的硬件就只能空转。理解这些通信路径及其带宽特性,是最大化硬件利用率、最小化瓶颈的关键。
这一节里,我们会看四条把 GPU 与外部世界连接起来的关键通信链路:
- GPU-CPU:CPU 如何调度工作并向 GPU 传输数据
- GPU-GPU intra-node:同一台机器内的 GPU 如何互相通信
- GPU-GPU inter-node:不同机器上的 GPU 如何通过网络通信
- GPU-Storage:数据如何从存储流入 GPU 内存
这些链路各自都有不同的带宽和延迟特性。理解它们,有助于你找出训练流水线中的潜在瓶颈。为了让这一点更容易理解,我们做了一张简化图,突出展示最重要的组件和通信链路:
如果这看起来有点复杂,也不用担心。我们会逐一深入讲解这些连接,并测量它们的实际带宽,从而理解每条链路的性能特征。
GPU 到 CPU
TL;DR: CPU 通过 PCIe 连接来编排 GPU 工作;在我们的 p5 实例中,CPU 到 GPU 的传输瓶颈大约是 14.2 GB/s(PCIe Gen4 x8)。CPU-GPU 延迟约为 1.4 微秒,这会带来 kernel launch 开销,对于包含大量小 kernel 的工作负载尤其成问题。CUDA Graphs 可以通过批量重放操作来降低这类开销。在多路 socket 系统中,NUMA affinity 非常关键;如果 GPU 进程跑在错误的 CPU socket 上,会显著增加延迟。像 Grace Hopper 这样的现代架构则用 NVLink-C2C(900 GB/s 对比 128 GB/s)消除了 PCIe 瓶颈。
CPU 是 GPU 计算的调度者。它负责启动 kernels、管理内存分配,并协调数据传输。但 CPU 实际上能以多快的速度和 GPU 通信?这取决于它们之间的 PCIe(Peripheral Component Interconnect Express) 连接。
理解这条链路之所以关键,是因为它会影响:
- Kernel launch latency:CPU 能多快把工作调度到 GPU 上
- Data transfer speed:CPU 与 GPU 内存之间数据搬运有多快
- Synchronization overhead:CPU-GPU 协调点带来的开销
在现代 GPU 服务器中,CPU-GPU 连接方式已经有了很大演进。早期系统通常使用直接 PCIe 连接,而像 DGX H100 这样的现代高性能系统,则采用了更复杂的拓扑,通过 PCIe switches 高效管理多张 GPU。而在最新的 GB200 架构 中,NVIDIA 更进一步,把 CPU 和 GPU 放到了同一块印刷电路板上,彻底消除了外部 switches 的需求。
下面我们先用 lstopo 查看 p5 实例的物理拓扑,再测量这条关键链路的真实性能,找出潜在瓶颈。
$ lstopo -v
...
HostBridge L#1 (buses=0000:[44-54])
PCIBridge L#2 (busid=0000:44:00.0 id=1d0f:0200 class=0604(PCIBridge) link=15.75GB/s buses=0000:[45-54] PCISlot=64)
PCIBridge L#3 (busid=0000:45:00.0 id=1d0f:0200 class=0604(PCIBridge) link=15.75GB/s buses=0000:[46-54] PCISlot=1-1)
...
PCIBridge L#12 (busid=0000:46:01.4 id=1d0f:0200 class=0604(PCIBridge) link=63.02GB/s buses=0000:[53-53])
PCI L#11 (busid=0000:53:00.0 id=10de:2330 class=0302(3D) link=63.02GB/s PCISlot=86-1)
Co-Processor(CUDA) L#8 (Backend=CUDA GPUVendor="NVIDIA Corporation" GPUModel="NVIDIA H100 80GB HBM3" CUDAGlobalMemorySize=83295872 CUDAL2CacheSize=51200 CUDAMultiProcessors=132 CUDACoresPerMP=128 CUDASharedMemorySizePerMP=48) "cuda0"
GPU(NVML) L#9 (Backend=NVML GPUVendor="NVIDIA Corporation" GPUModel="NVIDIA H100 80GB HBM3" NVIDIASerial=1654922006536 NVIDIAUUID=GPU-ba136838-6443-7991-9143-1bf4e48b2994) "nvml0"
...
...
从 lstopo 的输出中,我们可以看到系统里两个关键的 PCIe 带宽数值:
- 15.75GB/s:对应 PCIe Gen4 x8 链路(CPU 到 PCIe switches)
- 63.02GB/s:对应 PCIe Gen5 x16 链路(PCIe switches 到 GPU)
为了更直观地理解整体拓扑,我们可以把它可视化:
$ lstopo --whole-system lstopo-diagram.png
这张图展示了我们系统的层级结构:
- 它包含两个 NUMA(Non-Uniform Memory Access)节点(可以把 NUMA 理解为每个 CPU socket 对应的一块内存区域)
- 每个 CPU socket 通过 PCIe Gen4 x8 链路(15.75GB/s)连接到四个 PCIe switches
- 每个 PCIe switch 再通过 PCIe Gen5 x16 链路(63.02GB/s)连接到一张 H100 GPU
- …(其他组件,例如 NVSwitch、EFA 网卡和 NVMe 硬盘,我们会在后续小节里继续展开)
PCIe 规范会随着代际演进而变化,每一代通常都会让每条 lane 的传输速率翻倍。需要注意的是,Transfer Rate 用 GT/s(GigaTransfers per second)表示,它代表原始信号速率;而 Throughput 用 GB/s(Gigabytes per second)表示,它考虑了编码开销,更能反映实际可用带宽:
| PCIe Version | Transfer Rate (per lane) | Throughput (GB/s) |
|---|---|---|
| ×1 | ×2 | ×4 |
| 1.0 | 2.5 GT/s | 0.25 |
| 2.0 | 5.0 GT/s | 0.5 |
| 3.0 | 8.0 GT/s | 0.985 |
| 4.0 | 16.0 GT/s | 1.969 |
| 5.0 | 32.0 GT/s | 3.938 |
| 6.0 | 64.0 GT/s | 7.563 |
| 7.0 | 128.0 GT/s | 15.125 |
从拓扑图和 PCIe 带宽表中可以看出,CPU 到 GPU 的路径要经过两跳 PCIe:先从 CPU 到 PCIe switch,使用 PCIe Gen4 x8(15.754 GB/s);再从 PCIe switch 到 GPU,使用 PCIe Gen5 x16(63.015 GB/s)。 这意味着 CPU-GPU 通信的瓶颈其实是第一跳,也就是 15.754 GB/s。 下面我们再用一个工具 nvbandwidth 来验证这一点。
host_to_device_memcpy_ce 命令会使用 GPU 的 copy engines,测量 cuMemcpyAsync 从 host(CPU)内存到 device(GPU)内存的带宽。
./nvbandwidth -t host_to_device_memcpy_ce -b <message_size> -i 5
结果确实表明:小 message size 下我们受限于 latency;但在大 message size 下,能达到 约 14.2 GB/s,大约相当于 PCIe Gen4 x8 理论带宽 15.754 GB/s 的 90%。这验证了在 CPU-GPU 通信中,CPU 到 PCIe switch 的这段链路确实是瓶颈。
除了带宽之外,latency 对 CPU-GPU 通信同样重要,因为它决定了我们能多快地调度 kernel。为了测量这一点,我们使用 nvbandwidth 的 host_device_latency_sm 测试,它通过一个 pointer-chase kernel 来测量往返延迟。这个测试会先在 host(CPU)上分配 buffer,再让 GPU 通过 pointer-chase kernel 访问它,从而模拟真实世界中的 CPU-GPU 通信延迟。
./nvbandwidth -t host_device_latency_sm -i 5
结果表明,latency 大约是 1.4 微秒。这也解释了我们在 ML 工作负载中经常观察到的几微秒级 kernel launch 开销。对于会频繁启动很多小 kernel 的工作负载,这部分额外延迟就可能成为瓶颈;否则,它通常会被重叠执行所掩盖。
CUDA Graphs 可以通过捕获一串操作并把它们作为一个整体重放,显著降低 kernel launch 开销,从而避免每次 kernel 启动都支付几微秒的 CPU-GPU 往返延迟。这对那些包含大量小 kernel、或者频繁发生 CPU-GPU 同步的工作负载尤其有利。关于如何理解和优化 launch overhead,可以参考 Understanding the Visualization of Overhead and Latency in NVIDIA Nsight Systems。
某些 Mixture-of-Experts(MoE)模型的实现,需要在每次迭代中进行 CPU-GPU 同步,以便为被选中的 experts 调度对应 kernels。这会引入 kernel launch 开销,尤其在 CPU-GPU 连接较慢时,会显著影响吞吐。例如,在 MakoGenerate 对 DeepSeek MOE kernels 的优化 中,参考实现每次 forward 会发出 1,043 个 kernels,并包含 67 个 CPU-GPU 同步点。通过重构 expert routing 机制,他们把这一数字降到了 533 次 kernel 启动和 3 个同步点,实现了 97% 的同步开销下降,以及 44% 的端到端延迟下降。需要注意的是,并不是所有 MoE 实现都需要 CPU-GPU 同步(现代实现通常会把 routing 完全保留在 GPU 上),但对那些确实需要的实现来说,高效的 CPU-GPU 通信就会变得至关重要。
与传统的 x86+Hopper 系统相比,NVIDIA 的 Grace Hopper superchips 在 CPU-GPU 通信上采用了根本不同的思路。关键改进包括:
- 1:1 的 GPU 与 CPU 配比(相比之下,x86+Hopper 通常是 4:1),从而为每张 GPU 提供 3.5 倍更高的 CPU 内存带宽
- 用 NVLink-C2C 取代 PCIe Gen5 lanes,实现 900 GB/s 对比 128 GB/s 的带宽(GPU-CPU 链路带宽提升 7 倍)
- NVLink Switch System 提供了比通过 PCIe Gen4 连接的 InfiniBand NDR400 NICs 高 9 倍的 GPU-GPU 链路带宽
更多细节可参考 NVIDIA Grace Hopper Superchip Architecture Whitepaper(第 11 页)。
⚠️ NUMA Affinity:多路 socket 性能的关键
在像我们 AMD EPYC 7R13 节点(2 个 sockets,每个 48 核)这样的多路 socket 系统中,NUMA affinity 对 GPU 性能至关重要。它指的是:让进程运行在与目标设备(比如 GPU)属于同一个 socket 的 CPU cores 上。如果 GPU 进程运行在与 GPU 所连接的 NUMA 节点不同的 CPU 上,那么相关操作就必须穿过 CPU 互连(AMD Infinity Fabric),这会显著增加延迟,并带来额外带宽限制。
首先,我们先看看 NUMA 拓扑和节点距离,以理解它对性能的影响:
$ numactl --hardware
node distances:
node 0 1
0: 10 32
1: 32 10
这些 distance 数值表明:访问同一个 NUMA 节点上的内存(distance 10),要比跨到另一个 NUMA 节点(distance 32)快得多。这种 3.2 倍 的内存访问 延迟 差异,在你的进程被 pin 到错误 NUMA 节点上时,会显著影响 GPU 性能。
关于如何诊断并解决 NUMA 相关性能问题的详细步骤,请参见后面的 Troubleshooting Interconnect Performance 一节。
节点内 GPU 到 GPU 通信
在分布式训练中,GPU 必须频繁交换 gradients、weights 和 activations,每次迭代往往就是数 GB 的数据。这么大的数据量要求我们非常谨慎地处理通信问题。虽然 H100 内部的 HBM 读取速度大约有 3 TB/s,但如果不小心用了错误的 flags,你的 GPU-GPU 通信带宽可能会直接“翻车”。
下面我们就来看看,节点内 GPU 之间到底有哪些通信方式,以及哪些 flags 应该设置、哪些不该设置。🙂
TL;DR: 同一节点内的 GPU 有三种通信方式:通过 CPU(最慢,约 ~3 GB/s,受 PCIe 限制)、通过 EFA 网卡走 GPUDirect RDMA(约 ~38 GB/s),或者通过 NVLink 走 GPUDirect RDMA(双向约 ~786 GB/s)。NVLink 快 9 到 112 倍,而且完全绕过 CPU/PCIe。NCCL 在可用时会自动优先使用 NVLink。NVLink SHARP(NVLS)还能提供硬件加速的 collectives,把 allreduce 性能提升 1.3 倍,达到 480 GB/s。不过 alltoall(340 GB/s)并不能从 NVLS 加速中受益。
通过 CPU
最朴素的方法是使用 host memory(SHM):数据从 GPU1 出发,经由 PCIe switch 传到 CPU,再进到 host memory,然后又从 CPU 返回,重新经过 PCIe switch,最后抵达 GPU2。这个模式可以通过设置 NCCL 的环境变量 NCCL_P2P_DISABLE=1 和 FI_PROVIDER=tcp 来实现(虽然并不推荐)。当该模式开启时,你可以通过设置 NCCL_DEBUG=INFO 来验证,它会打印类似下面这样的信息:
NCCL INFO Channel 00 : 1[1] -> 0[0] via SHM/direct/direct
这种绕路方式涉及多次内存拷贝,并会同时打满 PCIe 和 CPU 内存总线,造成拥塞。在我们的拓扑里,4 张 H100 共享同一组 CPU 内存总线,因此当多张 GPU 同时尝试通信时,问题会更加严重,因为它们都在争抢同一份有限的 CPU 内存带宽……😢
在这种经由 CPU 中转的方式下,我们从根本上受限于 CPU 和 PCIe switch 之间大约 ~16 GB/s 的 PCIe Gen4 x8 链路。好在,GPU 之间还有更好的通信方式,不需要让 CPU 参与: GPUDirect RDMA。
通过 Libfabric EFA
GPUDirect RDMA(Remote Direct Memory Access,或简称 GDRDMA)是一项允许直接访问 GPU 内存、从而实现 NVIDIA GPU 之间直接通信的技术。它消除了数据必须经过系统 CPU 的需求,也避免了通过系统内存进行 buffer 拷贝,因此相较于传统经由 CPU 中转的传输,性能最高可以提升 10 倍。GPUDirect RDMA 通过 PCIe 工作,既可以支持节点内的 GPU-GPU 高速通信(正如这里所示),也能借助具备 RDMA 能力的 NICs(network interface cards,后面的小节会展开)支持跨节点通信。更多细节可见 NVIDIA GPUDirect。
回到前面的拓扑图,我们可以看到每个 PCIe switch 下都挂着 4 张 EFA(Elastic Fabric Adapter)NIC,也就是说每张 GPU 都能访问 4 个 EFA adapters。 EFA 是 AWS 为云实例设计的高性能网络接口,目标是提供低延迟、高吞吐的实例间通信。在 p5 实例上,EFA 会暴露一个 libfabric 接口(面向高性能计算的一类通信 API),供应用使用,并提供类似 RDMA 的能力,从而支持 GPUDirect RDMA,实现跨节点的直接 GPU-GPU 通信。
$ lstopo -v
...
## We can see 4 such EFA devices per each PCIe switch
PCIBridge L#8 (busid=0000:46:01.0 id=1d0f:0200 class=0604(PCIBridge) link=15.75GB/s buses=0000:[4f-4f] PCIVendor="Amazon.com, Inc.")
PCI L#6 (busid=0000:4f:00.0 id=1d0f:efa1 class=0200(Ethernet) link=15.75GB/s PCISlot=82-1 PCIVendor="Amazon.com, Inc.")
OpenFabrics L#4 (NodeGUID=cd77:f833:0000:1001 SysImageGUID=0000:0000:0000:0000 Port1State=4 Port1LID=0x0 Port1LMC=1 Port1GID0=fe80:0000:0000:0000:14b0:33ff:fef8:77cd) "rdmap79s0"
...
$ fi_info --verbose
fi_link_attr:
address: EFA-fe80::14b0:33ff:fef8:77cd
mtu: 8760 # maximum packet size is 8760 bytes
speed: 100000000000 # each EFA link provides 100 Gbps of bandwidth
state: FI_LINK_UP
network_type: Ethernet
每条 EFA 链路 都提供 100 Gbps(12.5 GB/s)的带宽。由于每张 GPU 配有 4 张 EFA NICs,而每个节点有 8 张 GPU,因此总带宽为 100 × 4 × 8 = 每节点 3200 Gbps(400GB/s)。
为了确保我们启用了走 EFA 的 GPUDirect RDMA,你需要设置环境变量 FI_PROVIDER=efa 和 NCCL_P2P_DISABLE=1。开启之后,可以再设置 NCCL_DEBUG=INFO 来验证它是否真的生效。你会看到类似下面这样的信息:
NCCL INFO Channel 01/1 : 1[1] -> 0[0] [receive] via NET/Libfabric/0/GDRDMA/Shared
虽然通过 EFA 的 GPUDirect RDMA 相比经由 CPU 中转已经有了显著提升,在每张 GPU 使用 4 张 EFA 卡的情况下可达到大约 50 GB/s,但我们还能不能做得更好?这就是 NVLink 登场的地方。
通过 NVLink
NVLink 是 NVIDIA 的高速、直接 GPU-GPU 互连技术,用于在服务器内部实现快速多 GPU 通信。 H100 使用的是第四代 NVLink(NVLink 4.0),每张 GPU 通过 18 条链路提供 900 GB/s 的双向带宽,每条链路的双向带宽为 50 GB/s(见 NVIDIA H100 Tensor Core GPU Datasheet)。
在 DGX H100 的架构中,4 个第三代 NVSwitch 使用分层拓扑连接 8 张 GPU,每张 GPU 分别通过 5+4+4+5 条链路连接到这些 switches。这个配置保证任意一对 GPU 之间都存在多条直接路径,并且 hop 数恒定为 1 个 NVSwitch,因此整个 NVLink 网络总共能提供 3.6 TB/s 的双向带宽。
| NVLink 2.0 (Volta) | NVLink 3.0 (Ampere) | NVLink 4.0 (Hopper) | NVLink 5.0 (Blackwell) |
|---|---|---|---|
| Bandwidth | 300 GB/s | 600 GB/s | 900 GB/s |
表:各代 NVLink 带宽对比,展示理论规格
默认情况下,只要可用,NCCL 就会优先使用 NVLink 进行节点内 GPU 通信,因为它在同机 GPU 之间提供了最低延迟和最高带宽的路径。不过,如果你的 flags 没设置对,反而可能会阻止 NVLink 被使用!😱
NVLink 允许 GPU 直接访问彼此的内存,而不需要经过 CPU 或系统内存。当 NVLink 不可用时,NCCL 会回退到走 PCIe 的 GPUDirect P2P;如果跨 socket 的 PCIe 传输并不理想,还可能回退到 Shared Memory(SHM)传输。
要验证 NVLink 是否正在被使用,可以设置 NCCL_DEBUG=INFO,然后查找类似下面这样的输出:
NCCL INFO Channel 00/1 : 0[0] -> 1[1] via P2P/CUMEM
下图展示了在使用 NVLink 时,数据所走的直接路径:
与 EFA 的约 ~50 GB/s 相比, NVLink 4.0 的理论带宽是 900 GB/s,因此我们预期它在节点内通信上有 18 倍优势。为了在实践中验证这一点,我们运行了 NCCL 的 SendRecv 性能测试,测量不同通信路径下的实际带宽:
$ FI_PROVIDER=XXX NCCL_P2P_DISABLE=X sendrecv_perf -b 8 -e 8G -f 2 -g 1 -c 1 -n 100
这个结果毫无疑问地说明了 NVLink 的高效程度:它达到了 364.93 GB/s,而 EFA 只有 38.16 GB/s(快 9 倍,若按双向算则是 18 倍),CPU 基线更是只有 3.24 GB/s(快了 112.6 倍)。这些测量结果也解释了为什么 NCCL 会优先用 NVLink 进行节点内 GPU 通信。为了进一步检查 NVLink 的性能,我们再用 nvbandwidth 来测量所有 GPU 对之间的双向带宽,也就是在两个方向上同时做拷贝:
./nvbandwidth -t device_to_device_bidirectional_memcpy_write_ce -b <message_size> -i 5
memcpy CE GPU(row) <-> GPU(column) Total bandwidth (GB/s)
0 1 2 3 4 5 6 7
0 N/A 785.81 785.92 785.90 785.92 785.78 785.92 785.90
1 785.83 N/A 785.87 785.83 785.98 785.90 786.05 785.94
2 785.87 785.89 N/A 785.83 785.96 785.83 785.96 786.03
3 785.89 785.85 785.90 N/A 785.96 785.89 785.90 785.96
4 785.87 785.96 785.92 786.01 N/A 785.98 786.14 786.08
5 785.81 785.92 785.85 785.89 785.89 N/A 786.10 786.03
6 785.94 785.92 785.99 785.99 786.10 786.05 N/A 786.07
7 785.94 786.07 785.99 786.01 786.05 786.05 786.14 N/A
SUM device_to_device_bidirectional_memcpy_write_ce_total 44013.06
测得的双向带宽为 786 GB/s,相当于 NVLink 4.0 理论 900 GB/s 规格的 85%。使用 NVLink 后,我们就在 GPU-GPU 通信路径上彻底绕开了 CPU 瓶颈!
但这在 collective communication 模式下又意味着什么?下面我们使用 NCCL tests 中的 all_reduce_perf benchmark 来测量单节点内的 allreduce 性能。
$ ./all_reduce_perf -b 8 -e 16G -f 2 -g 1 -c 1 -n 100
等等……我们测到了 480 GB/s,这竟然超过了 NVLink 4.0 理论上的单向带宽 450 GB/s 😮 这是什么魔法,为什么会这样?
稍微翻一下文档,答案似乎在于 NVLink SHARP(NVLS),也就是 NVIDIA 的硬件加速 collective operations 技术。它能让单节点 H100 GPU 上的 allreduce 获得大约 1.3 倍加速!
关于 NVSwitch 如何支持这种硬件加速 collective operations 的技术细节,可以参考 NVSwitch architecture presentation。
那么它在其他场景里也有帮助吗?我们来看看 alltoall 性能:
$ ./all_to_all_perf -b 8 -e 16G -f 2 -g 1 -c 1 -n 100
我们在 alltoall 操作上测到了 340 GB/s,这与公开 benchmark 中 H100 + NVLink 4.0 系统所表现出的性能特征一致(来源)。与 allreduce 不同,alltoall 并不能从 NVLS 的硬件加速中获益,这也解释了为什么这里是 340 GB/s,而 allreduce 能做到 480 GB/s。alltoall 模式需要所有 GPU 对之间进行更复杂的点对点数据交换,因此它依赖的只是 NVLink 的基础带宽,而不是 NVSwitch 提供的 collective acceleration 特性。
一些优化过的 kernels 会把 NVLink 通信与计算分离开来,为传输专门分配独立的 warps。例如,ThunderKittens 使用一种 warp-level 设计:部分 warps 负责发起 NVLink 传输并等待完成,而其他 warps 则继续进行计算。这种在细粒度上重叠 SM 计算与 NVLink 通信的方式,可以隐藏掉大部分跨 GPU 通信延迟。实现细节可以参考 ThunderKittens 关于多 GPU kernels 的博客文章。
虽然 NVLink 在单节点内提供了极高带宽,但训练 frontier 模型终究需要扩展到多个节点。
这就引入了一个新的潜在瓶颈:节点间网络互连,它的带宽远低于 NVLink。
跨节点 GPU 到 GPU 通信
TL;DR 多节点 GPU 通信依赖于 InfiniBand(400 Gbps)或 RoCE(100 Gbps)等高速网络。Allreduce 的扩展性较好(跨节点后仍能稳定在 320-350 GB/s),这也是超大训练集群能够工作的关键。由于算法复杂度更高,alltoall 的退化要明显得多。延迟则会从节点内约 ~13μs 跳升到跨节点 55μs 以上。对于需要频繁 all-to-all 的 MoE 工作负载,NVSHMEM 提供了由 GPU 发起的异步通信,相比由 CPU 协调的数据传输具有显著更好的性能。
当模型规模超出单节点能容纳的范围后,训练就必须分布到通过高速网络互联的多个节点上。在看 benchmark 之前,我们先看看多节点 GPU 集群中最常见的 3 类关键网络技术:
- Ethernet 已经从 1 Gbps 发展到 100+ Gbps,并且仍然被广泛用于 HPC 和数据中心集群。
- RoCE(RDMA over Converged Ethernet) 把 RDMA 能力带到了以太网中,并使用 ECN 而不是传统 TCP 机制来做拥塞控制。
- InfiniBand 是 NVIDIA 的行业标准交换网络,带宽可达 400 Gbps,延迟低于 1 微秒,并支持 RDMA,从而借助 GPUDirect RDMA 实现绕过 host CPU 的直接 GPU-GPU 内存访问。
总结如下:
| Name | Ethernet (25–100 Gbps) | Ethernet (200–400 Gbps) | RoCE | Infiniband |
|---|---|---|---|---|
| Manufacturer | Many | Many | Many | NVIDIA/Mellanox |
| Unidirectional Bandwidth (Gbps) | 25–100 | 200–400 | 100 | 400 |
| End to End Latency (μs) | 10-30 | N/A | ~1 | <1 |
| RDMA | No | No | Yes | Yes |
表:互连技术对比。来源:https://www.sciencedirect.com/science/article/pii/S2772485922000618
在 AWS p5 实例上,我们使用的是 Elastic Fabric Adapter(EFA) 作为 NIC(Network Interface Card)。正如前面看到的,每张 GPU 都通过 PCIe Gen5 x16 lanes 连接到 4 张 100 Gbps 的 EFA 网卡。
如上图所示,当 GPU 和网卡连接在同一个 PCIe switch 上时, GPUDirect RDMA 能让它们的通信仅在该 switch 内完成。这样就可以充分利用 PCIe Gen5 x16 的带宽,同时避免经过其他 PCIe switches 或 CPU 内存总线。 从理论上看,每个节点有 8 个 PCIe Switches,每个 switch 下有 4 张 EFA NIC,每张 EFA NIC 提供 100 Gbps,因此总带宽是 3200 Gbps(400GB/s),这也正是 AWS p5 规格 里给出的数字。那么实践中到底表现如何?下面我们继续运行和前面同样的 benchmarks,只不过这次跨不同节点来测!
带宽分析
点对点 send/receive 操作在 2 到 4 个节点时能达到大约 42-43 GB/s,但在 5 个及以上节点时会下降到约 21 GB/s。这种性能下降是因为,当节点数超过 4 时,NCCL 会自动把每个 peer 的 point-to-point channels 数量从 2 降到 1,等于把可用带宽利用率直接砍半;而理论最大值仍然约为 ~50 GB/s(4 张 EFA NIC × 每张 12.5 GB/s)。我们通过设置 NCCL_NCHANNELS_PER_NET_PEER=2,成功在 5 个以上节点上恢复了该测试的完整吞吐。不过,这个 flag 需要谨慎使用,因为它可能会让 all-to-all 性能变差(详见 GitHub issue #1272)。
all-reduce 在单节点内表现非常出色,bus bandwidth 可达 480 GB/s。扩展到 2 个节点时,带宽几乎不变,仍有 479 GB/s;之后在 3 到 16 个节点之间,会稳定在约 320-350 GB/s。这个现象揭示了一个重要特性:虽然在跨节点时,由于从 NVLink 切换到节点间网络 fabric,带宽会先掉一截,但 随着节点继续增加,带宽随后会近似保持稳定扩展。
这种在 2 个节点之后近似恒定的扩展行为,其实对大规模训练来说非常令人鼓舞。3 到 16 个节点之间相对稳定的 320-350 GB/s,说明依赖 all-reduce 的并行策略(例如数据并行)可以扩展到数百甚至数千张 GPU,而不会出现显著的单 GPU 带宽劣化。这种近似对数式的扩展特征,通常出现在设计良好的多层网络拓扑中,例如使用 8-rail 优化 fat tree 的集群,在这种结构里,8 张 GPU 会分别连接到不同的 switch rail,以最大化 bisection bandwidth。现代 frontier 训练集群经常运行在 10 万张以上 GPU 的规模上,而这种稳定扩展行为正是这种超大部署成为可能的原因。
当系统里同时存在不同带宽层级的链路(例如节点内的 NVLink 与节点间网络)时,应考虑针对不同带宽层来调整并行策略,以充分利用所有可用带宽。关于如何在异构网络拓扑下优化并行配置,可参考 Ultrascale playbook。
all-to-all 则表现出更加明显的扩展挑战:单节点时起步有 344 GB/s,但到了 2 个节点就掉到 81 GB/s,在更大的集群里还会继续下降到约 45-58 GB/s。相比之下更陡峭的退化,反映的是 all-to-all 模式对网络的高强度需求,因为每张 GPU 都必须跨节点和所有其他 GPU 通信,这会比 all-reduce 产生更严重的网络拥塞。
延迟分析
Latency 测量揭示了跨越节点边界的基本代价。send/receive 操作在所有多节点配置下都维持在相对稳定的 40-53 μs,这说明点对点通信延迟主要由网络基础往返时间决定,而不是由集群规模决定,不过其中的一些波动也说明网络拓扑和路由路径仍然会产生影响。
all-reduce 在单节点内的最小延迟只有 12.9 μs,但到了 2 个节点时就会跳到 55.5 μs,并且几乎随着集群规模线性上升,在 16 个节点时达到 235 μs。这种增长同时反映了通信距离变长,以及 reduction tree 在节点增多后变得更复杂。
all-to-all 也表现出类似趋势:单节点时只有 7.6 μs,到了 2 个节点就涨到 60 μs,在 16 个节点时更是达到 621 μs。all-to-all 延迟的超线性增长说明,随着更多节点参与 collective,网络拥塞与协调开销会叠加放大。
随着 Mixture of Experts(MoE)架构的兴起,由于 expert routing 需要频繁执行 all-to-all 通信模式,优化过的 GPU 通信库也变得越来越关键。
NVSHMEM 作为一种高性能通信库,正在迅速获得关注。它把多张 GPU 的内存组合成一个 partitioned global address space(PGAS)。与依赖 CPU 协调数据传输的传统 MPI 方法不同,NVSHMEM 支持由 GPU 发起的异步操作,从而消除了 CPU-GPU 同步开销。
NVSHMEM 在 GPU 通信上有几个关键优势:通过 GPUDirect Async 之类的技术,GPU 在发起跨节点通信时可以完全绕过 CPU,在小消息(<1 KiB)场景下可实现最高 9.5 倍吞吐提升。这对那些需要高强度网络通信模式的 collective operations 尤其有利。
目前,这个库支持搭配 Mellanox 适配器(CX-4 及以后版本)的 InfiniBand/RoCE、Slingshot-11(Libfabric CXI),以及 Amazon EFA(Libfabric EFA)。对于那些要求强扩展且通信粒度很细的应用,NVSHMEM 的低开销、单边通信 primitives 相比传统 CPU-proxy 方法能显著提升性能。
更多内容可参考 NVSHMEM documentation,以及这篇详细介绍 GPUDirect Async 的博客文章。
当带宽测量结果低于预期时,可能有多个因素在限制性能。理解这些潜在瓶颈,是把互连利用率调到最优的关键。
互连故障排查
如果你遇到的带宽低于预期,可以系统地检查以下几个方面:
库版本
过旧的 NCCL、EFA 或 CUDA 库,可能缺少关键性能优化或 bug 修复。应始终确认你使用的是近期且兼容的通信库版本。例如,AWS 会定期更新其 Deep Learning AMIs,为他们的硬件提供优化过的库版本。对于重要实验,也建议把这些库版本记录下来。
CPU Affinity 配置
不正确的 CPU affinity 设置会造成不必要的跨 NUMA 流量,从而显著影响 NCCL 性能。每张 GPU 都应绑定到同一个 NUMA 节点上的 CPU,以尽量降低内存访问延迟。在实践中,这个 Github issue 展示了使用 NCCL_IGNORE_CPU_AFFINITY=1 和 --cpu-bind none 如何显著降低容器延迟。相关背景可见这里。
网络拓扑与放置位置
理解你的网络拓扑对于诊断性能问题非常关键。云上的 placement groups 虽然有帮助,但并不能保证实例之间的网络跳数最小。在现代数据中心的 fat-tree 拓扑中,如果实例落在不同的顶层 switch 下,由于路由路径中多了额外的网络跳数,就会带来更高延迟,以及潜在更低的带宽。
对于 AWS EC2 用户来说,Instance Topology API 能够提供非常有价值的网络节点放置信息。那些共享同一个底层网络节点(也就是直接连接到实例的那一层)的实例,在物理上彼此最近,因此能够实现最低延迟的通信。
graph TD
%% Single Level 1 node
L1["Level 1
nn-4aed5..."]:::level1
%% Single Level 2 node
L2["Level 2
nn-48b0a..."]:::level2
%% 12 nodes of Level 3
L3_1["Level 3
nn-d2ad4..."]:::level3
L3_2["Level 3
nn-2d36a..."]:::level3
L3_3["Level 3
nn-65fc9..."]:::level3
L3_4["Level 3
nn-fbb73..."]:::level3
L3_5["Level 3
nn-65290..."]:::level3
L3_6["Level 3
nn-27373..."]:::level3
L3_7["Level 3
nn-5adeb..."]:::level3
L3_8["Level 3
nn-dbe4f..."]:::level3
L3_9["Level 3
nn-fde84..."]:::level3
L3_10["Level 3
nn-3c5c0..."]:::level3
L3_11["Level 3
nn-94247..."]:::level3
L3_12["Level 3
nn-8f3c1..."]:::level3
%% L1 -> L2
L1 --> L2
%% L2 -> L3 (12 arrows)
L2 --> L3_1
L2 --> L3_2
L2 --> L3_3
L2 --> L3_4
L2 --> L3_5
L2 --> L3_6
L2 --> L3_7
L2 --> L3_8
L2 --> L3_9
L2 --> L3_10
L2 --> L3_11
L2 --> L3_12
%% Distribution Level 3 -> Leaf nodes (instance info)
%% 1st Level 3 has 2 leaves
L3_1 --> L4_1["ID: 02e1b4f9
ip-26-0-171-102
p5.48xlarge"]:::level4
L3_1 --> L4_2["ID: 05388ebf
ip-26-0-171-230
p5.48xlarge"]:::level4
%% 2nd, 3rd, 4th have 1 each
L3_2 --> L4_3["ID: 03bfac00
ip-26-0-168-30
p5.48xlarge"]:::level4
L3_3 --> L4_4["ID: d92bab46
ip-26-0-168-95
p5.48xlarge"]:::level4
L3_4 --> L4_5["ID: 97a542e4
ip-26-0-163-158
p5.48xlarge"]:::level4
%% 5th has 3
L3_5 --> L4_6["ID: e2c87e43
ip-26-0-167-9
p5.48xlarge"]:::level4
L3_5 --> L4_7["ID: afa887ea
ip-26-0-168-120
p5.48xlarge"]:::level4
L3_5 --> L4_8["ID: 66c12e70
ip-26-0-167-177
p5.48xlarge"]:::level4
%% 6th, 7th, 8th have 1 each
L3_6 --> L4_9["ID: 9412bdf3
ip-26-0-168-52
p5.48xlarge"]:::level4
L3_7 --> L4_10["ID: 87bd4dc8
ip-26-0-167-111
p5.48xlarge"]:::level4
L3_8 --> L4_11["ID: b001549b
ip-26-0-166-244
p5.48xlarge"]:::level4
%% 9th has 2
L3_9 --> L4_12["ID: 10ed8172
ip-26-0-107-245
p5.48xlarge"]:::level4
L3_9 --> L4_13["ID: 7c1d0a09
ip-26-0-168-238
p5.48xlarge"]:::level4
%% 10th, 11th, 12th have 1 each
L3_10 --> L4_14["ID: 925ce932
ip-26-0-167-217
p5.48xlarge"]:::level4
L3_11 --> L4_15["ID: c9bc34db
ip-26-0-171-168
p5.48xlarge"]:::level4
L3_12 --> L4_16["ID: 328d5d04
ip-26-0-167-127
p5.48xlarge"]:::level4
%% Styles
classDef level1 fill:#c8e6c9
classDef level2 fill:#e1f5fe
classDef level3 fill:#fff9c4
classDef level4 fill:#ffcdd2 尽量减少通信节点之间的网络跳数,会直接转化为更好的互连性能。对于小规模实验和消融测试来说,确保实例被放置在同一个网络 switch 下,往往会在延迟和带宽利用率上带来可观且可测的提升。
正确的环境变量
网络适配器所需的环境变量如果缺失或设置错误,会严重限制带宽利用率。像 NCCL 这样的通信库依赖特定配置 flags 来启用最优性能特性,例如自适应路由、GPU 发起传输,以及合适的 buffer sizing。
例如,在使用 AWS EFA(Elastic Fabric Adapter)时,一定要确认你已经为对应实例类型设置了推荐的 NCCL 与 EFA 环境变量。AWS EFA cheatsheet 提供了针对不同场景的完整 flag 配置建议。
容器相关注意事项
当你使用容器(Docker/Enroot)时,有几个配置步骤对 NCCL 性能至关重要:
- Shared 和 Pinned Memory:Docker 容器默认可用的 shared memory 和 pinned memory 资源有限。启动容器时应加上
-shm-size=1g --ulimit memlock=-1,以避免初始化失败。 - NUMA 支持:Docker 默认会禁用 NUMA 支持,这可能导致 cuMem host allocations 无法正常工作。可以通过
-cap-add SYS_NICE启动 Docker,以启用 NUMA 支持。 - PCI 拓扑发现:确保
/sys被正确挂载,这样 NCCL 才能识别 GPU 与网卡的 PCI 拓扑。如果/sys暴露的是虚拟化后的 PCI 拓扑,可能会导致次优性能。
我们正在把这些排障经验整理成一个社区共同维护的知识库。如果你也遇到过性能问题,或者找到了有效的调试方法,欢迎到 Discussion Tab 分享你的经验,帮助其他人更好地优化互连利用率。
既然你已经知道如何排查 GPU-CPU 和 GPU-GPU 通信中的瓶颈,我们再来看一个通常更容易被忽略的通信环节:也就是 GPU 与存储层之间的通信。
GPU 到存储
GPU 与存储系统之间的连接常常被忽视,但它对训练效率的影响可能非常大。在训练过程中,GPU 需要持续从存储中读取数据(data loading,尤其是带有大图像/视频文件的多模态数据),还需要定期把模型状态写回存储(也就是 checkpointing)。在现代大规模训练任务中,如果这些 I/O 操作没有优化好,它们就可能成为瓶颈。
TL;DR: GPU-存储 I/O 会通过 data loading 和 checkpointing 直接影响训练。GPUDirect Storage(GDS)允许数据直接在 GPU 与存储之间传输,从而绕过 CPU、获得更好的性能。即使我们的集群当前没有启用 GDS,本地 NVMe RAID(8×3.5TB,RAID 0)也能提供 26.59 GiB/s 和 337K IOPS(比网络存储快 6.3 倍),因此非常适合存放 checkpoints。
理解存储拓扑
GPU 与存储设备之间的物理连接,其实也遵循着与 GPU 互连类似的层级结构。存储设备通过 PCIe bridges 接入系统,而理解这种拓扑结构,有助于解释性能特征以及潜在瓶颈。
从 lstopo 提供的系统拓扑中,我们可以看到 NVMe 硬盘是如何接入系统的。在我们的 p5 实例中,每张 GPU 对应 1 块 NVMe SSD:
PCIBridge L#13 (busid=0000:46:01.5 id=1d0f:0200 class=0604(PCIBridge) link=15.75GB/s buses=0000:[54-54] PCIVendor="Amazon.com, Inc.")
PCI L#11 (busid=0000:54:00.0 id=1d0f:cd01 class=0108(NVMExp) link=15.75GB/s PCISlot=87-1 PCIVendor="Amazon.com, Inc." PCIDevice="NVMe SSD Controller")
Block(Disk) L#9 (Size=3710937500 SectorSize=512 LinuxDeviceID=259:2 Model="Amazon EC2 NVMe Instance Storage" Revision=0 SerialNumber=AWS110C9F44F9A530351) "nvme1n1"
一个很自然的问题是:GPU 能否在不经过 CPU 的情况下直接访问 NVMe 硬盘?答案是可以,通过 GPUDirect Storage(GDS)。
GPUDirect Storage 是 NVIDIA GPUDirect 技术家族的一部分,它在存储(本地 NVMe 或远程 NVMe-oF)与 GPU 内存之间建立了一条直接数据通路。它允许存储控制器附近的 DMA engine 直接把数据搬进或搬出 GPU 内存,从而消除了通过 CPU bounce buffers 的不必要内存拷贝。这会降低 CPU 开销、减少延迟,并显著提升大规模多模态数据训练这类数据密集型工作负载的 I/O 性能。
如果你想确认系统上的 GPUDirect Storage 是否配置正确,可以检查 GDS 的配置文件,并使用随附的诊断工具:
$ /usr/local/cuda/gds/tools/gdscheck.py -p
=====================
DRIVER CONFIGURATION:
=====================
NVMe : Supported
NVMeOF : Unsupported
SCSI : Unsupported
ScaleFlux CSD : Unsupported
NVMesh : Unsupported
DDN EXAScaler : Unsupported
IBM Spectrum Scale : Unsupported
NFS : Unsupported
BeeGFS : Unsupported
WekaFS : Unsupported
Userspace RDMA : Unsupported
--Mellanox PeerDirect : Enabled
--rdma library : Not Loaded (libcufile_rdma.so)
--rdma devices : Not configured
--rdma_device_status : Up: 0 Down: 0
=====================
这里可以看到 NVMe: Supported,说明 GDS 当前已经被配置为支持 NVMe 硬盘;其他存储类型则都显示为 Unsupported,说明还没有正确配置。如果你的目标存储类型尚未正确配置 GDS,可以参考 NVIDIA GPUDirect Storage Configuration Guide,修改 /etc/cufile.json 中的相关配置。
块存储设备
要了解系统中有哪些可用存储设备,可以使用 lsblk 来查看块设备层级:
$ lsblk --fs -M
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
...
nvme0n1
└─nvme0n1p1 ext4 cloudimg-rootfs 24ec7991-cb5c-4fab-99e5-52c45690ba30 189.7G 35% /
┌┈▶ nvme1n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
├┈▶ nvme2n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
├┈▶ nvme3n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
├┈▶ nvme8n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
├┈▶ nvme5n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
├┈▶ nvme4n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
├┈▶ nvme6n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
└┬▶ nvme7n1 linux_raid_member ip-26-0-164-236:MY_RAID d0795631-71f0-37e5-133b-e748befec126
└┈┈md0 xfs dddb6849-e5b5-4828-9034-96da65da27f0 27.5T 1% /scratch
这段输出展示了系统中的块设备层级结构。关键信息包括:
nvme0n1p1是根 Amazon EBS 文件系统,挂载在/,总容量约 300GB,目前用了 35%- 8 块 NVMe 硬盘(
nvme1n1到nvme8n1)被配置成一个名为MY_RAID的 RAID 阵列 - 这个 RAID 阵列以
/dev/md0的形式暴露出来,使用 XFS 格式化,并挂载在/scratch,可用容量为 28TB(8×3.5TB)
箭头(┈▶)表示多个 NVMe 设备都是同一个 RAID 阵列的成员,最终汇总成单个 md0 设备。
网络存储
除了本地 NVMe 存储之外,系统还可以访问网络挂载的存储系统:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 291G 101G 190G 35% /
weka-hopper.hpc.internal.huggingface.tech/default 393T 263T 131T 67% /fsx
10.53.83.155@tcp:/fg7ntbev 4.5T 2.9T 1.7T 63% /admin
/dev/md0 28T 206G 28T 1% /scratch
这段输出表明:
/dev/root(291GB Amazon EBS)是根文件系统,目前使用了 35%/fsx(393TB WekaFS)已使用 67%,还剩 131TB/admin(4.5TB FSx Lustre)已使用 63%,还剩 1.7TB/dev/md0(28TB 本地 NVMe RAID)只用了 1%,挂载在/scratch,还剩 28TB。这就是我们的 8×3.5TB SSD NVMe instance store drives 组成的 RAID。
本地 NVMe RAID 阵列(/scratch)提供了最快的 I/O 性能,而网络文件系统则提供了更大的共享存储容量。
RAID(Redundant Array of Independent Disks):通过数据条带化、校验或镜像等方式,把多块硬盘组合起来,以提升性能和/或可靠性。
NVMe(Non-Volatile Memory Express):一种面向 SSD 的高性能存储协议,直接连接到 PCIe,因此相比 SATA/SAS 能提供更高吞吐和更低延迟。
WekaFS:一种面向 AI/ML 工作负载设计的高性能并行文件系统,能够在多节点之间提供低延迟访问和高吞吐。
FSx Lustre:一种面向 HPC 的并行文件系统,它把 metadata 和 data 服务分布在不同服务器上,以支持并行访问。虽然它对大文件很有效,但在涉及大量小文件、metadata 压力很大的 AI/ML 工作负载中可能会表现不佳。
存储带宽基准测试
为了理解不同存储系统的性能特征,我们可以使用 GPUDirect Storage(GDS)对它们的读写速度进行 benchmark。下面是一个可测试多种配置的参数化 benchmark 脚本:
gdsio -f /<disk_path>/gds_test.dat -d 0 -w <n_threads> -s 10G -i <io_size> -x 1 -I 1 -T 10
这个 benchmark 除了评估 Throughput、Latency、IOPS 之外,还能帮助我们理解:
可扩展性:不同线程数和 I/O 大小时性能如何变化。这可以帮助我们找出不同工作负载模式下的最优配置:
- 小 I/O(64K 到 256K)通常能最大化 IOPS,但未必能打满带宽
- 大 I/O(2M 到 8M)通常能最大化吞吐,但会降低 IOPS
- 线程数会同时影响两者:更多线程可以在达到硬件上限之前提升总 IOPS 和总吞吐
传输方式效率:比较 GPU_DIRECT、CPU_GPU 和 CPUONLY,可以看出绕过 CPU 内存到底能带来多少收益:
- GPU_DIRECT:使用 RDMA 直接把数据传进 GPU 内存,完全绕过 CPU(延迟最低、效率最高、小操作下 IOPS 最佳)
- CPU_GPU:传统路径,数据先进入 CPU 内存,再复制到 GPU(会增加 CPU 开销并争用内存带宽,从而降低有效 IOPS)
- CPUONLY:不涉及 GPU 的纯 CPU I/O 基线
IOPS 指的是每秒完成的独立 I/O 操作次数。
它可通过 gdsio 输出中的 ops / total_time 计算得到。IOPS 在以下场景中特别重要:
- 小 I/O 尺寸下的随机访问模式
- 包含大量小文件或离散数据访问的工作负载
- 类似数据库的场景,在这种场景下,单次操作延迟比原始带宽更重要
- 更高的 IOPS 表示系统更擅长处理并发的、细粒度的数据访问
benchmark 揭示了我们四套存储系统之间巨大的性能差异:
/scratch(本地 NVMe RAID) 遥遥领先,吞吐达到 26.59 GiB/s,IOPS 达到 337K,吞吐比 FSx 快 6.3 倍,IOPS 也高出 6.6 倍。这个由 8×3.5TB NVMe 组成的本地 RAID 阵列,提供了最低延迟(峰值 IOPS 下为 190μs),并且随着线程数增加扩展得非常好;在吞吐上,它在 64 线程、1M I/O 尺寸下达到峰值。
/fsx(WekaFS) 提供了相当不错的网络存储性能,达到 4.21 GiB/s 和 51K IOPS,因此它是需要共享、同时又要求一定性能的数据的最佳选择。FSx 在 CPUONLY 传输模式下实现了最佳吞吐(4.21 GiB/s),而其最高 IOPS(51K)则出现在 GPUD 传输模式下。
/admin(FSx Lustre) 和 /root(EBS) 文件系统在吞吐上都只有大约 1.1 GiB/s 的一般水平,但在 IOPS 能力上差别很大。Admin 在 GPUD 传输模式下达到了峰值吞吐(1.13 GiB/s),并在 CPU_GPU 传输模式下达到 17K IOPS(比 Root 高 24 倍),因此它更适合包含大量小操作的工作负载。Root 极差的 IOPS 表现(730)说明它只适合大块顺序访问。
关于 GPU_DIRECT 结果的说明: 我们当前集群里并没有启用 GPUDirect Storage(GDS),这也解释了为什么 NVMe 存储(Scratch 和 Root)上的 GPUD 结果会比 CPUONLY 传输更差。如果 GDS 被正确配置,我们预期 GPUD 在 GPU 到存储的直接传输中会表现出明显优势,尤其是在高性能 NVMe 阵列上。
最优配置模式:在所有存储类型中,最大吞吐都出现在 1M 的 I/O 尺寸下,而最大 IOPS 则都出现在最小测试尺寸(64K)下。这种经典权衡意味着:你需要根据工作负载特点,在原始带宽(大 I/O)和操作并发性(小 I/O)之间做选择。对于包含大 checkpoint 文件的 ML 训练来说,Scratch 上的 1M-8M 区间会提供最佳性能。
小结
如果你已经读到这里,恭喜你。你现在已经对存储层级以及不同组件在训练基础设施中的交互方式有了完整理解。但我们最希望你带走的核心洞察是: 真正把理论知识和实际优化区分开的,是对瓶颈的识别能力。
在这一整节中,我们测量了整个栈上各层级的真实带宽:单块 GPU 内部 HBM3 的 3TB/s、节点内 GPU 间 NVLink 的 786 GB/s、CPU-GPU 之间 PCIe Gen4 x8 的 14.2 GB/s、节点间网络点对点通信的 42 GB/s,以及从 26.59 GB/s(本地 NVMe)到 1.1 GB/s(共享文件系统)不等的存储系统性能。这些测量揭示了训练流水线会在哪里变慢,也是实现高 Model FLOPs Utilization(MFU)的关键。
不过,原始带宽数字本身并不能讲完整个故事。现代训练系统可以 把计算和通信重叠起来,从而把通信成本隐藏在计算背后。即便互连较慢,这种并行化方式也能缓解瓶颈。关于如何通过重叠计算与通信来最大化吞吐,可以参考 Ultra-Scale Playbook。
下图把我们所有 benchmark 得到的测量结果综合到了一张视图中,展示了带宽如何随着离 GPU 越来越远而急剧下降:
既然我们已经知道如何识别硬件和软件环境中的瓶颈,接下来就再往前走一步,看看怎样构建一个足够有韧性的系统,让它可以稳定运行数月。
构建具备韧性的训练系统
拥有快速硬件,只是构建稳定优质 LLM 训练基础设施的入场券。要从训练新手走向专业实践,我们必须超越“原始速度”本身,把注意力放到那些不那么光鲜、但极其关键的基础设施组件上。正是它们决定了整个训练过程能否更顺畅、停机时间更低。
在这一节中,我们会把重点从硬件和软件优化,转向 production readiness:构建一个足够 robust、能扛住不可避免故障;足够 automated、无需时刻盯着;也足够 flexible、在出问题时还能快速适应的系统。
节点健康监控与替换
训练时,拥有足够多且足够快的 GPU 当然重要;但由于 LLM 训练往往持续数周甚至数月,而不是只有几天,因此长期追踪 GPU 健康状况就变得极其关键。即便某些 GPU 一开始通过了 benchmark,它们在长时间训练中也可能出现 thermal throttling、memory errors 或性能退化。在这一节里,我们会分享自己是如何应对这一问题的,以及所使用的工具。
前置测试: 在启动 SmolLM3 之前,我们使用多种工具对 GPU 做了全面诊断。我们使用了 GPU Fryer,这是一个内部工具,用来对 GPU 做压力测试,以发现 thermal throttling、memory errors 和性能异常。我们还运行了 NVIDIA 的 DCGM diagnostics,这是一个广泛使用的工具,可用于验证 GPU 硬件、监控性能,并通过覆盖 compute、PCIe 连通性、内存完整性和热稳定性的深度诊断测试,找出故障或供电异常的根因。这些前置测试帮我们提前发现了两块有问题的 GPU,否则它们会在训练中造成麻烦。
下表展示了 DCGM 诊断工具可以覆盖哪些测试内容:
| Test Level | Duration | Software | PCIe + NVLink | GPU Memory | Memory Bandwidth | Diagnostics | Targeted Stress | Targeted Power | NVBandwidth | Memory Stress | Input EDPp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| r1 (Short) | Seconds | ✓ | ✓ | ✓ | |||||||
| r2 (Medium) | < 2 mins | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| r3 (Long) | < 30 mins | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| r4 (Extra Long) | 1-2 hours | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
DCGM 诊断运行级别。来源: NVIDIA DCGM Documentation
$ dcgmi diag -r 2 -v -d VERB
Successfully ran diagnostic for group.
+---------------------------+------------------------------------------------+
| Diagnostic | Result |
+===========================+================================================+
| ----- Metadata ----------+------------------------------------------------ |
| DCGM Version | 3.3.1 |
| Driver Version Detected | 575.57.08 |
| GPU Device IDs Detected | 2330,2330,2330,2330,2330,2330,2330,2330 |
| ----- Deployment --------+------------------------------------------------ |
| Denylist | Pass |
| NVML Library | Pass |
| CUDA Main Library | Pass |
| Permissions and OS Blocks | Pass |
| Persistence Mode | Pass |
| Environment Variables | Pass |
| Page Retirement/Row Remap | Pass |
| Graphics Processes | Pass |
| Inforom | Pass |
+----- Integration -------+------------------------------------------------+
| PCIe | Pass - All |
| Info | GPU 0 GPU to Host bandwidth: 14.26 GB/s, GPU |
| 0 Host to GPU bandwidth: 8.66 GB/s, GPU 0 b |
| idirectional bandwidth: 10.91 GB/s, GPU 0 GPU |
| to Host latency: 2.085 us, GPU 0 Host to GP |
| U latency: 2.484 us, GPU 0 bidirectional lat |
| ency: 3.813 us |
...
+----- Hardware ----------+------------------------------------------------+
| GPU Memory | Pass - All |
| Info | GPU 0 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 1 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 2 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 3 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 4 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 5 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 6 Allocated 83892938283 bytes (98.4%) |
| Info | GPU 7 Allocated 83892938283 bytes (98.4%) |
+----- Stress ------------+------------------------------------------------+
节点预留: 因为 SmolLM3 是在一个由 Slurm 管理的集群上训练的,所以我们为整个训练过程预定了固定的 48 个节点。这种做法让我们能够长期跟踪同一批节点的健康状况和性能表现,同时它也有助于解决前面提到的数据存储问题。我们还额外预留了一个备用节点(就像汽车里的备胎),这样一旦某个节点故障,就可以立刻顶上,而不用等待修复。空闲时,这个备用节点会跑 eval 作业或开发实验。
持续监控: 在训练期间,我们持续跟踪所有节点上的关键指标,例如 GPU 温度、内存使用量、计算利用率,以及吞吐波动。我们使用 Prometheus 收集全部 GPU 的 DCGM 指标,再通过 Grafana 仪表盘进行实时可视化监控。如果你想了解如何在 AWS 基础设施上部署用于 GPU 监控的 Prometheus 和 Grafana,可以参考这个示例部署指南。此外,我们还配了一个 Slack bot,一旦某个节点出现可疑行为,它就会提醒我们,从而能在硬件彻底拖垮整次训练之前,主动把故障节点替换掉。
查看仪表盘 这种多层次的方案让硬件问题从“致命故障”,变成了“可管理的中断”。
热现实检查:GPU 什么时候会变慢
营销规格默认假设散热是完美的,但现实远没有这么理想。当 GPU 过热时,它会自动降低时钟频率,即使在设计良好的系统里,性能也会因此低于理论最大值。
我们通过 NVIDIA DCGM 中的 DCGM_FI_DEV_CLOCK_THROTTLE_REASONS 指标来检测 thermal throttling。当这个指标出现非零值时,就说明 GPU 正在因为过热而自动降频。上面的仪表盘展示了这类事件在实际中的表现方式。
thermal throttling 受害的不只是那一块 GPU,它会把影响扩散到整个分布式训练系统。在我们的测试中就观察到,单个发生降频的节点就足以显著拖垮 collective communication 的性能。
上图展示了 AllReduce 带宽在我们从 1 个节点扩展到 16 个节点时如何退化。注意 14 个节点之后出现的剧烈下降:从 350 GB/s 掉到 100 GB/s,而按我们前面的测量,本来应该保持在 300GB/s 以上。这并不是网络问题,而是单个发生 thermal throttling 的节点成了瓶颈,迫使其他所有节点在梯度同步时等待它。在分布式训练里,你的速度永远不会快过最慢的那个节点。
👉 关键教训: 在投入长时间训练之前,一定要用前面提到的工具对硬件做压力测试,以发现热和供电限制。训练过程中也要持续通过 DCGM telemetry 监控温度,并针对真实的热约束来做规划。同时,确认 GPU 时钟已经设在最高性能模式,也是一个值得养成的好习惯。如果你想更深入理解为什么 GPU 无法长期维持宣传中的性能峰值,可以看看这篇关于 power throttling 的优秀分析。
Checkpoint 管理
checkpoint 是长时间训练中的安全网。我们定期保存它们,主要出于三个现实原因:故障恢复、通过评测监控训练进展,以及把中间模型分享给社区做研究。其中最重要的是恢复能力。如果训练失败,我们希望能从最近一次保存的 checkpoint 继续启动,这样只要能立即恢复,损失最多也就是一个保存周期(例如每 4 小时保存一次,那最多损失 4 小时训练)。
尽量把 resume 过程自动化。比如在 Slurm 中,你可以直接使用 SBATCH --requeue,让作业自动从最新 checkpoint 重新启动。这样就不会因为等待某个人发现故障并手动重启而白白浪费时间。
在实现 resume 机制时,有两个非常重要的细节需要注意:
- checkpoint 保存应在后台进行,不能影响训练吞吐。
- 要盯紧存储容量。一个持续 24 天的训练,如果每 4 小时保存一次,就意味着大约有 ~144 个 checkpoints。对大模型和优化器状态来说,这很快就会堆满存储。我们在实践中一次只保留一个本地 checkpoint(最新的那个),其他都转存到 S3,以免集群存储被占满。
一次惨痛的历史教训:
在我们第一次大规模训练(StarCoder 15B)时,训练经过多次重启都很顺利。直到最后一天,我们才发现整个 checkpoint 文件夹被删掉了,原因是脚本末尾还残留着一个来自早期吞吐测试的 rm -rf $CHECKPOINT_PATH 命令。这个破坏性命令只有在 Slurm 作业真正“跑完”时才会触发,而之前那些中途重启的情况都没有走到这一步。
幸运的是,我们还保留着前一天的 checkpoint,所以最终只损失了 1 天的重训时间。这次经历的教训非常明确:生产脚本里绝不能残留破坏性命令;而且 checkpoint 备份必须在保存后立刻自动完成,而不能依赖人工操作。
在我们的 nanotron 训练中,checkpoint 每 2 小时先保存到本地,然后立刻上传到 S3,等确认备份成功后再删除本地副本。恢复时,如果本地没有最新 checkpoint,就从 S3 拉取。这种做法能节省存储、确保备份可靠,并且支持快速恢复。
自动化评测
手动跑评测很快就会变成瓶颈。它们看上去很简单,直到你不得不反复做很多遍。每次都去跑 benchmark、跟踪结果、画图,累积起来会形成相当大的额外开销。解决方案是什么?一开始就全部自动化。
在 SmolLM3 上,我们使用 LightEval 对 nanotron checkpoints 做评测。每次保存 checkpoint,都会自动触发一个集群上的 evaluation job。结果会直接推送到 Weights & Biases 或 Trackio,这样我们只需要打开仪表盘,看曲线如何演化即可。这帮我们节省了大量时间,也让整个训练过程中的 eval tracking 始终保持一致。
如果你的训练系统里只能自动化一件事,那就优先自动化评测。
最后,我们再来看一下怎样优化训练布局,也就是:如何把模型分布到可用 GPU 上,以最大化吞吐。
优化训练吞吐
我们到底需要多少张 GPU?
这是个很好的问题。说了这么多规格和 benchmark,最后你还是得回答一个最现实的问题:到底应该租多少张 GPU,或者买多少张 GPU?
决定 GPU 数量,本质上是在训练时间、成本和扩展效率之间做平衡。下面是我们使用的框架:
基础估算公式:
这个公式把问题拆成了三个关键组成部分:
- Total FLOPs Required:训练模型所需的总计算量(取决于模型规模、训练 tokens 和模型架构)
- Per-GPU Throughput:每张 GPU 实际每秒能提供多少 FLOPs(不是理论峰值!)
- Target Training Time:你愿意等待训练完成的时间长度
关键洞察在于:你需要估计的是 现实可达的吞吐,而不是规格表上的峰值。这意味着你必须考虑 Model FLOPs Utilization(MFU),也就是实践中你实际达到的理论峰值性能比例。
对于 SmolLM3,我们的估算方式如下:
- 模型规模:30 亿参数
- 训练 tokens:11 万亿
- 目标训练时长:约 4 周
- 预期 MFU:30%(基于类似规模实验的经验)
首先,我们使用标准 transformer 近似公式 每个 token 需要 6N FLOPs(其中 N 为参数量)来计算总 FLOPs:
在预期 MFU 为 30% 的情况下,每张 GPU 的有效吞吐变成:
把这些代入估算公式:
这个计算结果把我们引向了 375 到 400 张 H100 的区间,最终我们拿到了 384 张 H100。这个数字既和我们的并行策略很好地匹配,也能让 4 周时间线变得现实,并且还留出了一些 buffer,来应对节点故障、训练重启等意外情况。
为什么 GPU 越多不一定越好:Amdahl 定律的现实表现
这里有一个反直觉的事实: 增加更多 GPU,反而可能让训练更慢。这正是 Amdahl’s Law 发挥作用的地方。
Amdahl 定律指出:并行化带来的加速,从根本上受限于工作负载中那部分串行(无法并行化)的内容。在 LLM 训练中,这部分“串行”主要就是 通信开销:也就是在 GPU 之间同步 gradients、weights 和 activations 所花的时间,而这些开销无法被简单并行化掉(可参考这里)。
它的公式是: Maximum Speedup = 1 / (Serial Fraction + Parallel Fraction / Number of Processors)
对于 SmolLM3 的 3B 模型,如果每个训练 step 中有 10% 时间都花在通信上,那么不管你加多少 GPU,加速比都永远不可能超过 10 倍。更糟的是,随着 GPU 数量增加,通信占比往往还会 继续上升,因为:
- 更多 GPU = 更多 AllReduce 参与者 = 更长的同步时间
- 网络延迟/带宽会变成瓶颈
- 小模型无法用足够的计算把通信隐藏起来
在 SmolLM3 上,我们采用了 weak scaling 思路:global batch size 随 GPU 数量一起扩展,让整体保持大约每张 GPU 对应 8K tokens。这样既能保持通信与计算的比例合理,又能最大化吞吐。
寻找最优并行配置
一旦 GPU 资源到位,接下来的挑战就是:怎样把它们配置成真正高效训练的系统。这里并行策略就变得至关重要。
我们遵循 Ultra-Scale Playbook 中关于寻找最优训练配置的方法。这个 playbook 把问题拆成三个连续步骤:先确保模型能塞进内存,再达到目标 batch size,最后优化到最大吞吐。下面我们就以 SmolLM3 为例,看看我们是如何应用这一方法的。
第一步:让一个训练 step 能装进内存
第一个问题很简单:我们的 SmolLM3 3B 模型,真的能装进单张 H100 的 80GB 显存里吗?为了回答这个问题,我们使用了 nanotron 的 predict_memory 工具,它可以估算模型参数、优化器状态、梯度以及激活值所占用的内存。
结果显示,我们已经非常接近 80GB 上限了。这意味着我们必须使用某种能降低单 GPU 显存占用的并行方式,无论是 Tensor Parallelism(把模型层分到多张 GPU 上)、Pipeline Parallelism(按模型深度切分到多张 GPU 上),还是 ZeRO 优化器切分(把优化器状态分布出去)。如果没有这些策略中的至少一种,我们要么根本训不起来,要么效率会非常差。
第二步:达到目标 global batch size
既然我们已经知道,借助某种并行方式模型是可以装进内存的,接下来就需要确定如何达到目标 global batch size(GBS),也就是约 200 万 tokens。这个约束给出了我们的第一个方程:
其中:
- DP(Data Parallelism):数据并行副本数量
- MBS(Micro Batch Size):每张 GPU、每个 micro-batch 处理的 tokens 数
- GRAD_ACC(Gradient Accumulation):在执行 optimizer step 之前累计多少次 forward-backward
- SEQLEN(Sequence Length):每个序列的 token 长度(预训练第一阶段使用 4096)
我们还受到 384 张 H100 的硬件约束:
其中:
- TP(Tensor Parallelism):每层模型使用多少张 GPU(切分权重矩阵)
- PP(Pipeline Parallelism):按模型深度把层垂直切分到多少张 GPU 上
这两个方程一起定义了我们的搜索空间。我们需要找到一组同时满足这两个约束、并且能最大化训练吞吐的取值。
第三步:优化训练吞吐
在这些约束明确之后,我们就要从中找出能最大化训练吞吐的并行配置。搜索空间由硬件拓扑和模型架构共同决定。
正如前面看到的,我们的硬件环境里存在两类截然不同的互连:节点内通信使用 NVLink(900 GB/s),节点间通信使用 EFA(~50 GB/s)。这种拓扑天然意味着,我们至少应该使用两类并行策略,来匹配这两种网络特性。互连之间巨大的带宽差异,会强烈影响哪种并行策略最有效。
从模型角度来看,SmolLM3 的架构也限制了我们的选择。由于它不是 Mixture-of-Experts 架构,所以我们不需要 Expert Parallelism。同样,由于第一阶段训练时 sequence length 只有 4096,也不需要 Context Parallelism。因此,真正需要探索的并行维度只剩下三个: Data Parallelism(DP)、 Tensor Parallelism(TP)和 Pipeline Parallelism(PP)。
基于第二步的约束,我们需要扫描以下几个参数:
- 带不同 ZeRO 变体的 DP(ZeRO-0、ZeRO-1、ZeRO-3):取值从 1 到 384,且必须满足 2 和/或 3 的倍数约束
- TP(1、2、3、4、6、8):尽量限制在单节点内,以充分利用 NVLink 的高带宽
- PP(1..48):沿模型深度切分到多张 GPU 上
- MBS(2、3、4、5):根据并行策略节省下来的内存情况,我们可以增大 MBS,从而更好利用 Tensor Cores
- Activation checkpointing(none、selective、full):用额外计算换取更少的内存占用与更低的通信压力
- Kernel 优化:在可用时启用 CUDA graphs 与优化过的 kernels
虽然这些组合看起来很多,但一种务实做法是:先分别 benchmark 每个维度,再把明显会拖垮吞吐的配置排除掉。这里的关键洞察在于,并不是所有并行策略都同样有效。有些策略引入的通信开销,远远超过了它们带来的好处,尤其是在我们这个规模下。
在我们的实验中, Pipeline Parallelism 表现很差。PP 需要频繁进行跨节点的 pipeline bubble 同步,而对于相对较小的 3B 模型来说,通信开销完全压过了可能带来的任何收益。此外,我们当时也没有足够高效的 PP schedule,无法把 pipeline bubble 基本消掉,这进一步限制了 PP 的可行性。类似地, ZeRO 在 0 以上的级别会引入大量 all-gather 和 reduce-scatter 操作,它们对吞吐的伤害大于对显存节省的帮助。这些早期 benchmark 让我们大幅缩小了搜索空间,最后把注意力集中到 Data Parallelism 配合适度 Tensor Parallelism 的配置上。
👉 为了评估每一种配置,我们会跑 5 个 iteration 的 benchmark,并记录 tokens per second per GPU(tok/s/gpu),因为这才是我们最终真正关心的指标。我们使用 Weights & Biases 和 Trackio 来记录吞吐和配置,从而方便地比较不同的并行策略。
在系统性 benchmark 了 nanotron 里可用的选项之后,我们最终选择了 DP = 192,让数据并行梯度同步走跨节点的 EFA 带宽。也就是说,系统中有 192 个独立模型副本,每个处理不同的数据 batch。对于 Tensor Parallelism,我们选择了 TP = 2,把 tensor-parallel 通信控制在单节点内,以充分利用 NVLink 的高带宽。这意味着每层的权重矩阵会被切分到两张 GPU 上,forward 和 backward 时都需要高速通信。
我们的 Micro Batch Size = 3,在内存使用和计算效率之间做了平衡。更大的 batch size 确实能更好地利用 Tensor Cores,但我们已经很接近显存上限了。最后,我们选择了 ZeRO-0,也就是不做优化器状态切分。虽然 ZeRO-1 或 ZeRO-3 可以降低显存占用,但在 384 张 GPU 之间 gather 和 scatter 优化器状态所带来的通信开销,会严重伤害吞吐。
这个配置在最大化 384 张 H100 集群吞吐的同时,也达到了我们约 200 万 tokens 的目标 global batch size(192 × 3 × 1 × 4096 ≈ 2.3M)。完整训练配置可以在我们的 stage1_8T.yaml 中查看。
结语
这段旅程始于一个简单的问题:在 2025 年,训练一个高性能 LLM,到底需要什么?从预训练到后训练,我们一路走完整条流水线,想展示给你的不只是具体技巧,更是让这些技巧真正发挥作用的方法论。
大规模预训练。 我们介绍了如何用 Training Compass 框架来判断“究竟该不该训”,以及如何把目标翻译成具体的架构决策。你已经看到,怎样搭建可靠的消融实验流程、如何一次只测试一个变化,以及如何把几亿到几十亿 token 级别的实验,逐步扩展到多万亿 token 级别的训练。我们也记录了在大规模环境下会遇到的各种基础设施挑战(吞吐崩塌、dataloader 瓶颈、隐蔽 bug),以及监控和系统化降风险策略如何帮助你更早发现问题、更快完成调试。
实践中的后训练。 我们展示了,从一个 base model 走向可生产使用的 assistant,需要另一套同样系统化的方法:先建立评测,再去训练;迭代 SFT 数据配比;应用偏好优化;有需要的话,再继续往 RL 推进。你已经看到,vibe testing 如何抓住那些评测指标看不到的 bug,chat template 又如何在不知不觉中破坏 instruction-following,以及为什么数据混合的平衡在后训练中和在预训练中一样重要。
贯穿这两个阶段,我们不断回到同样的核心原则:一切都要通过实验验证;一次只改一个变量;要预期规模变大时会以新的方式把问题暴露出来;而且应当让你的 use case 来驱动决策,而不是追着每一篇新论文跑。沿着这套过程,我们训练出了 SmolLM3:一个具备长上下文能力、具有竞争力的 3B 多语言推理模型。在这个过程中,我们学到了很多关于什么有效、什么会坏、以及当问题出现时该如何调试的经验。我们也尽量把这些都记录下来,无论是成功,还是失败。
接下来呢?
这篇博客覆盖了现代 LLM 训练的核心基础,但这个领域变化极快。如果你想继续深入,可以从下面几个方向出发:
- 自己动手做实验。 阅读消融实验当然有帮助,但亲自跑一遍,才能真正知道什么重要。选一个小模型,搭好 eval,然后开始试验。
- 阅读源码。 nanotron、TRL 等训练框架都是开源的。理解它们的实现细节,往往能看到论文里一笔带过、却真正影响结果的关键之处。
- 关注最新工作。 最新 SOTA 模型的论文,能直接反映这个领域正在走向哪里。参考文献部分整理了我们认为最有影响力的一批论文和资源。
我们希望这篇博客能帮助你以更清晰的思路、更有把握的方式去面对下一个训练项目,无论你是在大型实验室推动前沿,还是在一个小团队里解决具体问题。
现在,去训练点什么吧。等到某天凌晨两点,你的 loss 突然莫名其妙地飙升时,记住:每个伟大的模型背后,都有一堆调试故事。愿开源与开放科学的原力始终与你同在。
致谢
感谢 Guilherme、Hugo 和 Mario 提供的宝贵反馈,也感谢 Abubakar 在 Trackio 功能方面提供的帮助。
参考资料
下面是一份我们在 LLM 训练之路上最受启发的论文、书籍和博客文章精选清单。
LLM 架构
- Dense models: Llama3, Olmo2, MobileLLM
- MoEs: DeepSeek V2, DeepSeek V3, Scaling Laws of Efficient MoEs
- Hybrid: MiniMax-01, Mamba2
优化器与训练参数
- Muon is Scalable for LLM Training, Fantastic pretraining optimisers
- Large Batch Training, DeepSeekLLM
数据整理
- Web: FineWeb & FineWeb-Edu, FineWeb2, DCLM
- Code: The Stack v2, To Code or Not to Code
- Math: DeepSeekMath, FineMath, MegaMath
- Data mixtures: SmolLM2, Does your data spark joy
Scaling laws
后训练
- InstructGPT: OpenAI 用来把 base model 变成有帮助 assistant 的奠基性论文。它既是 ChatGPT 的前身,也是人类朝 Kardashev 等级迈进过程中的一个关键节点。
- Llama 2 & 3: Meta 关于 Llama 模型训练过程的超详细技术报告(愿其安息)。其中都包含了大量关于人类数据收集的洞察,既包括偏好数据,也包括模型评测数据。
- Secrets of RLHF in LLMs, Part I & II: 这两篇论文包含了大量 RLHF 实践层面的关键细节,尤其是如何训练强 reward models。
- Direct Preference Optimisation: 2023 年的突破性论文,它说服了几乎所有人停止在 LLM 上继续用传统 RL。
- DeepSeek-R1: 2025 年的突破性论文,它又说服了几乎所有人重新开始在 LLM 上做 RL。
- Dr. GRPO: 这是理解 GRPO 内建偏差及其修复方法的最重要论文之一。
- DAPO: Bytedance 分享了大量实现细节,帮助社区解锁稳定的 R1-Zero 风格训练。
- ScaleRL: Meta 的一次“秀肌肉”之作,用超过 40 万 GPU 小时为 RL 推导 scaling laws,并建立了一套能跨多个数量级稳定扩展的训练 recipe。
- LoRA without Regret: 一篇写得非常漂亮的博客,发现低秩 LoRA 上的 RL 可以匹配 full-finetuning(这是个相当出人意料的结果)。
- Command A: Cohere 关于如何高效进行 LLM 后训练的技术报告,细节非常丰富。
基础设施
训练框架
评测
Footnotes
-
The idea to compute these statistics comes from the Llama 3 tech report (Grattafiori et al., 2024).
-
For vLLM see: Reasoning parsers, Tool parsers. For SGLang, see: Reasoning parsers, Tool parsers
-
The Transformers team has recently added parsers for extract tool calling and reasoning outputs. If adopted by engines like vLLM, the compatibility criterion may become less important in the future.
- Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Ramos, S., Geist, M., & Bachem, O. (2024). On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes. https://arxiv.org/abs/2306.13649
- Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebrón, F., & Sanghai, S. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. https://arxiv.org/abs/2305.13245 back: 1, 2
- Allal, L. B., Lozhkov, A., Bakouch, E., Blázquez, G. M., Penedo, G., Tunstall, L., Marafioti, A., Kydlíček, H., Lajarín, A. P., Srivastav, V., Lochner, J., Fahlgren, C., Nguyen, X.-S., Fourrier, C., Burtenshaw, B., Larcher, H., Zhao, H., Zakka, C., Morlon, M., … Wolf, T. (2025). SmolLM2: When Smol Goes Big – Data-Centric Training of a Small Language Model. https://arxiv.org/abs/2502.02737 back: 1, 2, 3
- Almazrouei, E., Alobeidli, H., Alshamsi, A., Cappelli, A., Cojocaru, R., Debbah, M., Goffinet, É., Hesslow, D., Launay, J., Malartic, Q., Mazzotta, D., Noune, B., Pannier, B., & Penedo, G. (2023). The Falcon Series of Open Language Models. https://arxiv.org/abs/2311.16867
- An, C., Huang, F., Zhang, J., Gong, S., Qiu, X., Zhou, C., & Kong, L. (2024). Training-Free Long-Context Scaling of Large Language Models. https://arxiv.org/abs/2402.17463
- Aryabumi, V., Su, Y., Ma, R., Morisot, A., Zhang, I., Locatelli, A., Fadaee, M., Üstün, A., & Hooker, S. (2024). To Code, or Not To Code? Exploring Impact of Code in Pre-training. https://arxiv.org/abs/2408.10914
- Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., Hui, B., Ji, L., Li, M., Lin, J., Lin, R., Liu, D., Liu, G., Lu, C., Lu, K., … Zhu, T. (2023). Qwen Technical Report. https://arxiv.org/abs/2309.16609
- Barres, V., Dong, H., Ray, S., Si, X., & Narasimhan, K. (2025). τ2-Bench: Evaluating Conversational Agents in a Dual-Control Environment. https://arxiv.org/abs/2506.07982
- Beck, M., Pöppel, K., Lippe, P., & Hochreiter, S. (2025). Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels. https://arxiv.org/abs/2503.14376
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
- Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., … Zaremba, W. (2021). Evaluating Large Language Models Trained on Code. https://arxiv.org/abs/2107.03374
- Chen, Y., Huang, B., Gao, Y., Wang, Z., Yang, J., & Ji, H. (2025a). Scaling Laws for Predicting Downstream Performance in LLMs. https://arxiv.org/abs/2410.08527
- Chen, Y., Huang, B., Gao, Y., Wang, Z., Yang, J., & Ji, H. (2025b). Scaling Laws for Predicting Downstream Performance in LLMs. https://arxiv.org/abs/2410.08527
- Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv Preprint arXiv:1904.10509.
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., … Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. https://arxiv.org/abs/2204.02311 back: 1, 2, 3, 4
- Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q. V., Levine, S., & Ma, Y. (2025). SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training. https://arxiv.org/abs/2501.17161
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. https://arxiv.org/abs/2110.14168
- Cohere, T., :, Aakanksha, Ahmadian, A., Ahmed, M., Alammar, J., Alizadeh, M., Alnumay, Y., Althammer, S., Arkhangorodsky, A., Aryabumi, V., Aumiller, D., Avalos, R., Aviv, Z., Bae, S., Baji, S., Barbet, A., Bartolo, M., Bebensee, B., … Zhao, Z. (2025). Command A: An Enterprise-Ready Large Language Model. https://arxiv.org/abs/2504.00698
- Dagan, G., Synnaeve, G., & Rozière, B. (2024). Getting the most out of your tokenizer for pre-training and domain adaptation. https://arxiv.org/abs/2402.01035 back: 1, 2
- Dao, T., & Gu, A. (2024). Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. https://arxiv.org/abs/2405.21060 back: 1, 2
- DeepSeek-AI. (2025). DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention. DeepSeek. https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
- DeepSeek-AI, :, Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., Gao, H., Gao, K., Gao, W., Ge, R., Guan, K., Guo, D., Guo, J., … Zou, Y. (2024). DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. https://arxiv.org/abs/2401.02954 back: 1, 2
- DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., … Zhang, Z. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. https://arxiv.org/abs/2501.12948
- DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Luo, F., Hao, G., Chen, G., … Xie, Z. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. https://arxiv.org/abs/2405.04434 back: 1, 2
- DeepSeek-AI, Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., … Pan, Z. (2025). DeepSeek-V3 Technical Report. https://arxiv.org/abs/2412.19437
- Dehghani, M., Djolonga, J., Mustafa, B., Padlewski, P., Heek, J., Gilmer, J., Steiner, A., Caron, M., Geirhos, R., Alabdulmohsin, I., Jenatton, R., Beyer, L., Tschannen, M., Arnab, A., Wang, X., Riquelme, C., Minderer, M., Puigcerver, J., Evci, U., … Houlsby, N. (2023). Scaling Vision Transformers to 22 Billion Parameters. https://arxiv.org/abs/2302.05442
- Ding, H., Wang, Z., Paolini, G., Kumar, V., Deoras, A., Roth, D., & Soatto, S. (2024). Fewer Truncations Improve Language Modeling. https://arxiv.org/abs/2404.10830
- D’Oosterlinck, K., Xu, W., Develder, C., Demeester, T., Singh, A., Potts, C., Kiela, D., & Mehri, S. (2024). Anchored Preference Optimization and Contrastive Revisions: Addressing Underspecification in Alignment. https://arxiv.org/abs/2408.06266
- Du, Z., Zeng, A., Dong, Y., & Tang, J. (2025). Understanding Emergent Abilities of Language Models from the Loss Perspective. https://arxiv.org/abs/2403.15796
- Dubois, Y., Galambosi, B., Liang, P., & Hashimoto, T. B. (2025). Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators. https://arxiv.org/abs/2404.04475
- Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., & Kiela, D. (2024). KTO: Model Alignment as Prospect Theoretic Optimization. https://arxiv.org/abs/2402.01306
- Gandhi, K., Chakravarthy, A., Singh, A., Lile, N., & Goodman, N. D. (2025). Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs. https://arxiv.org/abs/2503.01307
- Gao, T., Wettig, A., Yen, H., & Chen, D. (2025). How to Train Long-Context Language Models (Effectively). https://arxiv.org/abs/2410.02660 back: 1, 2, 3
- Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., … Ma, Z. (2024). The Llama 3 Herd of Models. https://arxiv.org/abs/2407.21783 back: 1, 2, 3
- Gu, A., & Dao, T. (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. https://arxiv.org/abs/2312.00752
- Gu, Y., Tafjord, O., Kuehl, B., Haddad, D., Dodge, J., & Hajishirzi, H. (2025). OLMES: A Standard for Language Model Evaluations. https://arxiv.org/abs/2406.08446 back: 1, 2
- Guo, S., Zhang, B., Liu, T., Liu, T., Khalman, M., Llinares, F., Rame, A., Mesnard, T., Zhao, Y., Piot, B., Ferret, J., & Blondel, M. (2024). Direct Language Model Alignment from Online AI Feedback. https://arxiv.org/abs/2402.04792
- Hägele, A., Bakouch, E., Kosson, A., Allal, L. B., Werra, L. V., & Jaggi, M. (2024). Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations. https://arxiv.org/abs/2405.18392 back: 1, 2
- He, Y., Jin, D., Wang, C., Bi, C., Mandyam, K., Zhang, H., Zhu, C., Li, N., Xu, T., Lv, H., Bhosale, S., Zhu, C., Sankararaman, K. A., Helenowski, E., Kambadur, M., Tayade, A., Ma, H., Fang, H., & Wang, S. (2024). Multi-IF: Benchmarking LLMs on Multi-Turn and Multilingual Instructions Following. https://arxiv.org/abs/2410.15553
- Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., … Sifre, L. (2022). Training Compute-Optimal Large Language Models. https://arxiv.org/abs/2203.15556
- Hong, J., Lee, N., & Thorne, J. (2024). ORPO: Monolithic Preference Optimization without Reference Model. https://arxiv.org/abs/2403.07691
- Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. https://arxiv.org/abs/1801.06146
- Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y., & Ginsburg, B. (2024). RULER: What’s the Real Context Size of Your Long-Context Language Models? https://arxiv.org/abs/2404.06654 back: 1, 2
- Hu, S., Tu, Y., Han, X., He, C., Cui, G., Long, X., Zheng, Z., Fang, Y., Huang, Y., Zhao, W., Zhang, X., Thai, Z. L., Zhang, K., Wang, C., Yao, Y., Zhao, C., Zhou, J., Cai, J., Zhai, Z., … Sun, M. (2024). MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies. https://arxiv.org/abs/2404.06395
- Huang, S., Noukhovitch, M., Hosseini, A., Rasul, K., Wang, W., & Tunstall, L. (2024). The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization. https://arxiv.org/abs/2403.17031
- IBM Research. (2025). IBM Granite 4.0: Hyper-efficient, High Performance Hybrid Models for Enterprise. https://www.ibm.com/new/announcements/ibm-granite-4-0-hyper-efficient-high-performance-hybrid-models
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., & Sayed, W. E. (2023). Mistral 7B. https://arxiv.org/abs/2310.06825
- Kamradt, G. (2023). Needle In A Haystack - pressure testing LLMs. In GitHub repository. GitHub. https://github.com/gkamradt/LLMTest_NeedleInAHaystack back: 1, 2
- Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling Laws for Neural Language Models. https://arxiv.org/abs/2001.08361
- Katsch, T. (2024). GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling. https://arxiv.org/abs/2311.01927
- Kazemnejad, A., Padhi, I., Ramamurthy, K. N., Das, P., & Reddy, S. (2023). The Impact of Positional Encoding on Length Generalization in Transformers. https://arxiv.org/abs/2305.19466
- Khatri, D., Madaan, L., Tiwari, R., Bansal, R., Duvvuri, S. S., Zaheer, M., Dhillon, I. S., Brandfonbrener, D., & Agarwal, R. (2025). The Art of Scaling Reinforcement Learning Compute for LLMs. https://arxiv.org/abs/2510.13786 back: 1, 2
- Kingma, D. P. (2014). Adam: A method for stochastic optimization. arXiv Preprint arXiv:1412.6980.
- Lambert, N., Castricato, L., von Werra, L., & Havrilla, A. (2022). Illustrating Reinforcement Learning from Human Feedback (RLHF). Hugging Face Blog.
- Lambert, N., Morrison, J., Pyatkin, V., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V., Liu, A., Dziri, N., Lyu, S., Gu, Y., Malik, S., Graf, V., Hwang, J. D., Yang, J., Bras, R. L., Tafjord, O., Wilhelm, C., Soldaini, L., … Hajishirzi, H. (2025). Tulu 3: Pushing Frontiers in Open Language Model Post-Training. https://arxiv.org/abs/2411.15124
- Lanchantin, J., Chen, A., Lan, J., Li, X., Saha, S., Wang, T., Xu, J., Yu, P., Yuan, W., Weston, J. E., Sukhbaatar, S., & Kulikov, I. (2025). Bridging Offline and Online Reinforcement Learning for LLMs. https://arxiv.org/abs/2506.21495
- Li, J., Fang, A., Smyrnis, G., Ivgi, M., Jordan, M., Gadre, S., Bansal, H., Guha, E., Keh, S., Arora, K., Garg, S., Xin, R., Muennighoff, N., Heckel, R., Mercat, J., Chen, M., Gururangan, S., Wortsman, M., Albalak, A., … Shankar, V. (2025). DataComp-LM: In search of the next generation of training sets for language models. https://arxiv.org/abs/2406.11794
- Li, Q., Cui, L., Zhao, X., Kong, L., & Bi, W. (2024). GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers. https://arxiv.org/abs/2402.19255
- Li, R., Allal, L. B., Zi, Y., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., Li, J., Chim, J., Liu, Q., Zheltonozhskii, E., Zhuo, T. Y., Wang, T., Dehaene, O., Davaadorj, M., Lamy-Poirier, J., Monteiro, J., Shliazhko, O., … de Vries, H. (2023). StarCoder: may the source be with you! https://arxiv.org/abs/2305.06161
- Li, T., Chiang, W.-L., Frick, E., Dunlap, L., Wu, T., Zhu, B., Gonzalez, J. E., & Stoica, I. (2024). From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline. https://arxiv.org/abs/2406.11939
- Liang, W., Liu, T., Wright, L., Constable, W., Gu, A., Huang, C.-C., Zhang, I., Feng, W., Huang, H., Wang, J., Purandare, S., Nadathur, G., & Idreos, S. (2025). TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training. https://arxiv.org/abs/2410.06511
- Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., & Cobbe, K. (2023). Let’s Verify Step by Step. https://arxiv.org/abs/2305.20050
- Liu, H., Xie, S. M., Li, Z., & Ma, T. (2022). Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models. https://arxiv.org/abs/2210.14199
- Liu, Q., Zheng, X., Muennighoff, N., Zeng, G., Dou, L., Pang, T., Jiang, J., & Lin, M. (2025). RegMix: Data Mixture as Regression for Language Model Pre-training. https://arxiv.org/abs/2407.01492
- Liu, Z., Zhao, C., Iandola, F., Lai, C., Tian, Y., Fedorov, I., Xiong, Y., Chang, E., Shi, Y., Krishnamoorthi, R., Lai, L., & Chandra, V. (2024). MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases. https://arxiv.org/abs/2402.14905
- Loshchilov, I., & Hutter, F. (2017). SGDR: Stochastic Gradient Descent with Warm Restarts. https://arxiv.org/abs/1608.03983
- Lozhkov, A., Li, R., Allal, L. B., Cassano, F., Lamy-Poirier, J., Tazi, N., Tang, A., Pykhtar, D., Liu, J., Wei, Y., Liu, T., Tian, M., Kocetkov, D., Zucker, A., Belkada, Y., Wang, Z., Liu, Q., Abulkhanov, D., Paul, I., … de Vries, H. (2024). StarCoder 2 and The Stack v2: The Next Generation. https://arxiv.org/abs/2402.19173
- Mao, H. H. (2022). Fine-Tuning Pre-trained Transformers into Decaying Fast Weights. https://arxiv.org/abs/2210.04243
- Marafioti, A., Zohar, O., Farré, M., Noyan, M., Bakouch, E., Cuenca, P., Zakka, C., Allal, L. B., Lozhkov, A., Tazi, N., Srivastav, V., Lochner, J., Larcher, H., Morlon, M., Tunstall, L., von Werra, L., & Wolf, T. (2025). SmolVLM: Redefining small and efficient multimodal models. https://arxiv.org/abs/2504.05299
- McCandlish, S., Kaplan, J., Amodei, D., & Team, O. D. (2018). An Empirical Model of Large-Batch Training. https://arxiv.org/abs/1812.06162
- Merrill, W., Arora, S., Groeneveld, D., & Hajishirzi, H. (2025). Critical Batch Size Revisited: A Simple Empirical Approach to Large-Batch Language Model Training. https://arxiv.org/abs/2505.23971
- Meta AI. (2025). The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence/ back: 1, 2
- Mindermann, S., Brauner, J., Razzak, M., Sharma, M., Kirsch, A., Xu, W., Höltgen, B., Gomez, A. N., Morisot, A., Farquhar, S., & Gal, Y. (2022). Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt. https://arxiv.org/abs/2206.07137
- MiniMax, Li, A., Gong, B., Yang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., Jiao, E., Li, G., Zhang, G., Sun, H., Dong, H., Zhu, J., Zhuang, J., Song, J., … Wu, Z. (2025). MiniMax-01: Scaling Foundation Models with Lightning Attention. https://arxiv.org/abs/2501.08313 back: 1, 2, 3
- Mistral AI. (2025). Mistral Small 3.1. https://mistral.ai/news/mistral-small-3-1
- Moshkov, I., Hanley, D., Sorokin, I., Toshniwal, S., Henkel, C., Schifferer, B., Du, W., & Gitman, I. (2025). AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset. https://arxiv.org/abs/2504.16891
- Muennighoff, N., Rush, A. M., Barak, B., Scao, T. L., Piktus, A., Tazi, N., Pyysalo, S., Wolf, T., & Raffel, C. (2025). Scaling Data-Constrained Language Models. https://arxiv.org/abs/2305.16264
- Ni, J., Xue, F., Yue, X., Deng, Y., Shah, M., Jain, K., Neubig, G., & You, Y. (2024). MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures. https://arxiv.org/abs/2406.06565
- Nrusimha, A., Brandon, W., Mishra, M., Shen, Y., Panda, R., Ragan-Kelley, J., & Kim, Y. (2025). FlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference. https://arxiv.org/abs/2505.22758
- Nvidia, :, Adler, B., Agarwal, N., Aithal, A., Anh, D. H., Bhattacharya, P., Brundyn, A., Casper, J., Catanzaro, B., Clay, S., Cohen, J., Das, S., Dattagupta, A., Delalleau, O., Derczynski, L., Dong, Y., Egert, D., Evans, E., … Zhu, C. (2024). Nemotron-4 340B Technical Report. https://arxiv.org/abs/2406.11704
- NVIDIA, :, Basant, A., Khairnar, A., Paithankar, A., Khattar, A., Renduchintala, A., Malte, A., Bercovich, A., Hazare, A., Rico, A., Ficek, A., Kondratenko, A., Shaposhnikov, A., Bukharin, A., Taghibakhshi, A., Barton, A., Mahabaleshwarkar, A. S., Shen, A., … Chen, Z. (2025). NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model. https://arxiv.org/abs/2508.14444
- NVIDIA, :, Blakeman, A., Basant, A., Khattar, A., Renduchintala, A., Bercovich, A., Ficek, A., Bjorlin, A., Taghibakhshi, A., Deshmukh, A. S., Mahabaleshwarkar, A. S., Tao, A., Shors, A., Aithal, A., Poojary, A., Dattagupta, A., Buddharaju, B., Chen, B., … Chen, Z. (2025). Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models. https://arxiv.org/abs/2504.03624
- OLMo, T., Walsh, P., Soldaini, L., Groeneveld, D., Lo, K., Arora, S., Bhagia, A., Gu, Y., Huang, S., Jordan, M., Lambert, N., Schwenk, D., Tafjord, O., Anderson, T., Atkinson, D., Brahman, F., Clark, C., Dasigi, P., Dziri, N., … Hajishirzi, H. (2025). 2 OLMo 2 Furious. https://arxiv.org/abs/2501.00656 back: 1, 2, 3
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., … Zoph, B. (2024). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. https://arxiv.org/abs/2203.02155
- Penedo, G., Kydlíček, H., allal, L. B., Lozhkov, A., Mitchell, M., Raffel, C., Werra, L. V., & Wolf, T. (2024). The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. https://arxiv.org/abs/2406.17557
- Penedo, G., Kydlíček, H., Sabolčec, V., Messmer, B., Foroutan, N., Kargaran, A. H., Raffel, C., Jaggi, M., Werra, L. V., & Wolf, T. (2025). FineWeb2: One Pipeline to Scale Them All – Adapting Pre-Training Data Processing to Every Language. https://arxiv.org/abs/2506.20920 back: 1, 2
- Peng, B., Goldstein, D., Anthony, Q., Albalak, A., Alcaide, E., Biderman, S., Cheah, E., Du, X., Ferdinan, T., Hou, H., Kazienko, P., GV, K. K., Kocoń, J., Koptyra, B., Krishna, S., Jr., R. M., Lin, J., Muennighoff, N., Obeid, F., … Zhu, R.-J. (2024). Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence. https://arxiv.org/abs/2404.05892
- Peng, B., Quesnelle, J., Fan, H., & Shippole, E. (2023). YaRN: Efficient Context Window Extension of Large Language Models. https://arxiv.org/abs/2309.00071 back: 1, 2
- Peng, H., Pappas, N., Yogatama, D., Schwartz, R., Smith, N. A., & Kong, L. (2021). Random Feature Attention. https://arxiv.org/abs/2103.02143
- Petty, J., van Steenkiste, S., Dasgupta, I., Sha, F., Garrette, D., & Linzen, T. (2024). The Impact of Depth on Compositional Generalization in Transformer Language Models. https://arxiv.org/abs/2310.19956
- Polo, F. M., Weber, L., Choshen, L., Sun, Y., Xu, G., & Yurochkin, M. (2024). tinyBenchmarks: evaluating LLMs with fewer examples. https://arxiv.org/abs/2402.14992
- Press, O., Smith, N. A., & Lewis, M. (2022). Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. https://arxiv.org/abs/2108.12409
- Pyatkin, V., Malik, S., Graf, V., Ivison, H., Huang, S., Dasigi, P., Lambert, N., & Hajishirzi, H. (2025). Generalizing Verifiable Instruction Following. https://arxiv.org/abs/2507.02833
- Qin, Z., Han, X., Sun, W., Li, D., Kong, L., Barnes, N., & Zhong, Y. (2022). The Devil in Linear Transformer. https://arxiv.org/abs/2210.10340
- Qin, Z., Yang, S., Sun, W., Shen, X., Li, D., Sun, W., & Zhong, Y. (2024). HGRN2: Gated Linear RNNs with State Expansion. https://arxiv.org/abs/2404.07904
- Qiu, Z., Huang, Z., Zheng, B., Wen, K., Wang, Z., Men, R., Titov, I., Liu, D., Zhou, J., & Lin, J. (2025). Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models. https://arxiv.org/abs/2501.11873
- Qwen Team. (2025). Qwen3-Next: Towards Ultimate Training & Inference Efficiency. Alibaba Cloud. https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., & others. (2019). Language models are unsupervised multitask learners. In OpenAI blog (Vol. 1, p. 9).
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2024). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. https://arxiv.org/abs/2305.18290
- Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., & Bowman, S. R. (2024). Gpqa: A graduate-level google-proof q&a benchmark. First Conference on Language Modeling.
- Rozière, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., Rapin, J., Kozhevnikov, A., Evtimov, I., Bitton, J., Bhatt, M., Ferrer, C. C., Grattafiori, A., Xiong, W., Défossez, A., … Synnaeve, G. (2024). Code Llama: Open Foundation Models for Code. https://arxiv.org/abs/2308.12950
- Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units. https://arxiv.org/abs/1508.07909
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. https://arxiv.org/abs/2402.03300
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. https://arxiv.org/abs/1911.02150
- Shi, F., Suzgun, M., Freitag, M., Wang, X., Srivats, S., Vosoughi, S., Chung, H. W., Tay, Y., Ruder, S., Zhou, D., Das, D., & Wei, J. (2022). Language Models are Multilingual Chain-of-Thought Reasoners. https://arxiv.org/abs/2210.03057
- Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zouitine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., Alibert, S., Cord, M., Wolf, T., & Cadene, R. (2025). SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. https://arxiv.org/abs/2506.01844
- Singh, S., Romanou, A., Fourrier, C., Adelani, D. I., Ngui, J. G., Vila-Suero, D., Limkonchotiwat, P., Marchisio, K., Leong, W. Q., Susanto, Y., Ng, R., Longpre, S., Ko, W.-Y., Ruder, S., Smith, M., Bosselut, A., Oh, A., Martins, A. F. T., Choshen, L., … Hooker, S. (2025). Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation. https://arxiv.org/abs/2412.03304
- Sirdeshmukh, V., Deshpande, K., Mols, J., Jin, L., Cardona, E.-Y., Lee, D., Kritz, J., Primack, W., Yue, S., & Xing, C. (2025). MultiChallenge: A Realistic Multi-Turn Conversation Evaluation Benchmark Challenging to Frontier LLMs. https://arxiv.org/abs/2501.17399
- Smith, L. N., & Topin, N. (2018). Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. https://arxiv.org/abs/1708.07120
- Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., & Liu, Y. (2023). RoFormer: Enhanced Transformer with Rotary Position Embedding. https://arxiv.org/abs/2104.09864
- Sun, Y., Dong, L., Zhu, Y., Huang, S., Wang, W., Ma, S., Zhang, Q., Wang, J., & Wei, F. (2024). You Only Cache Once: Decoder-Decoder Architectures for Language Models. https://arxiv.org/abs/2405.05254
- Takase, S., Kiyono, S., Kobayashi, S., & Suzuki, J. (2025). Spike No More: Stabilizing the Pre-training of Large Language Models. https://arxiv.org/abs/2312.16903
- Team, 5, Zeng, A., Lv, X., Zheng, Q., Hou, Z., Chen, B., Xie, C., Wang, C., Yin, D., Zeng, H., Zhang, J., Wang, K., Zhong, L., Liu, M., Lu, R., Cao, S., Zhang, X., Huang, X., Wei, Y., … Tang, J. (2025). GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models. https://arxiv.org/abs/2508.06471
- team, F. C., Copet, J., Carbonneaux, Q., Cohen, G., Gehring, J., Kahn, J., Kossen, J., Kreuk, F., McMilin, E., Meyer, M., Wei, Y., Zhang, D., Zheng, K., Armengol-Estapé, J., Bashiri, P., Beck, M., Chambon, P., Charnalia, A., Cummins, C., … Synnaeve, G. (2025). CWM: An Open-Weights LLM for Research on Code Generation with World Models. https://arxiv.org/abs/2510.02387
- Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, G., bastien Jean-Grill, Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., … Hussenot, L. (2025). Gemma 3 Technical Report. https://arxiv.org/abs/2503.19786
- Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., Chen, Z., Cui, J., Ding, H., Dong, M., Du, A., Du, C., Du, D., Du, Y., Fan, Y., … Zu, X. (2025). Kimi K2: Open Agentic Intelligence. https://arxiv.org/abs/2507.20534 back: 1, 2, 3
- Team, L., Han, B., Tang, C., Liang, C., Zhang, D., Yuan, F., Zhu, F., Gao, J., Hu, J., Li, L., Li, M., Zhang, M., Jiang, P., Jiao, P., Zhao, Q., Yang, Q., Shen, W., Yang, X., Zhang, Y., … Zhou, J. (2025). Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning. https://arxiv.org/abs/2510.19338
- Team, L., Zeng, B., Huang, C., Zhang, C., Tian, C., Chen, C., Jin, D., Yu, F., Zhu, F., Yuan, F., Wang, F., Wang, G., Zhai, G., Zhang, H., Li, H., Zhou, J., Liu, J., Fang, J., Ou, J., … He, Z. (2025). Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs. https://arxiv.org/abs/2503.05139
- Team, M., Xiao, C., Li, Y., Han, X., Bai, Y., Cai, J., Chen, H., Chen, W., Cong, X., Cui, G., Ding, N., Fan, S., Fang, Y., Fu, Z., Guan, W., Guan, Y., Guo, J., Han, Y., He, B., … Sun, M. (2025). MiniCPM4: Ultra-Efficient LLMs on End Devices. https://arxiv.org/abs/2506.07900
- Tian, C., Chen, K., Liu, J., Liu, Z., Zhang, Z., & Zhou, J. (2025). Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models. https://arxiv.org/abs/2507.17702 back: 1, 2, 3
- Toshniwal, S., Moshkov, I., Narenthiran, S., Gitman, D., Jia, F., & Gitman, I. (2024). OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset. https://arxiv.org/abs/2402.10176
- Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., von Werra, L., Fourrier, C., Habib, N., Sarrazin, N., Sanseviero, O., Rush, A. M., & Wolf, T. (2023). Zephyr: Direct Distillation of LM Alignment. https://arxiv.org/abs/2310.16944
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need. https://arxiv.org/abs/1706.03762 back: 1, 2, 3
- Waleffe, R., Byeon, W., Riach, D., Norick, B., Korthikanti, V., Dao, T., Gu, A., Hatamizadeh, A., Singh, S., Narayanan, D., Kulshreshtha, G., Singh, V., Casper, J., Kautz, J., Shoeybi, M., & Catanzaro, B. (2024). An Empirical Study of Mamba-based Language Models. https://arxiv.org/abs/2406.07887
- Wang, B., & Komatsuzaki, A. (2021). GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax
- Wei, J., Karina, N., Chung, H. W., Jiao, Y. J., Papay, S., Glaese, A., Schulman, J., & Fedus, W. (2024). Measuring short-form factuality in large language models. arXiv Preprint arXiv:2411.04368.
- Wen, K., Hall, D., Ma, T., & Liang, P. (2025). Fantastic Pretraining Optimizers and Where to Find Them. https://arxiv.org/abs/2509.02046 back: 1, 2
- Xie, S. M., Pham, H., Dong, X., Du, N., Liu, H., Lu, Y., Liang, P., Le, Q. V., Ma, T., & Yu, A. W. (2023). DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining. https://arxiv.org/abs/2305.10429
- Xiong, W., Liu, J., Molybog, I., Zhang, H., Bhargava, P., Hou, R., Martin, L., Rungta, R., Sankararaman, K. A., Oguz, B., Khabsa, M., Fang, H., Mehdad, Y., Narang, S., Malik, K., Fan, A., Bhosale, S., Edunov, S., Lewis, M., … Ma, H. (2023a). Effective Long-Context Scaling of Foundation Models. https://arxiv.org/abs/2309.16039
- Xiong, W., Liu, J., Molybog, I., Zhang, H., Bhargava, P., Hou, R., Martin, L., Rungta, R., Sankararaman, K. A., Oguz, B., Khabsa, M., Fang, H., Mehdad, Y., Narang, S., Malik, K., Fan, A., Bhosale, S., Edunov, S., Lewis, M., … Ma, H. (2023b). Effective Long-Context Scaling of Foundation Models. https://arxiv.org/abs/2309.16039
- Xu, H., Peng, B., Awadalla, H., Chen, D., Chen, Y.-C., Gao, M., Kim, Y. J., Li, Y., Ren, L., Shen, Y., Wang, S., Xu, W., Gao, J., & Chen, W. (2025). Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math. https://arxiv.org/abs/2504.21233
- Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., … Qiu, Z. (2025). Qwen3 Technical Report. https://arxiv.org/abs/2505.09388 back: 1, 2, 3
- Yang, A., Yu, B., Li, C., Liu, D., Huang, F., Huang, H., Jiang, J., Tu, J., Zhang, J., Zhou, J., Lin, J., Dang, K., Yang, K., Yu, L., Li, M., Sun, M., Zhu, Q., Men, R., He, T., … Zhang, Z. (2025). Qwen2.5-1M Technical Report. https://arxiv.org/abs/2501.15383 back: 1, 2
- Yang, G., & Hu, E. J. (2022). Feature Learning in Infinite-Width Neural Networks. https://arxiv.org/abs/2011.14522
- Yen, H., Gao, T., Hou, M., Ding, K., Fleischer, D., Izsak, P., Wasserblat, M., & Chen, D. (2025). HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly. https://arxiv.org/abs/2410.02694 back: 1, 2
- Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., Liu, X., Lin, H., Lin, Z., Ma, B., Sheng, G., Tong, Y., Zhang, C., Zhang, M., Zhang, W., … Wang, M. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. https://arxiv.org/abs/2503.14476
- Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y. X., Wang, L., Xiao, Z., Wang, Y., Ruan, C., Zhang, M., Liang, W., & Zeng, W. (2025). Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. https://arxiv.org/abs/2502.11089
- Yue, Y., Chen, Z., Lu, R., Zhao, A., Wang, Z., Yue, Y., Song, S., & Huang, G. (2025). Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? https://arxiv.org/abs/2504.13837
- Zhou, F., Wang, Z., Ranjan, N., Cheng, Z., Tang, L., He, G., Liu, Z., & Xing, E. P. (2025). MegaMath: Pushing the Limits of Open Math Corpora. https://arxiv.org/abs/2504.02807
- Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., & Hou, L. (2023). Instruction-Following Evaluation for Large Language Models. https://arxiv.org/abs/2311.07911
- Zhu, T., Liu, Q., Wang, H., Chen, S., Gu, X., Pang, T., & Kan, M.-Y. (2025). SkyLadder: Better and Faster Pretraining via Context Window Scheduling. https://arxiv.org/abs/2503.15450 back: 1, 2
- Zuo, J., Velikanov, M., Chahed, I., Belkada, Y., Rhayem, D. E., Kunsch, G., Hacid, H., Yous, H., Farhat, B., Khadraoui, I., Farooq, M., Campesan, G., Cojocaru, R., Djilali, Y., Hu, S., Chaabane, I., Khanna, P., Seddik, M. E. A., Huynh, N. D., … Frikha, S. (2025). Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance. https://arxiv.org/abs/2507.22448 back: 1, 2